
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 논문 리뷰
- CVPR
- deep learning 논문 리뷰
- Segment Anything 리뷰
- Data-centric
- ssl
- contrastive learning
- Computer Vision
- 논문리뷰
- Segment Anything 설명
- iclr spotlight
- 자기지도학습
- Multi-modal
- Meta AI
- Stable Diffusion
- Self-supervised learning
- Segment Anything
- Prompt Tuning
- VLM
- Data-centric AI
- active learning
- ai 최신 논문
- cvpr 논문 리뷰
- deep learning
- Computer Vision 논문 리뷰
- iclr 논문 리뷰
- ICLR
- iclr 2024
- Prompt란
- cvpr 2024
- Today
- Total
Study With Inha
[Data-centric AI - 2편] Data-centric AI, ObjectLab: Automated Diagnosis of Mislabeled Images in Object Detection Data 논문 리뷰 본문
[Data-centric AI - 2편] Data-centric AI, ObjectLab: Automated Diagnosis of Mislabeled Images in Object Detection Data 논문 리뷰
강이나 2023. 10. 24. 16:21ObjectLab: Automated Diagnosis of Mislabeled Images in Object Detection Data
https://arxiv.org/pdf/2309.00832.pdf
1. Introduction
아래 링크의 글에서 볼 수 있듯이, 잘못된 GT를 가진 Dataset으로 학습된 모델의 경우 그 성능이 낮아질 수 있다.
이를 방지하기 위해서 연구되는 분야가 Data-centric AI에서 'Data Preparation' 단계의 'Data Cleaning'이다.
[Computer Vision 시리즈물 연재] - [Data-centric AI - 1편] DCAI 소개
[Data-centric AI - 1편] DCAI 소개 및 Data-centric AI: Perspectives and Challenges 논문 리뷰
Data-centric AI: Perspectives and Challenges https://arxiv.org/pdf/2301.04819v3.pdf 앤듀르 응(Andrew Ng) 교수님께서 최근 강조하고 계시는 Data-centric AI란 무엇인지, 그리고 왜 필요한가에 대해 Data-centric AI: Perspectives a
2na-97.tistory.com
Data cleaning은 데이터셋 자체에 있는 노이즈나 에러를 줄이는 것을 목표로 하는데, 오늘 소개할 'ObjectLab'도 그 중 하나이다.
ObjectLab은 detection 데이터셋에 존재하는 bounding box label의 error를 찾아내고, 이를 바르게 수정한다.
여기서는 총 3가지 종류의 label error를 정의했다.
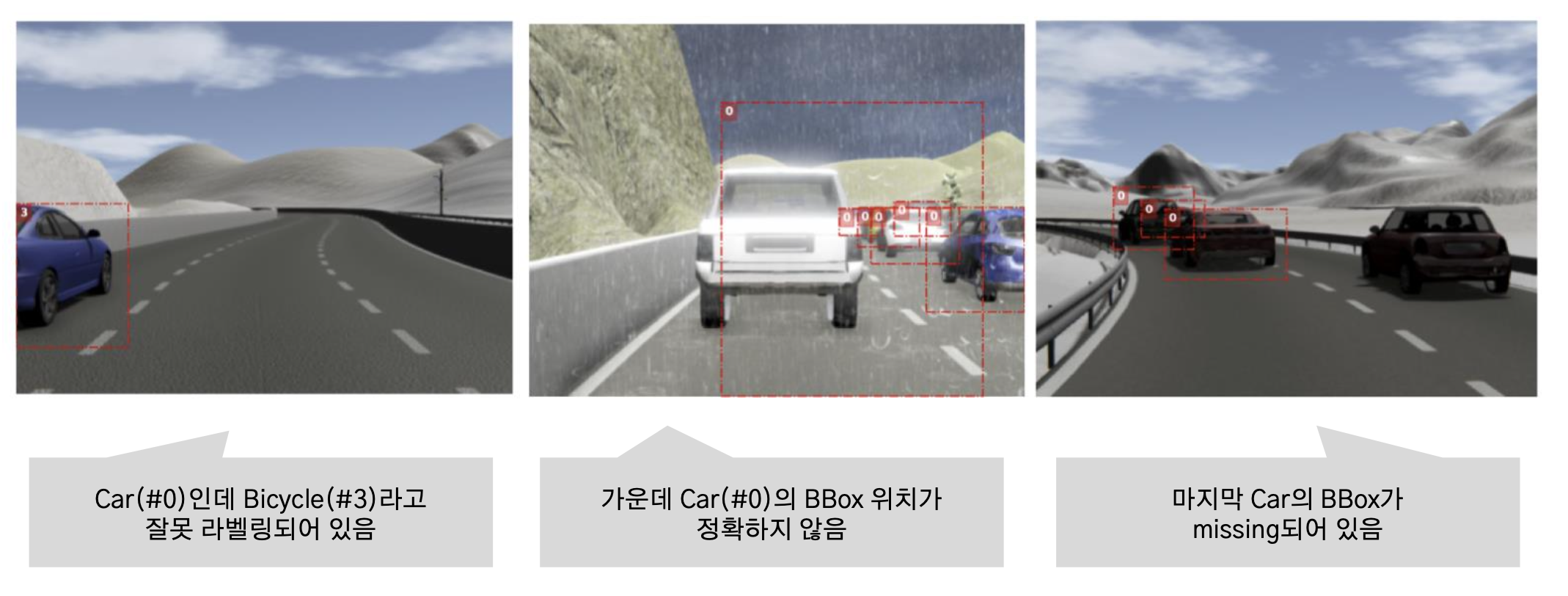
1. Badly Located Error
: GT의 bbox가 object 전체를 포함하고 있지 않거나 위치가 정확하지 않은 경우를 말한다.
아래 예시에서 왼쪽의 붉은색 박스가 GT이고 오른쪽의 파란색 박스가 ObjectLab 모델의 예측 결과인데,
60번 class(=table)를 보면 파란색 bbox는 table 전체가 포함되지만 GT에서는 테이블의 일부만 포함된 것을 확인할 수 있다

2. Swapped Error
: GT의 bbox의 위치는 맞지만, 그 클래스가 틀린 경우를 말한다.
