
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- Segment Anything
- contrastive learning
- Stable Diffusion
- Data-centric AI
- cvpr 2024
- Meta AI
- deep learning
- CVPR
- Multi-modal
- 자기지도학습
- Segment Anything 리뷰
- iclr 논문 리뷰
- cvpr 논문 리뷰
- Prompt Tuning
- Computer Vision 논문 리뷰
- 논문 리뷰
- deep learning 논문 리뷰
- VLM
- iclr spotlight
- Data-centric
- ICLR
- Self-supervised learning
- Segment Anything 설명
- iclr 2024
- Computer Vision
- ai 최신 논문
- Prompt란
- ssl
- active learning
- 논문리뷰
- Today
- Total
Study With Inha
[Self-Supervised Learning 개론 - 1] Do we need labels?; Contrastive Learning부터 Deep Generative Model까지 본문
[Self-Supervised Learning 개론 - 1] Do we need labels?; Contrastive Learning부터 Deep Generative Model까지
강이나 2023. 3. 22. 16:09⚽ GOAL
- 2020 ~ 2023 사이에 활발하게 이루어진 연구들의 개념을 알아본다
- 각 개념의 대표적인 논문들을 간단하게 소개하여 연구의 흐름을 알아본다
- 이를 통해서 본인 연구/개발에서 써 볼만한 insight를 얻어갔으면 하는 마음..
🙈 Unsupervised Learning
: input data have no corresponding classifications or labeling
- examples
- Clustering (K-means…)
