
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- deep learning 논문 리뷰
- cvpr 논문 리뷰
- Stable Diffusion
- active learning
- Data-centric
- iclr 논문 리뷰
- CVPR
- 논문리뷰
- Segment Anything
- Data-centric AI
- cvpr 2024
- iclr 2024
- Segment Anything 리뷰
- Computer Vision 논문 리뷰
- contrastive learning
- deep learning
- 자기지도학습
- Computer Vision
- iclr spotlight
- Prompt란
- Prompt Tuning
- Meta AI
- VLM
- 논문 리뷰
- Segment Anything 설명
- ICLR
- Self-supervised learning
- ai 최신 논문
- ssl
- Multi-modal
- Today
- Total
Study With Inha
[Paper Review] CVPR 2024 Highlight Paper, Adapting Visual-Language Models for Generalizable Anomaly Detection in Medical Images 논문 리뷰 본문
[Paper Review] CVPR 2024 Highlight Paper, Adapting Visual-Language Models for Generalizable Anomaly Detection in Medical Images 논문 리뷰
강이나 2024. 6. 25. 19:05CVPR 2024 Highlight Paper, Adapting Visual-Language Models
for Generalizable Anomaly Detection in Medical Images 논문 리뷰
Paper Link: https://arxiv.org/pdf/2403.12570
GitHub Link: https://github.com/MediaBrain-SJTU/MVFA-AD
1. Introduction
여러가지 Modality를 하나의 모델로 다루는 연구가 지속됨에 따라서, 최근 Visual-Language Model (VLM)이 괄목할만한 성능을 보이고 있다.
하지만 CLIP을 포함한 대부분의 VLM은 대용량의 Natural image들로 pretrain되었기에, Domain Gap이나 Task Gap이 큰 분야에 대해서는 좋은 성능을 보이지 못했다.
그 중에서도 Medical Image 분야의 Anomaly Detection Task의 경우 주어진 의료 이미지가 의학적으로 'Normal (정상)'인지 'Abnormal (비정상)'인지 판별하고 문제가 있을 경우 그 영역까지 찾아내는 것을 목표로 하기 때문에, Image의 Semantic 정보를 알 수 있도록 학습된 VLM 모델과 특히나 많은 차이가 있다.
이처럼 Natural Image로 사전 훈련된 모델을 Medical Image에서 사용할 경우, Task 및 Domain에서 많은 차이가 존재하기 때문에 제대로 된 성능을 내지 못하는 경우가 많았다.