아래의 예시에서 GT의 빨간색 bbox는 상단의 물잔을 bowl에 해당하는 45번 class로 표기한 반면,
ObjectLab으로 교정한 결과 cup에 해당하는 41번 class로 옳게 바뀐 것을 확인할 수 있다.
3. Overlooked Error
: GT에 있어야 할 bbox가 missing된 경우를 말한다.
아래의 예시에서 왼쪽의 GT bbox를 보면 소화전에 bbox가 존재하지 않지만,
오른쪽의 ObjectLab의 결과에서는 소화전에 올바른 bbox가 그려진 모습을 확인할 수 있다.

'ObjectLab'은 어떤 종류의 Detection model인가에 구애 받지 않고, 학습된 모델을 통해 label error를 탐지할 수 있는 알고리즘이다.
모델의 구조를 고칠 필요 없이, Dataset의 label error를 교정함으로써 퀄리티를 올려 모델의 성능을 올리는데 기여했다고 한다.
2. Method
Notation 정리
- I : Image
- B : Bounding Boxes
- c(B)∈1,...,K : bbox 내부에 있는 object의 클래스
- L(I) : 주어진 label (데이터셋에서 주어진 GT)
- ˆs(I) : 이미지 I의 label quality score -> score가 낮을수록 잘못 label됐을 가능성이 높다!
- ˆB : 모델이 예측한 Bounding Boxes
- ˆP(I) : 모델이 예측한 bbox output (이미지에서 예측한 전체 bbox들의 집합)
- ˆc(ˆB) : 모델이 예측한 bbox 내부 object의 클래스
- ˆp(ˆB) : ˆB가 클래스 ˆc(ˆB)에 해당할 confidence 값
- τ : 모델의 confidence(ˆp)에 대한 threshold 값
ObjectLab Algorithm
ObjectLab은 위에서 제시했던 3가지 label error에 대한 score를 geometric mean 계산을 한 뒤 최종 score를 산출한다.
- ˆsbadloc : Badly located error에 대한 score
- ˆsswap : Swapped error에 대한 score
- ˆsoverlook : Overlooked error에 대한 score



Similarity Function
한 이미지에서 나온 bbox pair들에 대해서 아래와 같이 similarity를 계산하는 식을 쓸 수 있다.
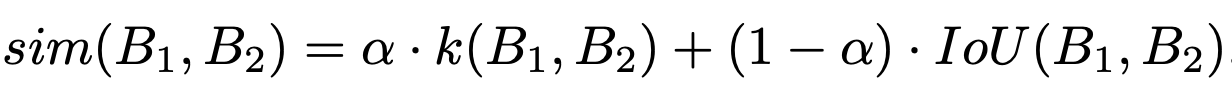
- k(,) : 두 박스의 꼭짓점 정보를 가지고 있는 4D vector에 대한 Gaussian kernel similarity
- B1과 B2가 겹치는 영역이 전혀 없어 IoU 값이 0인 경우인 모든 bbox들이 같은 값을 가지지 않게 하기 위한 장치.
- Sim∗ : annotated bbox와 모델의 predicted bbox pair간의 minimum possible similarity
- q∗=1 : maximum possible quality estimate for any box (across all mistake subtypes)
- 즉, maximum possible quality estimate인 q*로 지정된 경우에는 해당 에러의 후보군이 될만한 bbox들이 존재하지 않는다는 것을 뜻함
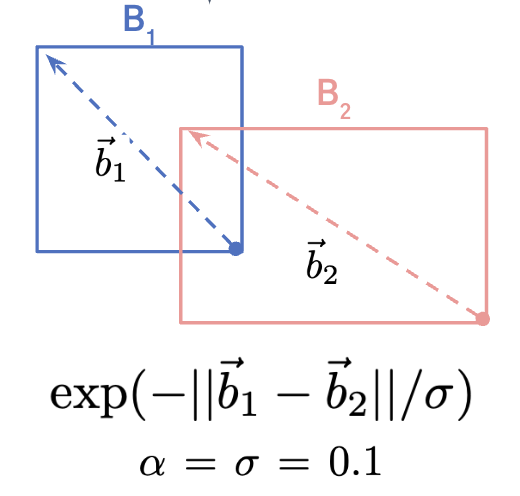
1. Badly Located Scores Per Annotated Box
Badly Loacated Error의 경우 class는 맞췄지만 bbox의 위치가 다소 부정확하다는 것을 뜻한다.
따라서 label이 있는 전체 bbox들에 대해 같은 class를 가진 prediction box와 intersection이 있는 bbox를 찾는다.
그러한 박스들에 대해서 similarity score를 구하고, 그 중 가장 높은 값을 최종 score로 채택하게 된다.
만약, prediction box들 전체에서 annotation에 있는 box와 겹치는 영역이 있으면서 같은 class인 것이 없다면,
Badly located bbox가 아니라고 가정하고 maximum quality score q∗=1로 설정한다.
