
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- contrastive learning
- Data-centric AI
- VLM
- ai 최신 논문
- cvpr 논문 리뷰
- deep learning 논문 리뷰
- cvpr 2024
- active learning
- Segment Anything 리뷰
- Prompt란
- ssl
- Computer Vision 논문 리뷰
- Data-centric
- CVPR
- iclr 논문 리뷰
- 논문 리뷰
- iclr spotlight
- 자기지도학습
- Segment Anything
- Meta AI
- deep learning
- iclr 2024
- Multi-modal
- Computer Vision
- 논문리뷰
- Stable Diffusion
- Self-supervised learning
- Prompt Tuning
- ICLR
- Segment Anything 설명
- Today
- Total
목록Computer Vision (13)
Study With Inha
 [Paper Review] ICLR 2023 Spotlight, SparK: Designing BERT for Convolutional Networks: Sparse and Hierarchical Masked Modeling 논문 리뷰
[Paper Review] ICLR 2023 Spotlight, SparK: Designing BERT for Convolutional Networks: Sparse and Hierarchical Masked Modeling 논문 리뷰
ICLR 2023 Spotlight (notable-top-25%),(SparK) Designing BERT for Convolutional Networks: Sparse and Hierarchical Masked Modeling논문 링크: https://openreview.net/forum?id=NRxydtWup1SGitHub: https://github.com/keyu-tian/SparK Designing BERT for Convolutional Networks: Sparse and Hierarchical...This paper presents a simple yet powerful framework to pre-train convolutional network (convnet) with Sparse..
 [Paper Review] CVPR 2024 Highlight Paper, Adapting Visual-Language Models for Generalizable Anomaly Detection in Medical Images 논문 리뷰
[Paper Review] CVPR 2024 Highlight Paper, Adapting Visual-Language Models for Generalizable Anomaly Detection in Medical Images 논문 리뷰
CVPR 2024 Highlight Paper, Adapting Visual-Language Models for Generalizable Anomaly Detection in Medical Images 논문 리뷰Paper Link: https://arxiv.org/pdf/2403.12570GitHub Link: https://github.com/MediaBrain-SJTU/MVFA-AD 1. Introduction여러가지 Modality를 하나의 모델로 다루는 연구가 지속됨에 따라서, 최근 Visual-Language Model (VLM)이 괄목할만한 성능을 보이고 있다.하지만 CLIP을 포함한 대부분의 VLM은 대용량의 Natural image들로 pretrain되었기에, Domain Gap이나 Tas..
 [Paper Review] ICLR 2024, Interpreting CLIP's Image Representation via Text-Based Decomposition 논문 리뷰
[Paper Review] ICLR 2024, Interpreting CLIP's Image Representation via Text-Based Decomposition 논문 리뷰
ICLR 2024, Interpreting CLIP's Image Representation via Text-Based Decomposition 논문 링크: https://openreview.net/attachment?id=5Ca9sSzuDp&name=pdf프로젝트 페이지 링크: https://yossigandelsman.github.io/clip_decomposition/ 1. Introduction최근 많은 논문들에서 거대한 Text, Image Pair로 학습시킨 CLIP 모델을 활용하는 후속 연구들을 진행하고 있다.본 논문에서는 CLIP의 이미지 인코더를 분석하여 모델의 각 구성 요소가 final representation에 미치는 영향을 해석 가능한 텍스트로 설명하고 있다.먼저, Attentio..
 [Data-centric AI - 2편] Data-centric AI, ObjectLab: Automated Diagnosis of Mislabeled Images in Object Detection Data 논문 리뷰
[Data-centric AI - 2편] Data-centric AI, ObjectLab: Automated Diagnosis of Mislabeled Images in Object Detection Data 논문 리뷰
ObjectLab: Automated Diagnosis of Mislabeled Images in Object Detection Datahttps://arxiv.org/pdf/2309.00832.pdf 1. Introduction아래 링크의 글에서 볼 수 있듯이, 잘못된 GT를 가진 Dataset으로 학습된 모델의 경우 그 성능이 낮아질 수 있다.이를 방지하기 위해서 연구되는 분야가 Data-centric AI에서 'Data Preparation' 단계의 'Data Cleaning'이다.[Computer Vision 시리즈물 연재] - [Data-centric AI - 1편] DCAI 소개 [Data-centric AI - 1편] DCAI 소개 및 Data-centric AI: Perspectives a..