본 논문에서는 Medical Image Anomaly Detection 분야에서 Natural Image로 사전 학습된 CLIP 모델을 활용하여 성능을 높일 수 있는 새로운 방법에 대해서 제안하고 있다.
특히 잘 Generalize된 Anomaly Detection (AD) 모델을 개발하여 Medical Image의 다양한 Modality에서 높은 성능을 낼 수 있도록 했다.
본 논문에서 제안하는 방법론과 그에 따른 Contribution은 아래와 같다.
- CLIP 모델을 Medical Image Anomaly Detection에 맞게 재구성 하기 위해서 Multi-level Adaptation and Comparison Framework를 도입함. 이는 natural image로 pretrain된 VLM 모델의 Vision Encoder에 있는 여러 개의 residual adapter들을 통합하여 multi-level feature들을 활용할 수 있도록 하기 위함임.
- 다양한 level의 feature들을 활용하기 위해서 Multi-level, Pixel-wise Visual-Language Feature들을 관장할 수 있는 Loss Function을 활용함. 이는 모델의 초점을 자연 이미지의 객체 의미에서 의료 이미지의 AD로 guide하는 역할을 하게 됨.
- 본 연구는 일반화 가능한 의료 이상 탐지 모델을 개발하여 다양한 의료 데이터 유형에서 개선된 일반화를 보여줌. 특히, 제안된 방법은 다양한 modality(brain MRI, liver CT, retinal OCT, chest Xray, and digital histopathology)의 zero-/few-shot 시나리오에서 현재의 최신 모델들을 능가함.
2. Related Works
Medical Anomaly Detection
Medical Image Anomaly Detection은 주어진 Medical Image가 Normal인지 Abnormal인지 판별하고, 문제가 있을 경우 해당 영역까지 localization 해주는 것을 목표로 하는 task다.
따라서 하나의 모델이 아래와 같은 두 가지 task를 수행할 수 있어야 한다.
- Sample-level Analysis (Classification): 주어진 이미지가 Normal인지, Abnormal인지 Binary Classification 수행
- Piexel(Voxel)-level Analysis (Segmentation): 주어진 이미지에 Abnormal 영역이 존재할 경우, Localization 수행
이 때, 주의할 점은 Training Data에는 Abnormal과 관련된 데이터가 제한적이라는 점이다.
full-normal shot의 경우 Normal Data만으로 학습시킨 후, 실제 Test에서는 Normal 및 다양한 Abnormal에 대한 판별을 진행하게 된다.
이를 통해 특정 Disease에 국한되지 않는 보조 진단 도구로 활용되어 오진을 줄일 수 있도록 한다.
few-normal shot의 경우 full-normal-shot보다 조금 더 제한적인 상황으로, 적은 수의 Normal Data로만 학습하는 방법이다.
마지막으로, 본 논문에서 제안하는 few-shot의 경우에는 적은 수의 Normal Data와 적은 수의 Abnormal Dataset으로 학습시키는 환경을 뜻하며,
이는 학습 데이터 수 자체가 적은 경우 사용할 수 있는 Anomaly Detection Task이다.


3. Problem Formulation

본 논문은 Natural Image로 학습된 모델을 Medical Image의 AD를 수행할 수 있는 Model로 변환하는 것을 목표로 한다.
논문에서 사용되는 용어의 Notation은 아래와 같다.
- $M_{nat}$: initially trained on natural images
- $M_{med}$: medically adapted model
- $D_{med}$: medical training dataset, which consists of annotated samples from the medical field. it is defined as a set of tuples ${(x_i , c_i , S_i)}^{K}_{i=1}$
- $K$: the total number of image samples in the dataset
- pre-training dataset that is composed of medical data from different modalities and anatomical regions than those in the test samples, which assesses the model’s generalization to unseen scenarios.
- includes a small collection of K annotated images that are of the same modality and anatomical region as those in the test samples, with $K$ typically representing a small numerical value, such as {2, 4, 8, 16} in this study.
- $x_i$: a training image
- $c_i$: image-level anomaly classification (AC) label $c_i \in \{−, +\}$.
- '+' indicates anomalous samples
- '-' indicates normal samples.
- $S_i$: pixel-level anomaly segmentation (AS) annotations $S_i \in \{−, +\}^{h \times w}$ for images of size h × w
- $x_{test}$: a given test image. the model aims to accurately predict both image-level and pixel-level anomalies for AC and AS, respectively.
4. Train: Multi-Level Feature Adaptation

4.1. Multi-level Visual Feature Adapter (MVFA)
의료 영상의 이상 탐지(Anomaly Detection, AD)를 위해 사전 학습된 Natural Image Visual-Language Model(CLIP)을 활용하는 Multi-level Visual Feature Adaptation 프레임워크의 핵심 구성 요소이다.
의료 영상에서 거대한 모델을 활용하는 경우, 거대한 수의 파라미터에 비해 학습 데이터의 수가 적기 때문에 Overfitting이 발생하는 경우가 많았다.
따라서 MVFA는 Overfitting을 방지하고 Training Sample의 수가 제한된 상황에서 높은 성능을 유지하기 위해 설계되었다.
이를 위해 CLIP 모델의 residual adapter에 적은 수의 학습 가능한 Learnable Bottleneck Linear Layers을 추가하여 Multi-level Feature를 활용할 수 있도록 했다.
이 방법은 기존의 CLIP Backbone을 변경하지 않고도 높은 성능을 낼 수 있도록 했다.
- $S_1$ to $S_4$: CLIP의 4개의 sequential stages
- $F_l$, $l \in {1, 2, 3}$: $S_l$를 거친 middle stage features
- $A_l$, $l \in {1, 2, 3}$: learnable feature adapter
- $P$: feature projector
- $feature$ $adaptation$: 3 adaptors ($A_l$) + 1 projector ($P$)
여기서 feature adaptor $A_l$은 middle stage feature $F_l$에 최소 두 개 이상의 trainable linear transformation layer $W_{l,1}$, $W_{l,2}$를 통과시키게 된다.