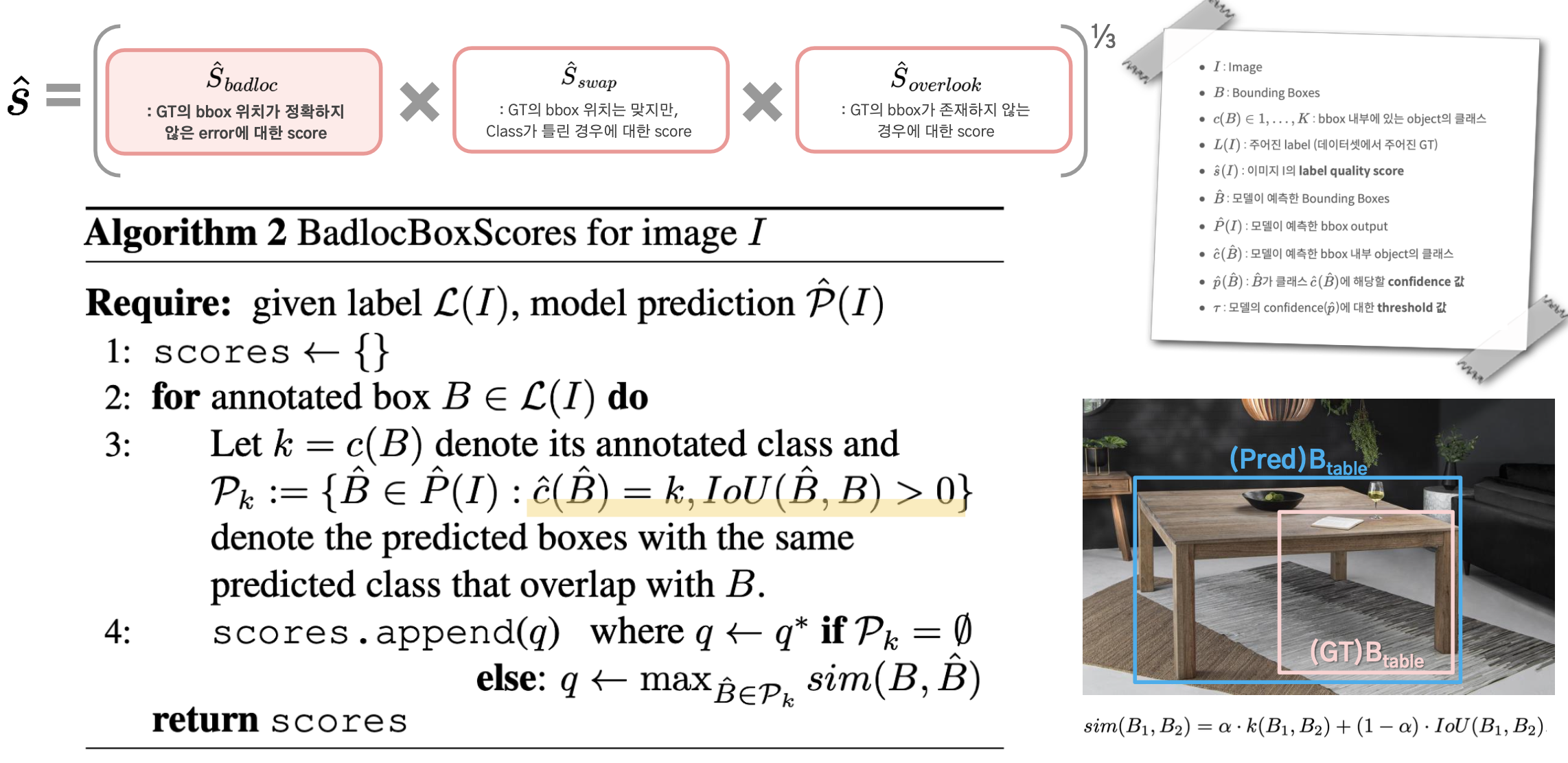
2. Swapped Scores Per Annoated Box
Swapped Error란 bbox의 위치는 비교적 정확하나, class가 틀린 경우를 말한다.
따라서 predicted bbox들 중 bbox의 위치가 매우 유사하면서 annoated class와는 다른 class로 예측했을 때,
model의 class confidence가 매우 높은 경우 Swapped error일 가능성이 높다고 가정했다.
class confidence (τ)를 전체 confidence 분포 상의 95% 이상의 값일 때 similarity score를 계산한다.
만약 annotated bbox와 비슷한 위치를 가지면서도 다른 class로 예측한 것이 없다면,
Swapped bbox가 아니라고 가정하고 maximum quality score q∗=1로 설정한다.