- Visualization and Dimensionality Reduction (PCA, t-SNE)
🙉 Semi-Supervised Learning
: use a small set of input-output pairs and another set of only inputs to optimize a model for a task what we solve (최근에는 supervised보다 semi-supervised가 더 좋은 성능을 보이는 연구들도 많음)
- examples
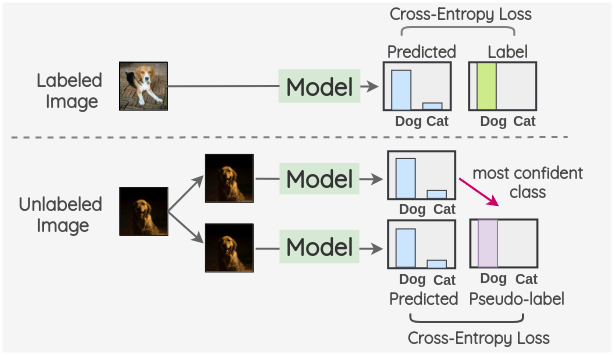
- teacher-student network: labeled image로 학습된 모델 (teacher)의 결과로 unlabeled image로 학습되는 모델 (student)을 학습시켜 일부만 레이블이 있는 상황에서 좋은 성능을 얻고자 하는 방법론
🙊 Weakly Supervised Learning
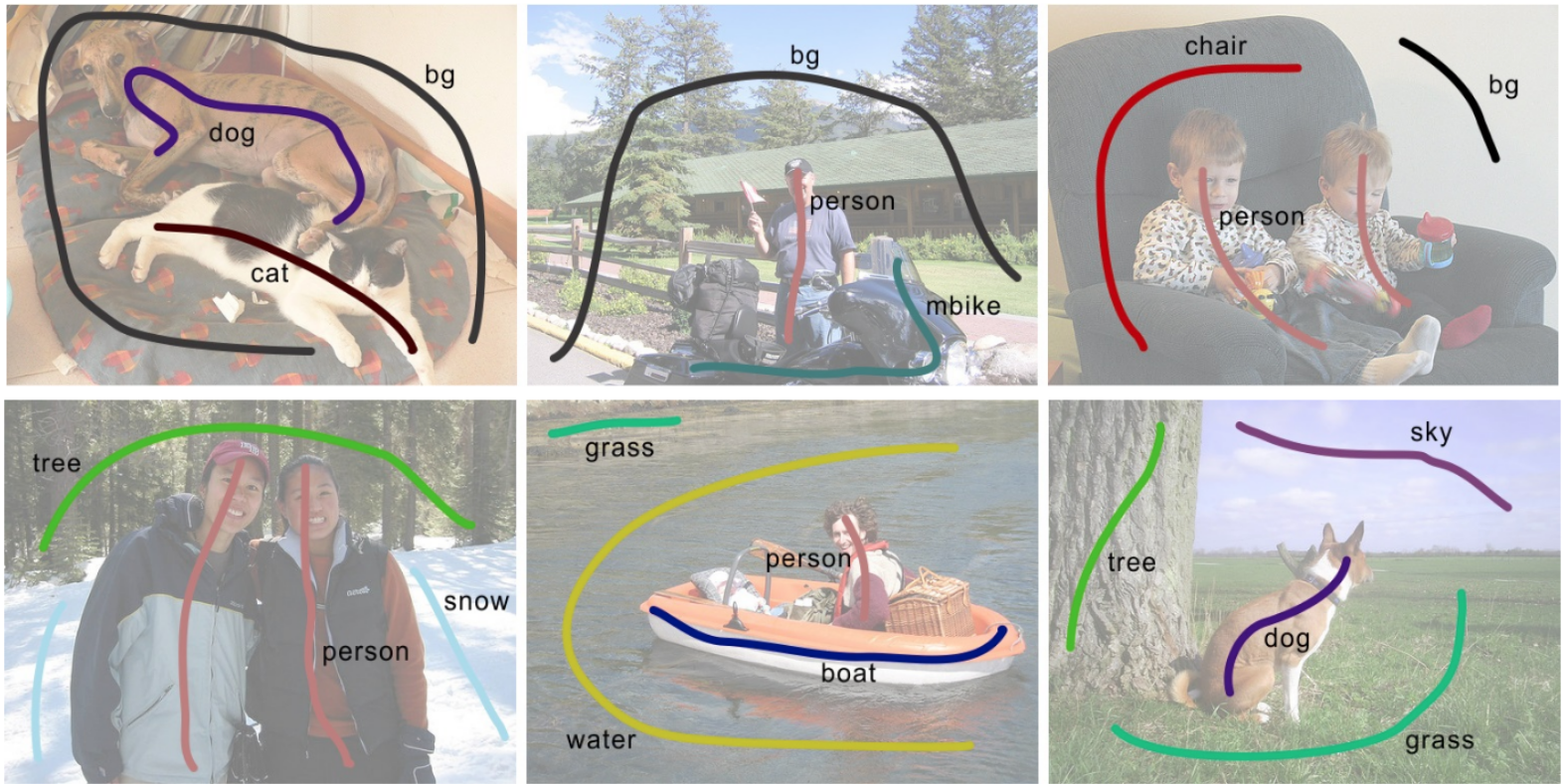
: noisy, limited, or imprecise labels are provided for a task
- examples

🤳🏼 Self-Supervised Learning
: instead of finding high-level patterns for clustering, self-supervised learning attempts to still solve task that are traditionally targeted by supervised learning (= they want to train general “representations” of input data)
- Stream of Self-supervised Learning
- Pretext task (목표 task와 상관 없는 task 수행. 이 과정을 통해 feature extracter를 강화할 수 있고, fully supervised learning보다 좋은 성능을 내기도 함.)