이를 residual ratio값 $\gamma$를 적용하여 기존 middel stage feature 값과 더해주면 $l$-th feature level에서의 feature adaptor $F_{l}^{*}$를 구할 수 있다.
(by default, $\gamma$ = 0.1)

이 때, AC(anomaly classification)를 위한 global feature와 AS(anomaly segmentation)를 위한 local feature를 동시에 다루기 위해서
아래와 같이 Eq(1)과 같은 feature adaptor를 parallel한 dual-architecture 형태로 적용시켰다.

최종적으로 CLIP encoder의 output인 $F_{vis}$는 linear layer로 구성된 feature projector $P$를 통과하게 된다.
$P$는 cls과 seg를 위해서 $W_{cls}$, $W_{seg}$로 구성되어 있어 global feature와 local feature는 아래와 같이 표현될 수 있다.
- global feature (for AC): $F_{cls, 4}$ = $F^T_{vis}W_{cls}$
- local feature (for AS): $F_{seg, 4}$ = $F^T_{vis}W_{seg}$
이와 같이 CLIP 모델의 visual-language alignment를 수행한 multi-level adapted feature를 통해서 local feature와 global feature를 동시에 다루며 AC와 AS를 수행할 수 있었다.
4.2. Language Feature Formatting.
CLIP이 대규모 Visual Language Model이기 때문에, 위 모델에서도 normal과 anomal 이미지에 관련된 text prompt를 활용했다.
복잡한 디테일에 관련된 text prompt보다는 명료한 text prompt를 주려고 했고,
그 결과 아래와 같은 35개의 text prompt template을 활용하여 학습했다고 한다.

text prompt가 text encoder를 통과한 후의 feature들을 normal인지 anomaly인지 분간하여 합쳐주었고,
이를 따로 평균내어 주면 normal과 anomaly의 text feature를 각각 얻을 수 있었다.
- $F_{text} \in R^{2 \times d}$ where $d$ is the feature dimension
4.3. Visual-Language Feature Alignment.
AC를 위한 image level annotation($c \in \{+, -\}$)과
AS를 위한 pixel level anomaly map($S \in \{+, -\}^{h \times w}$)를
각 feature level ($l \in \{1, 2, 3, 4\}$)마다 MVFA와 text feature들 간의 alignment를 맞춰주며 모델을 optimize해 주어야 한다.

여기서 $\lambda$ 값은 모두 1.0으로 동일하게 설정했다.
최종 loss인 $L_{adapt}$는 모든 level에서의 $L_l$를 합산한 값이 된다.
4.4. Discussion.
이전에 연구된 WinCLIP이라는 모델은 pre-trained VLM의 class token만을 활용한 반면에,
여기서 제시된 MVFA는 각 level마다 multi-level adaptation을 도입하여 visual-language alignment를 수행했다.
그 결과 이전에 연구되었던 APRIL-GAN은 projection된 이후의 feature만 alignment을 맞추어주었는데,
MVFA는 중간 level들에 대한 feature에서도 alignment를 맞춰주어 medical anomaly detection에서 generalization을 잘 이뤄낸 robust한 결과를 낼 수 있도록 했다.
5. Test: Multi-Level Feature Comparision
AC와 AS를 동시에 수행하기 위해서 test 시에는 zero-shot branch와 few-shot branch를 거치게 된다.