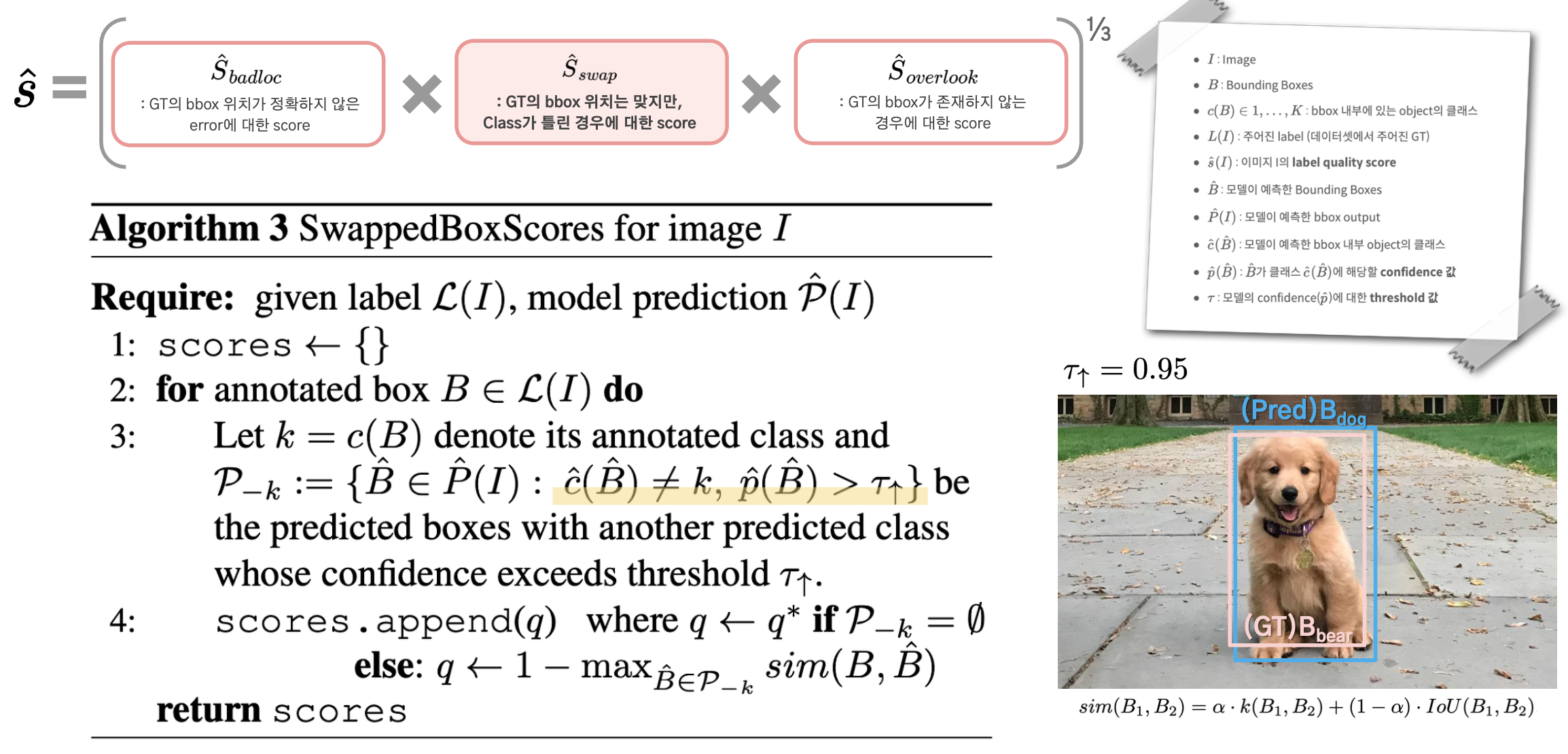
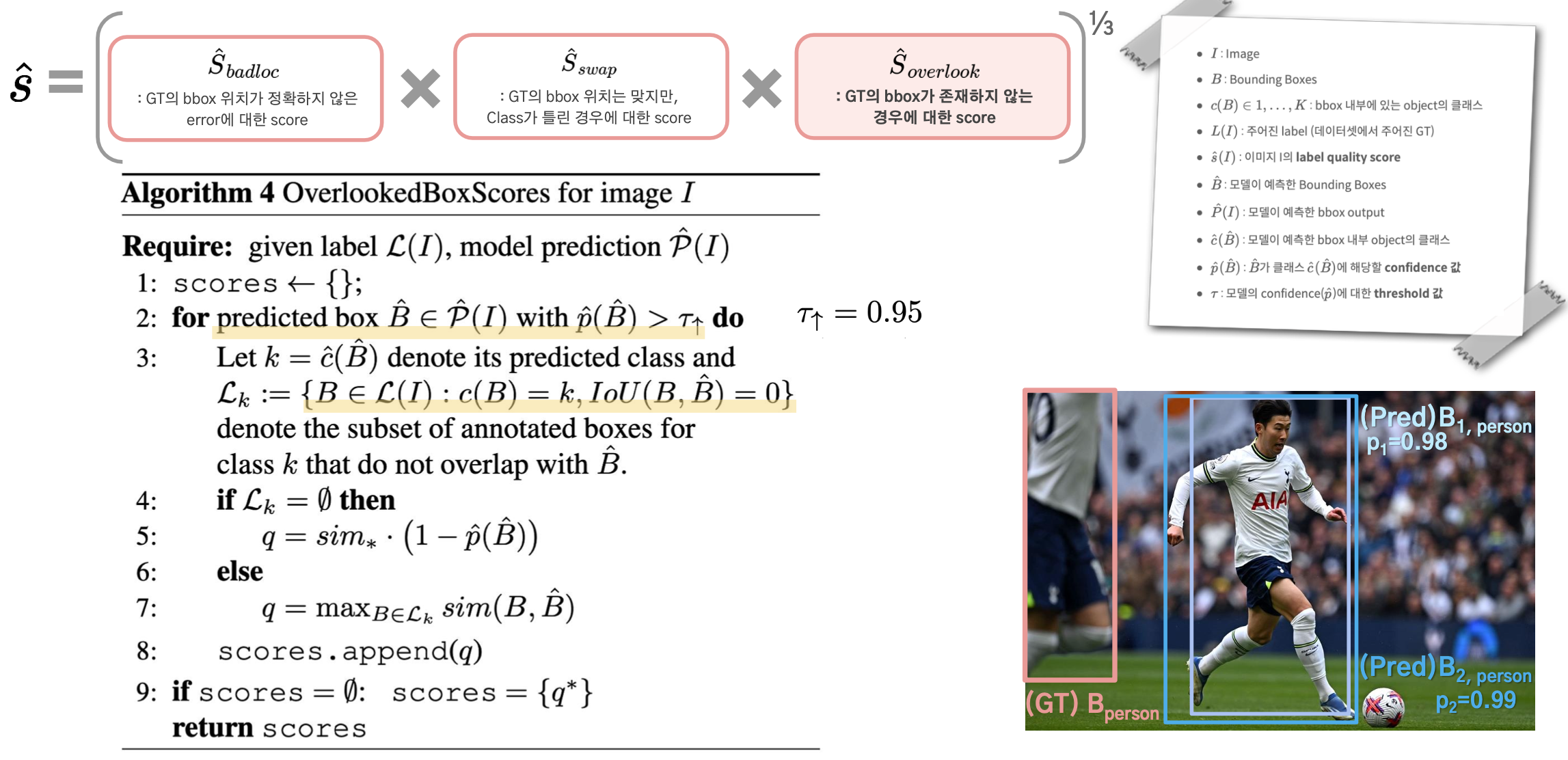
3. Overlooked Scores Per Predicted Box
Overlooked Error란 존재해야 할 Annoated BBox 자체가 존재하지 않는 경우이므로,
Annoated BBox를 기준으로 두는 대신에, 모든 Predicted BBox를 기준으로 score를 계산하게 된다.
Predicted BBox들 중에서 threshold(τ)가 높은 것들만 추려서,
그에 대해서 minimum possible similarity, sim∗(1−ˆp(ˆB)),를 계산하게 된다.
만약 아래 예시에서와 같이 Lk의 후보인 파란색 박스들이 여러개라면,
confidence가 더 높은 bbox가 선정될 수 있도록 유도했다고 한다.