- Fine-tuning (or Linear Probing 수행. 보통 Fine-tuning이 더 좋은 성능을 낸다고 함) → 실제 목표 task를 수행하는 training을 진행하는 단계
요약 개요 그림
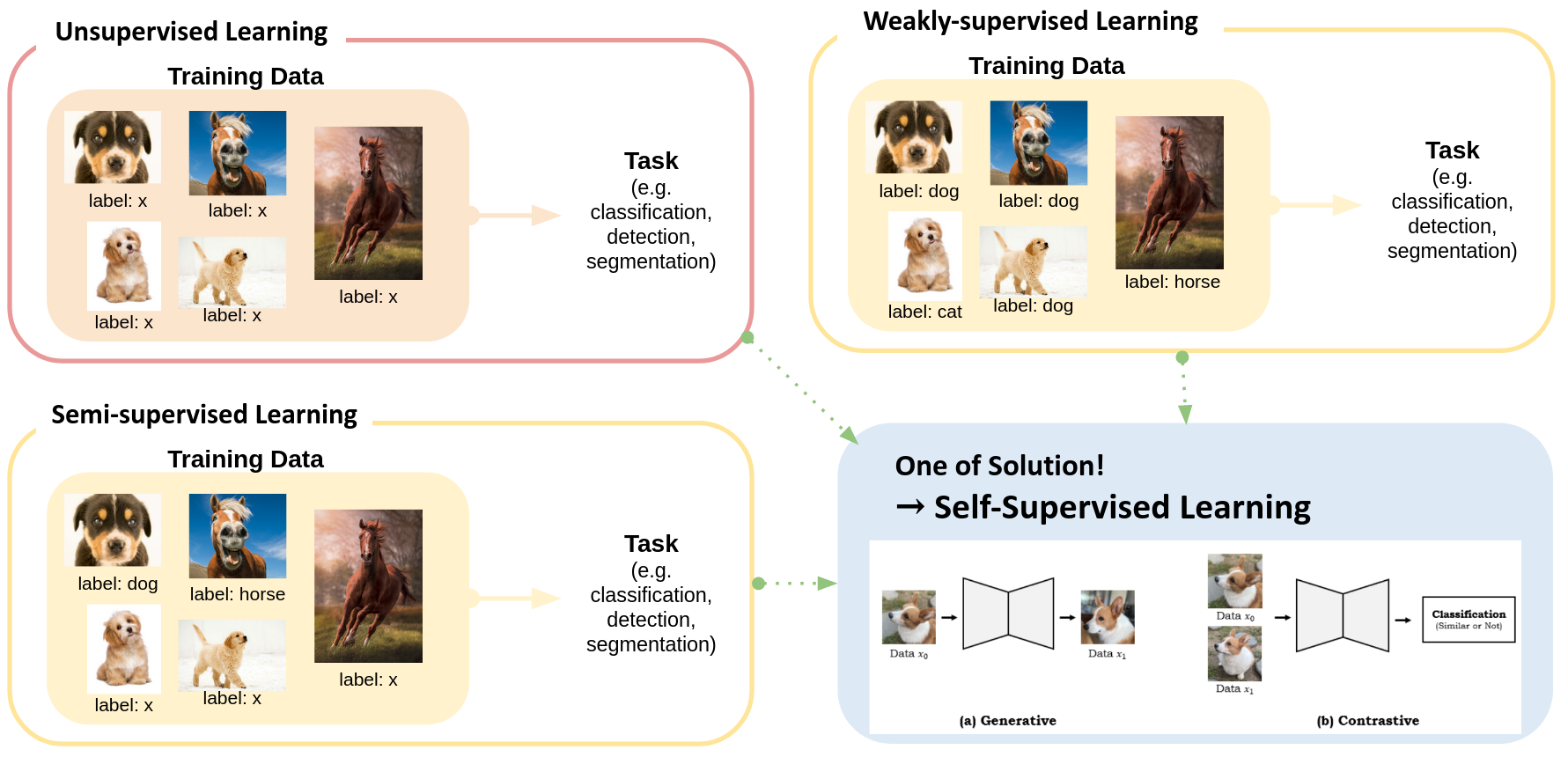
위 사진과 같이 Self-supervised Learning (a.k.a. SSL, 셀숩) 의 종류는 크게 2가지로 나눌 수 있음.
: (1) Generative Method
(2) Contrastive Method
→ 사실 연구가 진행됨에 따라 두 가지 영역의 경계선도 점점 더 모호해지고 있다는 생각이 듦. 그 이유는 to be continued…