5.1. Zero-shot Branch
test image $x_{test}$가 MVFA를 거치게 되면 multi-level adapted feature가 나오게 된다.
그 후에는 training 시에 normal과 anormal text prompt들에 대한 feature들을 각각 저장해 둔 $F_{text}$와 비교하게 된다.
최종적으로 zero-shot의 AC 결과($c_{zero}$)와 AS 결과($S_{zero}$)는 아래와 같이
각 level마다 나오는 결과들에 대해서 average softmax를 취하여 얻을 수 있게 된다.

5.2. Few-shot Branch
Training Dataset $D_{med}$에 포함되어 있는 labeled normal image들의 multi-level visual feature들은 Feature Memory Bank $\mathcal{G}$에 포함되게 된다.
따라서 Few-shot AC($c_{few}$)와 AS($S_{few}$) score는 아래 식에서와 같이
feature memory bank $\mathcal{G}$와 test image에서 추출한 multi-level adapted feature 간의 distance를 계산하여 얻을 수 있게 된다.

최종적으로 test 시의 AC($c_{pred}$)와 AS($S_{pred}$)는 zero-shot branch와 few-shot branch의 결과를 평균내어 구하게 된다.

6. Experiments
6.1. Experimental Setups
Dataset
아래와 같은 5개의 medical domain의 6개 dataset에 대해서 실험 진행함

Evaluation
- all-normal (vanilla method): training dataset에 있는 normal image들만 모두 사용하여 학습함
- few-normal-shot: 적은 수의 normal image만 사용하여 학습함
- few-shot: 적은 수의 normal image와 적은 수의 anomaly image를 활용하여 학습함
평가는 The area under the Receiver Operating Characteristic curve metric(AUC) Metric을 통해 평가되었다