3. Experiments and Results
Dataset and Models
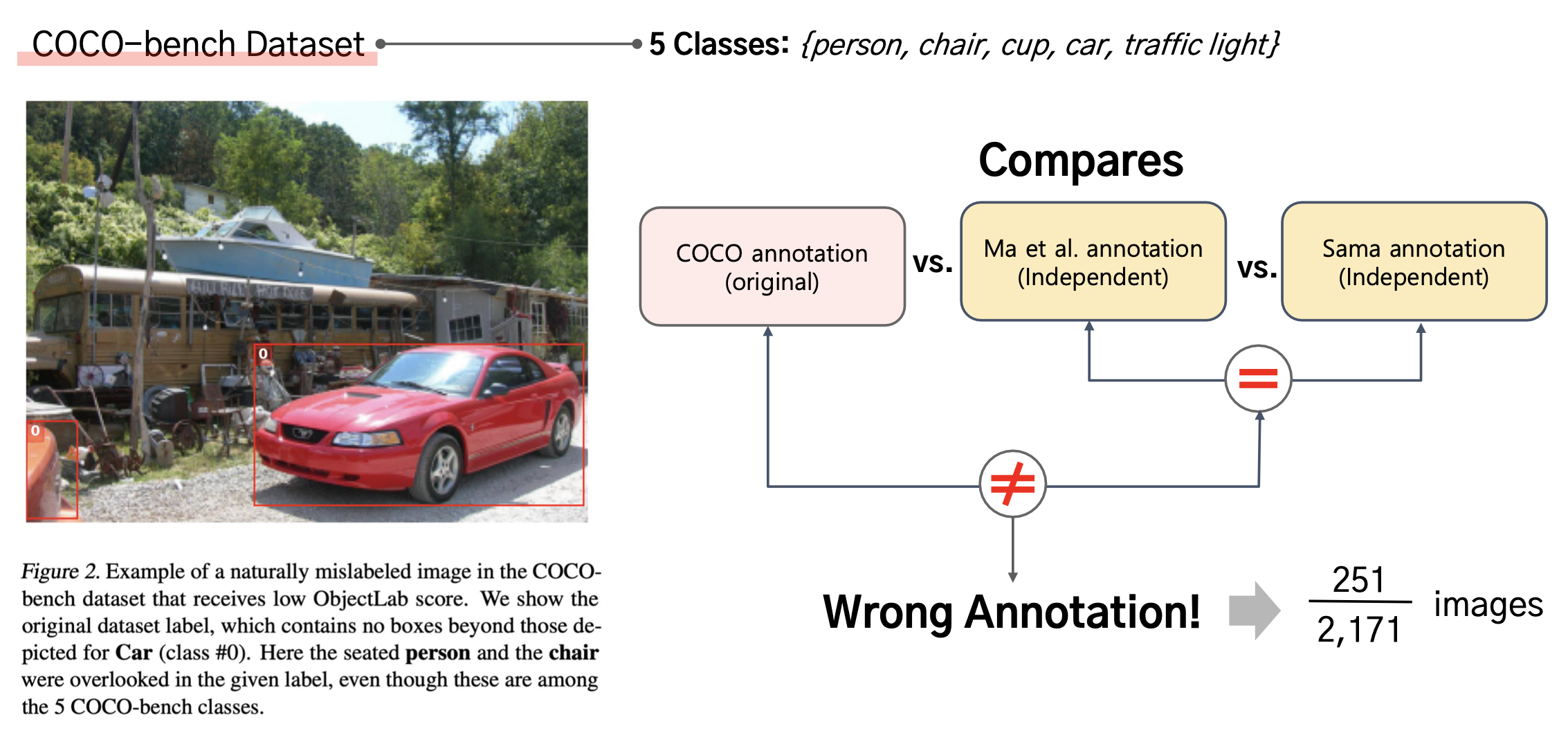
1. COCO-bench dataset
COCO 2017 dataset 중 5개의 클래스 (person, chair, cup, car, traffic light)에 대해서 잘못 레이블된 것이 있는지 봤다고 한다.
COCO에서 제공한 annotation과 서로 다른 두 사람이 독립적으로 annoatate한 것들이 다른 것들에 대해서 조사했다고 한다.
(독립적으로 annotation한 정보는 같은데, COCO만 다른 정보를 뱉은 경우를 틀린 annotation이라고 가정)
2171개의 이미지 중 251개의 이미지가 mislabeled를 포함하고 있다는 것을 찾아냈다고 한다.
2. SYNTHIA-AL Dataset
다른 데이터셋에서도 ObjectLab의 score가 낮은 sample들을 살펴보았을 때,
모두 labeling error가 존재했다고 한다.
3. COCO-full dataset
COCO 2017 training dataset의 80개 클래스를 포함하는 118,000장의 이미지에 대해서 score를 계산해 보았다고 한다.
그 중 가장 낮은 점수를 가지는 100장에 대해서 manual하게 직접 검수를 진행했고,
그 결과 모두 실제로 잘못 레이블된 이미지였다고 한다.



