
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- CVPR
- Prompt란
- Multi-modal
- deep learning 논문 리뷰
- iclr 2024
- Segment Anything 리뷰
- deep learning
- Segment Anything
- Prompt Tuning
- Data-centric
- cvpr 2024
- 자기지도학습
- Data-centric AI
- iclr 논문 리뷰
- ICLR
- Self-supervised learning
- 논문 리뷰
- Computer Vision
- Meta AI
- Stable Diffusion
- ssl
- active learning
- ai 최신 논문
- cvpr 논문 리뷰
- VLM
- contrastive learning
- 논문리뷰
- Segment Anything 설명
- Computer Vision 논문 리뷰
- iclr spotlight
- Today
- Total
Study With Inha
[Self-Supervised Learning 개론 - 2] Do we need labels?; Contrastive Learning부터 Deep Generative Model까지 본문
[Self-Supervised Learning 개론 - 2] Do we need labels?; Contrastive Learning부터 Deep Generative Model까지
강이나 2023. 3. 22. 20:07[Self-Supervised Learning 개론 - 1] 링크
[Self-Supervised Learning 개론 - 1] Do we need labels?; Contrastive Learning부터 Deep Generative Model까지
⚽ GOAL 2020 ~ 2023 사이에 활발하게 이루어진 연구들의 개념을 알아본다 각 개념의 대표적인 논문들을 간단하게 소개하여 연구의 흐름을 알아본다 이를 통해서 본인 연구/개발에서 써 볼만한 insigh
2na-97.tistory.com
(1) SSL - Generative Learning 🛠️
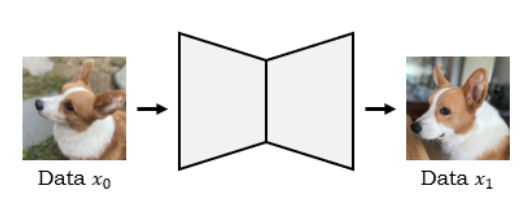
: 입력 이미지를 넣은 후 생성된 출력 이미지에 대한 loss를 비교하는 방법 (by L1, L2 loss…)
- AutoEncoder, GAN, Diffusion Model (← new trend 🌟) 등이 있을 수 있음
a. GAN based
: 두 네트워크 (Discriminator, Generator)를 경쟁적 학습을 시키는 (adversarial learning) 방법
- Discriminator

- Generator

ex. SSGAN (Self-supervised GAN)
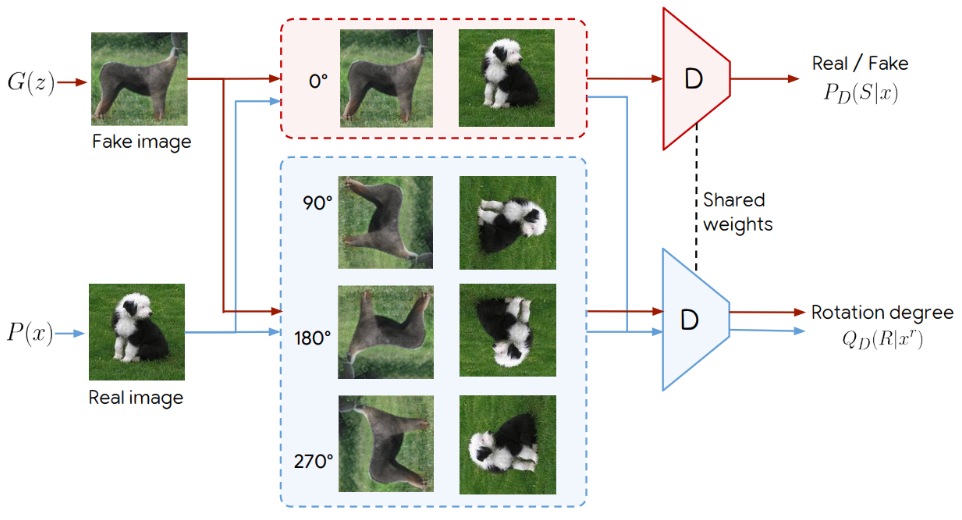
(1) 이미지의 진위 여부
(Fake / Real) 판별
(2) Pretext task: rotation degree 예측
→ SSL을 적용한 discriminator를 사용하여 GAN을 구성함.
→ Discriminator Forgetting, 즉 학습을 계속 할 때 이전에 학습한 class에 대한 정보가 사라지는 현상들을 많이 해결했다고 함
논문 링크: https://arxiv.org/pdf/2106.08601v5.pdf [NeurIPS 2021]
b. Diffusion Model (그 중 Denoising Diffusion Probabilistic Model, a.k.a. DDPM)
: 데이터를 만들어내는 deep generative model 중 하나.
(1) Forward process: data로부터 noise를 조금씩 더해 가면서 data를 완전한 noise로 만드는 과정
(2) Reverse process: noise로부터 조금씩 복원해 가면서 data를 만드는 과정