 [Paper Review] 카카오 브레인 (Kakao Brain) CVPR 2023, Learning to Generate Text-grounded Mask for Open-world Semantic Segmentation from Only Image-Text Pairs 논문 리뷰
[Paper Review] 카카오 브레인 (Kakao Brain) CVPR 2023, Learning to Generate Text-grounded Mask for Open-world Semantic Segmentation from Only Image-Text Pairs 논문 리뷰
CVPR 2023 accepted paper, TCL (Text-grounded Contrastive Learning): Learning to Generate Text-grounded Mask for Open-world Semantic Segmentation from Only Image-Text Pairs 논문링크: https://arxiv.org/abs/2212.00785 Learning to Generate Text-grounded Mask for Open-world Semantic Segmentation from Only Image-Text Pairs We tackle open-world semantic segmentation, which aims at learning to segment arbit..
 [Self-Supervised Learning 개론 - 3] Do we need labels?; Contrastive Learning부터 Deep Generative Model까지
[Self-Supervised Learning 개론 - 3] Do we need labels?; Contrastive Learning부터 Deep Generative Model까지
[Self-supervised Learning 개론 관련 이전 글] [Self-Supervised Learning 개론 - 1] [Self-Supervised Learning 개론 - 1] Do we need labels?; Contrastive Learning부터 Deep Generative Model까지 ⚽ GOAL 2020 ~ 2023 사이에 활발하게 이루어진 연구들의 개념을 알아본다 각 개념의 대표적인 논문들을 간단하게 소개하여 연구의 흐름을 알아본다 이를 통해서 본인 연구/개발에서 써 볼만한 insigh 2na-97.tistory.com [Self-Supervised Learning 개론 - 2] [Self-Supervised Learning 개론 - 2] Do we need labels?; C..
 [Paper Review] CVPR 2020, Hyperbolic Image Embeddings 논문 리뷰 및 설명
[Paper Review] CVPR 2020, Hyperbolic Image Embeddings 논문 리뷰 및 설명
CVPR 2020, Hyperbolic Image Embeddings 논문 링크: https://arxiv.org/abs/1904.02239(https://arxiv.org/abs/1904.02239) Hyperbolic Image Embeddings Computer vision tasks such as image classification, image retrieval and few-shot learning are currently dominated by Euclidean and spherical embeddings, so that the final decisions about class belongings or the degree of similarity are made using linear hy ..
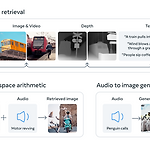 [Paper Review] Meta AI (FAIR)의 새로운 논문, ImageBind: One Embedding Space To Bind Them All 논문 리뷰
[Paper Review] Meta AI (FAIR)의 새로운 논문, ImageBind: One Embedding Space To Bind Them All 논문 리뷰
Meta AI (현 메타 에이아이, 구 페이스북), Facebook Research team (FAIR) IMAGEBIND: One Embedding Space To Bind Them All 논문 링크: https://arxiv.org/pdf/2305.05665.pdf 1. Introduction 최근 Segment Anything Model (SAM) 이라는 것을 발표한 Meta AI에서 또 다른 논문을 발표했다. 2023년 5월 9일 아카이브에 올라온 최신 논문인데, 신선한 아이디어를 제시하고 있어 리뷰할 논문으로 선정했다. 이 논문에서 제시하는 'ImageBind'는 여러가지 모달리티들의 embedding을 하나의 공통 space에 정렬함으로써 긴밀한 관계를 형성하고, 이를 통해 다양한 multi-..