Results
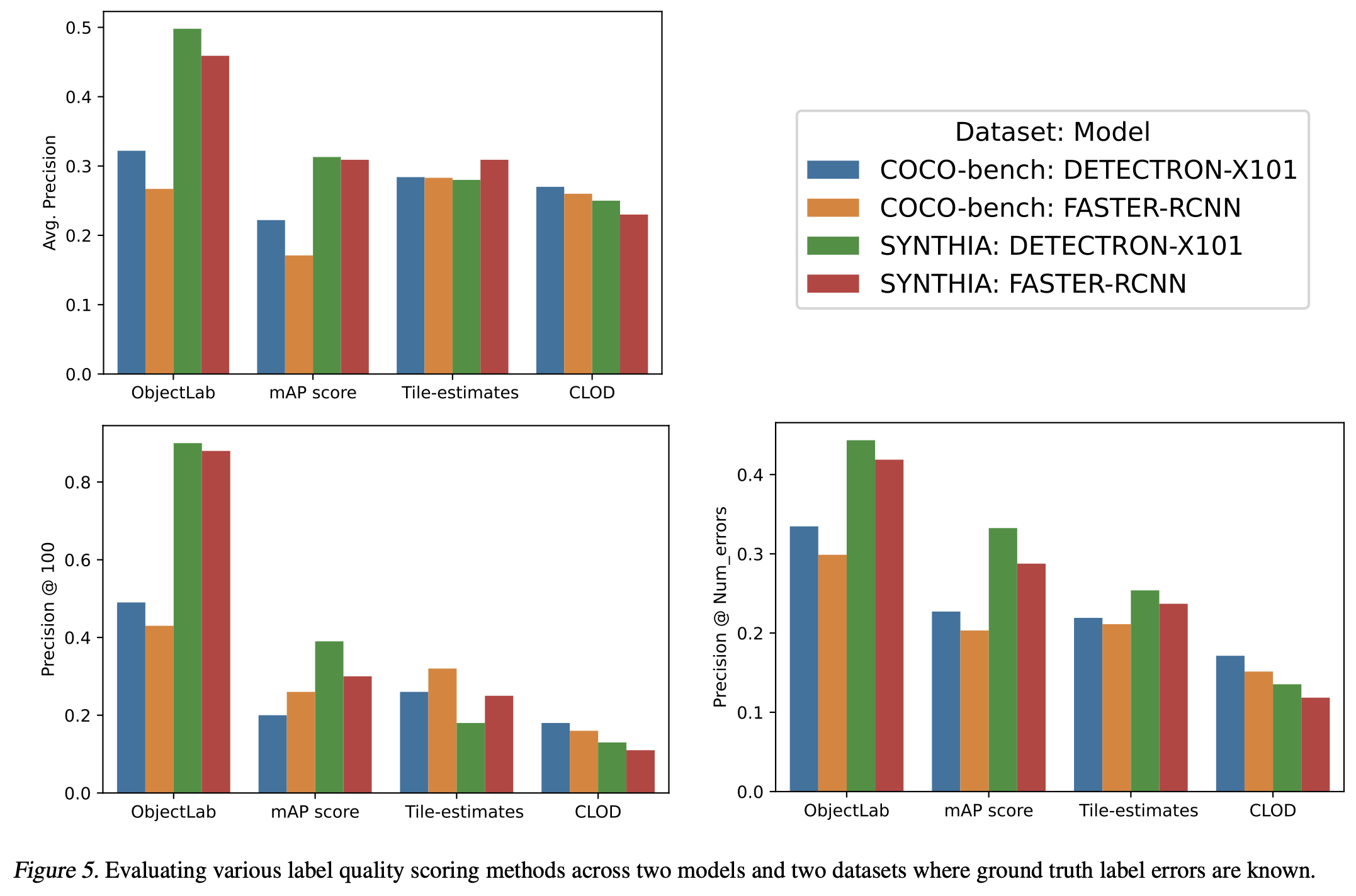
에러가 있는 것이 확인된 샘플들에 대해서 ObjectLab을 포함한 다양한 방법으로 오류를 탐지할 수 있는지 확인해 보았을 때,
다른 방법들보다 ObjectLab의 탐지 능력이 가장 뛰어났다고 한다. (precision이 높을 수록 많은 오류를 탐지한 것임)
ObjectLab 결과에 따르면 COCO 2017 데이터셋에는 3%의 badly located error, 0.7%의 swapped error, 그리고 5%의 overlooked error가 존재했다고 한다.

Results ++ 추가 References
올바르게 교정한 데이터셋으로 Training하거나 Test한 결과가 없어서 관련 논문들의 결과를 더 살펴보았다.
1. Error를 교정한 Test dataset에 대한 결과
논문 링크: https://arxiv.org/abs/2103.14749
Pervasive Label Errors in Test Sets Destabilize Machine Learning Benchmarks
We identify label errors in the test sets of 10 of the most commonly-used computer vision, natural language, and audio datasets, and subsequently study the potential for these label errors to affect benchmark results. Errors in test sets are numerous and w
arxiv.org
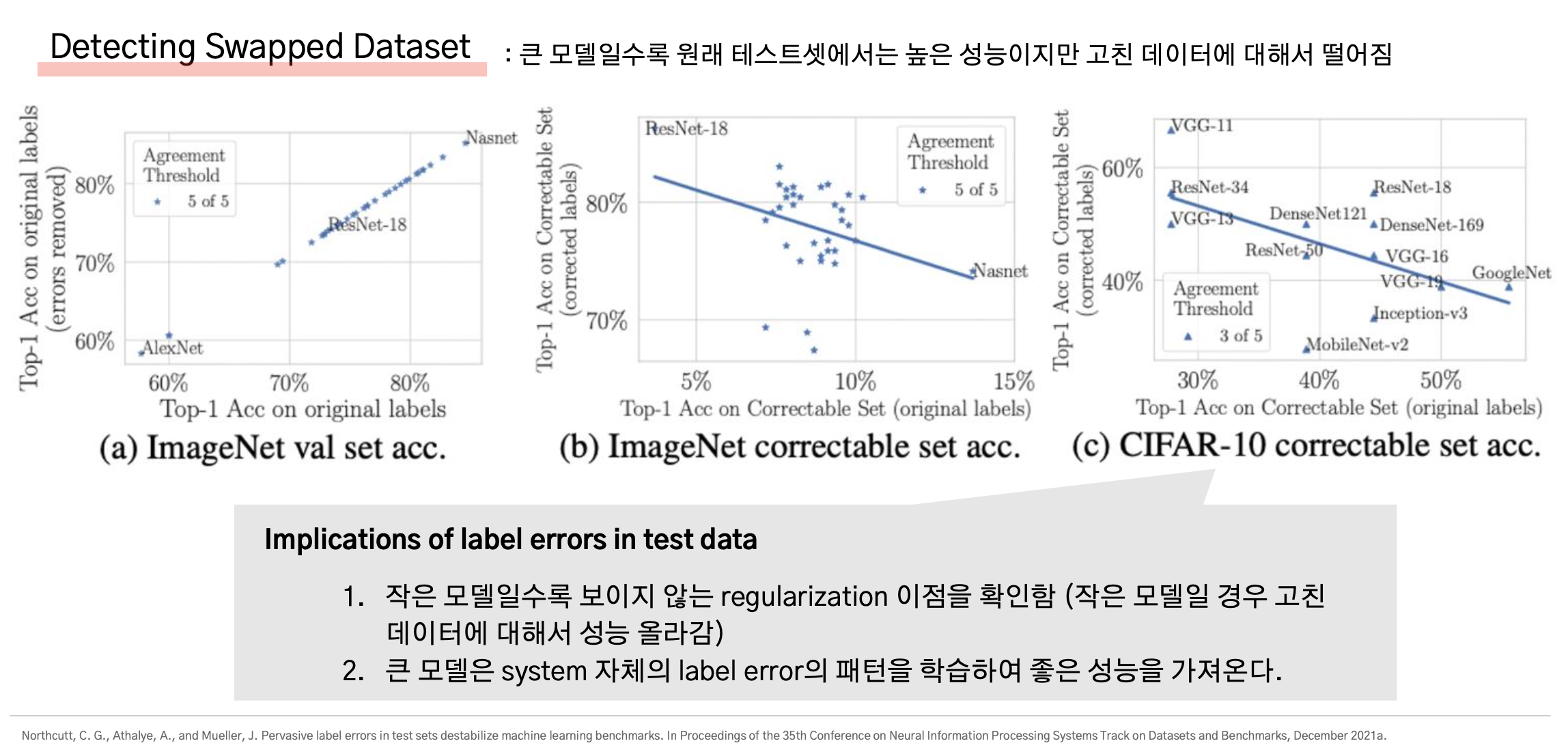
Swapped Error가 있는 Test dataset의 오류를 고쳤을 때와 고치지 않았을 때 성능 비교를 한 결과이다.