- Definition:
- AUC is the area under the ROC curve. It provides an aggregate measure of performance across all possible classification thresholds.
- The value of AUC ranges from 0 to 1. The higher the AUC, the better the model is at distinguishing between positive and negative classes.
- Interpretation:
- AUC = 1: Perfect model. The classifier can perfectly distinguish between all positive and negative instances.
- AUC = 0.5: No discrimination capability. The model's predictions are no better than random guessing.
- AUC < 0.5: Worse than random. This typically indicates a problem with the model as it is incorrectly classifying the instances more often than not.
Model Configuration and Training Details
- 모델 아키텍처: CLIP with ViT-L/14
- 이미지 해상도: 240
- 레이어 수: 총 24개의 레이어를 6개의 레이어로 구성된 4 Stage로 나눔
- Optimizer : Adam
- Learning Rate : 1e-3
- Batch Size : 16
- Training Epoch : 50 Epoch
- GPU : NVIDIA GeForce RTX 3090 사용
6.2. Comparison with State-of-the-art Methods
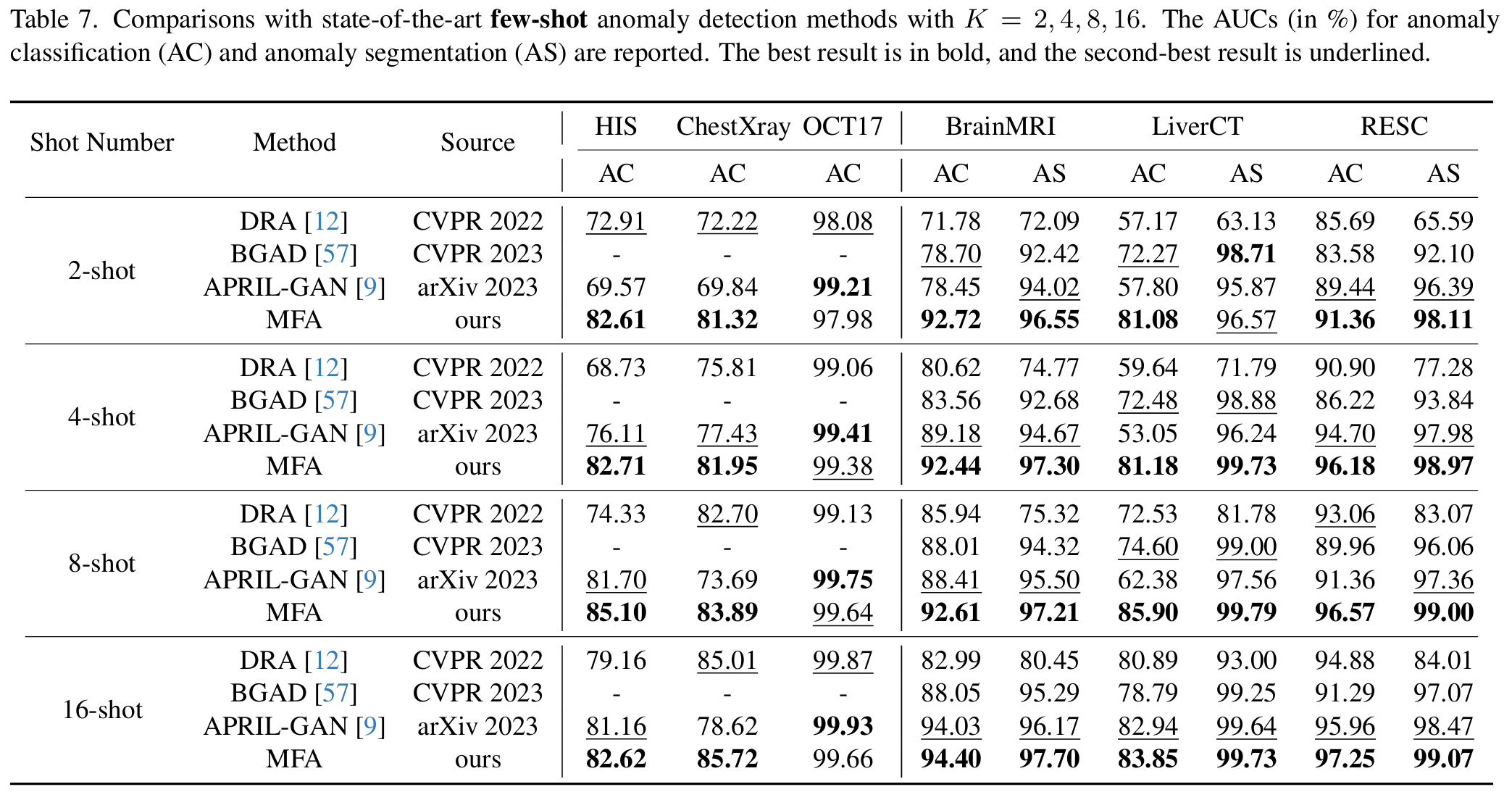
아래 표에서는 K=4일 때의 few-shot 환경에서 실험한 결과를 보이고 있다.
(K는 학습시 사용된 이미지의 개수. 즉 K=4일 경우 normal 4장과 abnormal 4장이 사용됨)


위 결과에서 볼 수 있듯이 few-shot에서는 가장 좋은 성능을 보였고, 다른 setting과 비교했을 때도 우수한 성능을 보이고 있음을 알 수 있다.
full-normal-shot에서는 대용량의 normal dataset이 사용되는데, MVFA의 경우 이보다 훨씬 적은 수의 normal data만으로도 full-normal-shot setting의 결과보다 좋은 AC, AS 결과를 확인할 수 있다.
또한 K 값을 달리 했을 때도 Figure 3에서 볼 수 있듯 AS와 AC 모두 기존 SoTA 모델들에 비해 좋은 결과를 보이고 있다는 것을 실험을 통해 확인할 수 있었다.
이는 Few-shot setting에서 적은 수의 abnormal image 데이터만으로도 MVFA를 활용하여 abnormal에 대한 학습이 잘 이루어졌다는 것을 반증한다.
- 특히, MVFA는 CVPR 2023의 VAND 워크숍에서 우승한 April-GAN보다 평균 AUC(Area Under the Curve)가 AC(Anomaly Classification)에서 7.33%, AS(Anomaly Segmentation)에서 2.37% 더 높음
- BGAD와 비교했을 때, MVFA는 AC에서 평균 9.18%, AS에서 3.53% 더 나은 성능을 보임
Zero-shot 환경에서의 성능평가는 leave-one-out 설정을 기반으로 진행되었다.
Leave-one-out이란 하나의 데이터셋을 평가할 때 해당 데이터셋을 제외한 다른 모든 데이터셋으로 모델을 학습시키고, 배제된 데이터셋으로 테스트하는 방법이다.
이를 통해 학습 시 보지 못한 modality나 anatomical region에 대한 결과를 확인할 수 있으며, 이는 모델의 일반화 능력을 평가하는 데 유용하다.