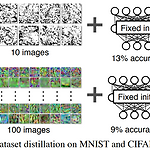 [Paper Review] Dataset Distillation 논문 리뷰
[Paper Review] Dataset Distillation 논문 리뷰
MIT CSAIL, T. Wang et al, Dataset Distillation, 2018 논문 링크: https://arxiv.org/pdf/1811.10959.pdf 1. Introduction 일반적으로 딥러닝에서는 대용량의 데이터셋으로 큰 모델을 학습시키는 것이 좋은 성능을 내고 있다. 하지만 그 경우 많은 메모리, 노동력, 시간 등등의 자원이 필요하므로 효율성 측면에서 좋은 학습 방법이라고 말하기는 어렵다. 그래서 많은 연구진들이 적은 자원으로 최대한의 효율을 낼 수 있는 방법론들에 대한 연구를 진행했고, 본 논문에서 소개하는 'Dataset Distillation (데이터셋 증류)' 도 그 중 하나라고 볼 수 있다. 데이터셋 증류란 대규모 데이터셋을 대표되는 몇 장의 합성 이미지로 압축한 ..
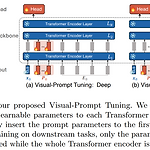 [Paper Review] Visual Prompt Tuning, ECCV 2022 논문 리뷰
[Paper Review] Visual Prompt Tuning, ECCV 2022 논문 리뷰
ECCV 2022, Visual Prompt Tuning, M. Jia et al. 논문 링크: https://arxiv.org/pdf/2203.12119.pdf 1. Introduction 최근 GPT 계열 모델과 같이 대규모 데이터와 대규모 모델을 활용한 딥러닝 연구가 많아졌다. 그러한 데이터의 경우 엔비디아나 구글과 같이 엄청난 컴퓨팅 파워를 가지고 있는 대기업이 아닌 일반인들은 Pretrain된 모델을 Fine-tuning하는 것도 어려운 상황에 이르렀다 :( 따라서 본 논문에서는 비전 분야에서 대규모 Transformer 모델을 효율적으로 활용하기 위한 새로운 fine-tuning 방법인 Visual Prompt Tuning (VPT)을 제안한다. 이는 기존의 fine-tuning 방법보다 더 ..
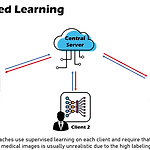 [Paper Review] Federated Contrastive Learning for Volumetric Medical Image Segmentation 논문 리뷰
[Paper Review] Federated Contrastive Learning for Volumetric Medical Image Segmentation 논문 리뷰
Wu et al. / Federated Contrastive Learning for Volumetric Medical Image Segmentation / MICCAI 2021 Oral Federated Contrastive Learning for Volumetric Medical Image Segmentation 1. Problem Definition 해당 논문에서는 의료 영상으로 인공지능 모델을 학습할 때 겪는 대표적인 두 가지 문제를 제시했다. 레이블(label)이 있는 데이터로 학습을 시키는 지도 학습(Supervised Learning)은 많은 분야에서 좋은 결과를 보이고 있으나, 의료 데이터의 레이블을 구하기 위해서는 의료 전문가들이 필요하며 상당한 시간을 요구하기 때문에 레이블이 있는 방대한..
 [Self-Supervised Learning 개론 - 1] Do we need labels?; Contrastive Learning부터 Deep Generative Model까지
[Self-Supervised Learning 개론 - 1] Do we need labels?; Contrastive Learning부터 Deep Generative Model까지
⚽ GOAL 2020 ~ 2023 사이에 활발하게 이루어진 연구들의 개념을 알아본다 각 개념의 대표적인 논문들을 간단하게 소개하여 연구의 흐름을 알아본다 이를 통해서 본인 연구/개발에서 써 볼만한 insight를 얻어갔으면 하는 마음.. 🙈 Unsupervised Learning : input data have no corresponding classifications or labeling examples Clustering (K-means…) Visualization and Dimensionality Reduction (PCA, t-SNE) 🙉 Semi-Supervised Learning : use a small set of input-output pairs and another set of only ..