이를 살펴보면, VGG-11이나 ResNet-18과 같이 비교적 작은 모델일수록 에러를 고친 Test셋에서 높은 성능을 보였다.
논문에서는 작은 모델일수록 GT의 에러를 올바르게 고쳐주어 regularization을 해줄 경우 좋은 결과를 보인다고 했다.
반면에 큰 모델일수록 에러를 고친 test dataset에서보다 기존의 test dataset (=소량의 error가 존재하는 데이터셋)에서 좋은 성능을 보였다.
해당 논문의 저자는 이를 큰 모델은 training 시에 system 자체의 label error의 패턴을 학습하여 좋은 성능을 가져온다고 분석했다.
(즉, 큰 논문은 training 시에 training dataset에 존재하는 label error의 패턴까지도 학습할 수 있기 때문에, 소량의 error가 있는 test dataset에서 더 좋은 성능을 낸다는 것)
2. Error를 교정한 Training/Test dataset에 대한 결과
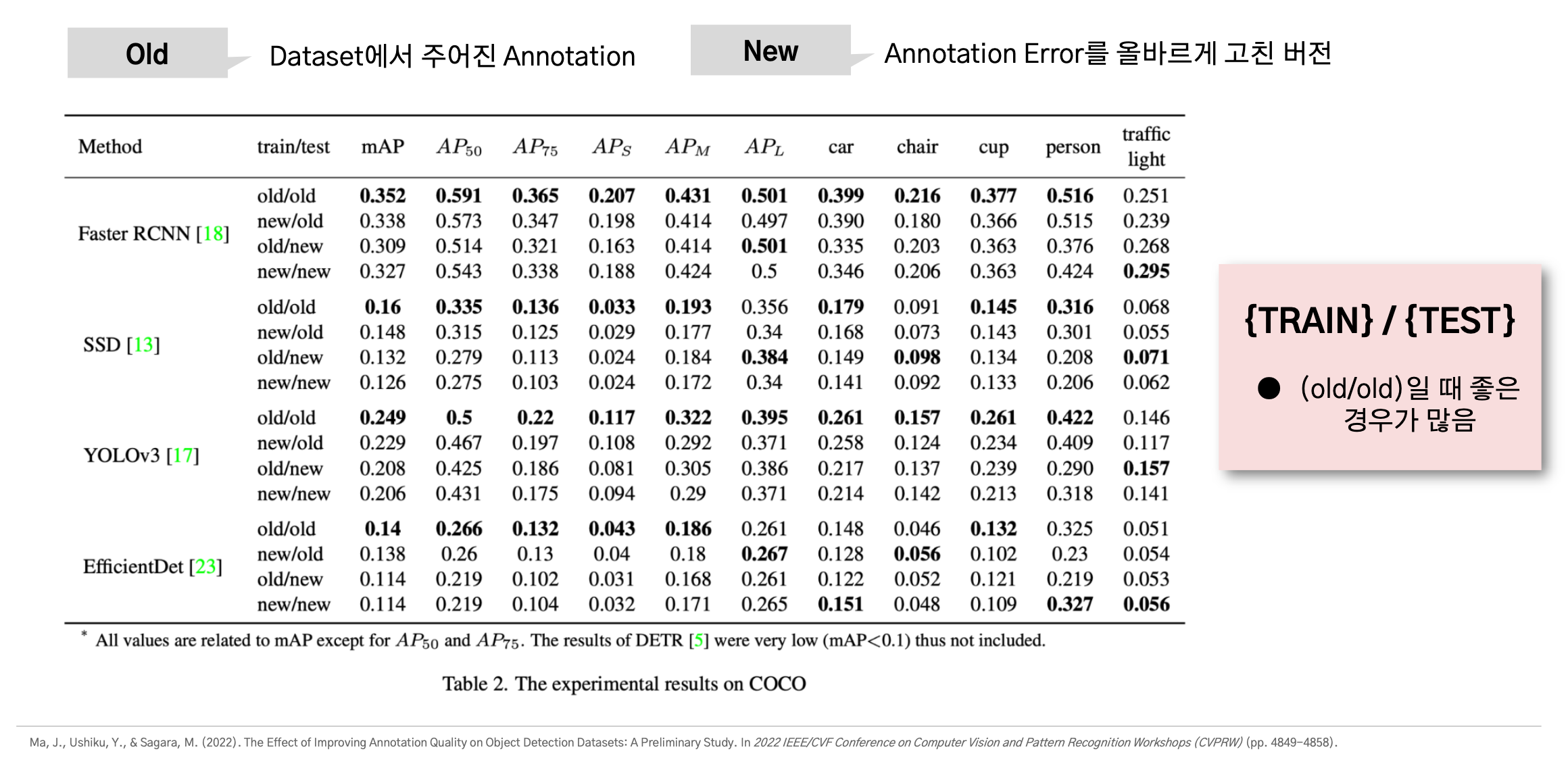
이 논문은 Training Dataset과 Test Dataset의 Error를 고친 데이터셋에 대한 실험 결과를 보여주고 있다.
Old의 경우 데이터셋에서 원래 주어지는 GT를 뜻하고, New의 경우 주어지는 GT에 존재하는 Error를 모두 교정한 새로운 GT를 말한다.