→ random noise로부터 우리가 원하는 image, text, graph 등을 generate 할 수 있는 모델을 만들어 냄. 이를 통해서 우리는 실제 data의 분포인 p(x_0)를 찾아내는 것을 목적으로 함.
- Reverse Process: noise (표준 정규 분포를 따르는 noise를 지칭) 로부터 data를 복원하는 과정. random noise로부터 data를 generate 하는 것이 목적이므로 이 과정이 필수적임.
- Gaussian transition을 활용한 Markov chain의 형태를 가짐
- 각 단계의 정규 분포의 평균과 표준편차가 학습되어야 하는 parameter에 해당함.
- → but, 이를 아는 것이 쉽지 않음. 따라서 중간 과정들을 통해서 approximate 함.
- Forward Process: data로부터 noise를 더해 가면서 최종 noise (표준 정규 분포를 따르는 noise) 형태로 가는 과정.
- why?: reverse process를 학습하기 위해서는 중간 과정의 분포가 필요한데, 이 때 forward process의 정보를 활용함.
- how?: data에 Gaussian noise를 조금씩 더하는 Markov chain의 형태를 가짐.→ data가 주어졌을 때 임의의 timestep t 시점의 x_t를 자유롭게 sampling할 수 있다는 장점이 생김!
- Total Training Scheme: 실제 data의 분포인 p(x_0)를 찾아내는 것이 목적이기 때문에, 결국 이의 likelihood를 최대화하는 방향으로 학습하고자 함.증명 과정이 매우 수학 파티… 원하시는 분은 논문을 참고해 보시길…
- 논문 링크: https://arxiv.org/abs/2006.11239

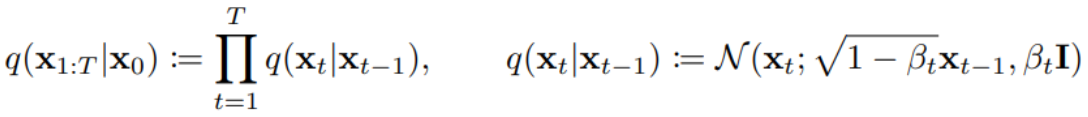
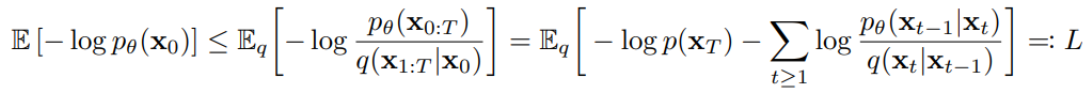
결국 Diffusion model의 장점은 무엇인가?
- GAN에서 발생했던 mode collapse (다양한 이미지를 생성해내지 못하고 비슷한 이미지만 생성해 내는 것)을 많이 해결함
- GAN보다 학습의 안정성이 더 높아졌다고 함