위 결과를 통해서 MVFA가 zero-shot AC와 AS에서 모두 좋은 성능을 보이고 있다는 것을 알 수 있다.
또한 MVTec이라는 산업용 Anomaly Detection 데이터셋에 대해서 in-domain evaluation을 실행했다.
MVFA는 in-domain evalution을 위한 모델이 아님에도 불구하고,
K=4라는 few-shot 환경에서 좋은 in-domain 성능을 보이고 있다.
이를 통해서 MVFA 모델 자체가 다양한 도메인에 적용될 수 있는 generalized model이라는 것을 뜻한다.


6.3. Ablation Studies
Feature Adaptation vs. Feature Alignment.

Feature Adapter 대신에 Projector들만 사용한 Feature Alignment 방식과
Multi-level Feature Adapter를 사용한 Feature Adaptation 방식에 대해서 비교하는 실험을 진행했다.
실험 시에 사용한 loss function은 모두 동일하며 zero-shot setting에 대해서 AC와 AS 성능을 도출했다.
그 결과 Adapter를 사용했을 때 AC와 AS 모두에서 더 높은 성능을 보였는데, 이를 통해서 multi-level feature가 model의 generalization 성능을 촉진했다는 것을 알 수 있다.

Feature Ensemble in Multi-Level.
이번에는 제 각기 다른 layer에서 나온 feature들을 통합하는 것이 얼마나 효과적인지에 대해서 두 가지 setting으로 실험했다.
- single-layer training: adaptor에서 하나의 layer만 사용하여 optimize되는 것
- multi-level training: adaptor의 다양한 layer에서 나온 feature들을 모두 사용하여 optimize하는 것

아래 표를 보면 single-layer setting에서는 Layer 2를 사용하는 것이 가장 좋은 성능을 보였다.
하지만 MVFA에서와 같이 모든 layer를 다 사용했을 때 모든 single-layer training보다 더 좋은 성능을 보이고 있다.


6.4. Visualization Analysis

AS에 대한 GT가 있는 데이터셋에 대해서 정성적 평가를 실시했다.
현재 SoTA 모델인 April-GAN과 비교해 보았을 때, MVFA가 조금 더 정교한 결과를 보이고 있음을 확인할 수 있었다.

t-SNE를 비교해 보면 Adapter의 유무에 따라서 normal과 abnormal에 대한 feature alignment가 어떻게 달라지는지 확인할 수 있었다.
Adapter가 있을 때 normal과 abnormal에 대한 decision boundary가 잘 형성되어 있는 반면에,
adapter가 없을 때는 feature가 제대로 align되지 않았다는 것을 시각적으로 확인할 수 있었다.
7. Conclusion
본 논문에서는 다양한 modality와 anatomical region에 걸쳐 일반화된 성능을 달성하기 위해 Multi-Level Feature Adaptation을 제안했다.
MVFA는 여러 층의 특징을 통합하여 모델이 입력 데이터의 복잡한 패턴을 효과적으로 학습할 수 있도록 했다.
그 결과 현존하는 SoTA 모델들과 비교했을 때 높은 AUC 성능을 보였다.
이로써 본 논문의 방법론은 의료 영상 분석에서의 모델의 성능과 일반화 능력을 효과적으로 향상시킬 수 있음을 입증했다.
#AI최신논문 #AI최신논문리뷰 #딥러닝최신논문리뷰 #컴퓨터비전최신논문