Old/Old의 경우 본래 주어진 GT로 트레이닝하고 테스트했다는 것을 뜻하는데,
COCO 데이터셋에서는 아래와 같이 old/old인 경우에 가장 좋은 성능을 보일 때가 많았다고 한다.
반면에 Open Image 데이터셋에서는 아래와 같이 new/new인 경우에 가장 좋은 성능을 보일 때가 많았다.
이런 상반되는 결과를 보이는 이유는 본래 데이터셋의 noisy한 정도가 다르기 때문이라고 한다.
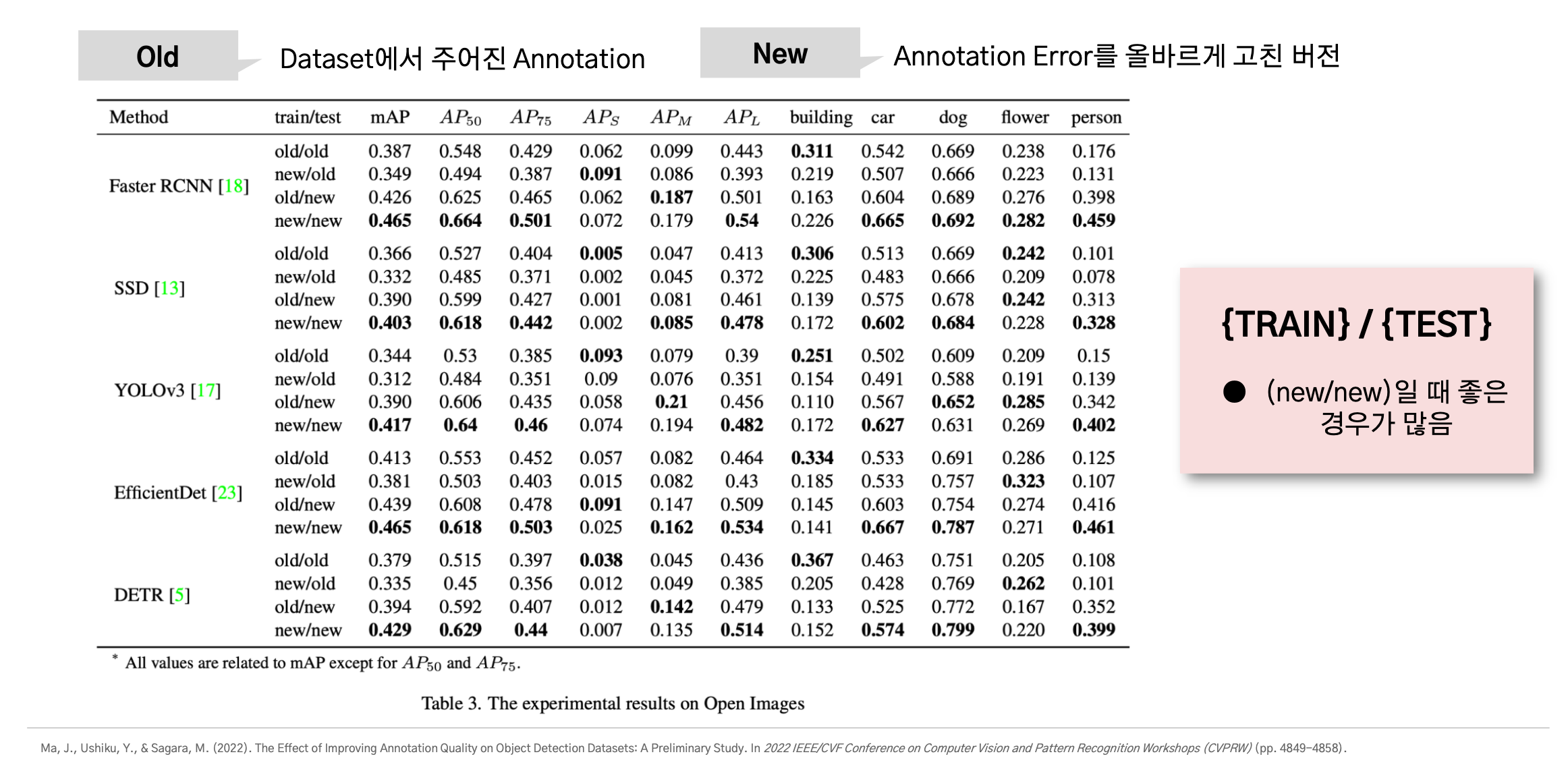
COCO dataset의 경우 GT의 error 비율이 ~8%정도지만 Open Image는 그보다 훨씬 많은 error를 가지고 있다.
따라서 reference 1번 논문의 결과와 결합하여 생각해보면,
COCO dataset에 존재하는 것과 같은 적당한 error는 너무 쉬운 task가 되지 않도록 하여 학습에 도움이 되지만,
Open Image dataset에 존재하는 것과 같은 많은 error는 학습에 방해가 되므로 에러를 교정해 주었을 때 성능이 더 올라갈 수 있었다는 것이다.
4. Conclusions
1. ObjectLab은 모델 구조 변화 없이 Annotation Error를 탐지하고, 이를 올바르게 고쳐줄 수 있는 General한 Toolkit임
2. Noisy Dataset으로 학습을 잘 시키는 방법에 대한 연구도 있지만, 데이터셋의 오류를 교정하여 좋은 데이터셋으로 학습 혹은 테스트를 해보자는 접근 방법임
3. 데이터셋에 존재하는 약간의 에러는 너무 쉬운 Task가 되지 않도록 도와 모델의 Robustness를 올려줄 수 있으나, 에러가 많은 경우 학습에 방해가 됨
4. 어느 논문의 Intro를 보면 Third-party Data Annotation Vendor에 의해 7%~80%의 레이블 에러 발생한다고 함.
→ 실제 산업에서는 직접 데이터를 만들어야 하는 경우가 많으므로, 이럴 때 유용하게 쓸 수 있을 것으로 보임
#AI최신논문 #AI최신논문리뷰 #딥러닝최신논문리뷰 #컴퓨터비전최신논문



