
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- Data-centric
- iclr 2024
- cvpr 논문 리뷰
- deep learning
- Meta AI
- Data-centric AI
- Segment Anything 설명
- Multi-modal
- iclr spotlight
- iclr 논문 리뷰
- active learning
- 자기지도학습
- deep learning 논문 리뷰
- 논문 리뷰
- VLM
- ssl
- ICLR
- Prompt란
- cvpr 2024
- Prompt Tuning
- contrastive learning
- Segment Anything
- Stable Diffusion
- 논문리뷰
- Computer Vision 논문 리뷰
- CVPR
- ai 최신 논문
- Computer Vision
- Self-supervised learning
- Segment Anything 리뷰
- Today
- Total
Study With Inha
[Self-Supervised Learning 개론 - 3] Do we need labels?; Contrastive Learning부터 Deep Generative Model까지 본문
[Self-Supervised Learning 개론 - 3] Do we need labels?; Contrastive Learning부터 Deep Generative Model까지
강이나 2023. 5. 24. 16:49[Self-supervised Learning 개론 관련 이전 글]
[Self-Supervised Learning 개론 - 1]
[Self-Supervised Learning 개론 - 1] Do we need labels?; Contrastive Learning부터 Deep Generative Model까지
⚽ GOAL 2020 ~ 2023 사이에 활발하게 이루어진 연구들의 개념을 알아본다 각 개념의 대표적인 논문들을 간단하게 소개하여 연구의 흐름을 알아본다 이를 통해서 본인 연구/개발에서 써 볼만한 insigh
2na-97.tistory.com
[Self-Supervised Learning 개론 - 2]
[Self-Supervised Learning 개론 - 2] Do we need labels?; Contrastive Learning부터 Deep Generative Model까지
https://2na-97.tistory.com/2 [Self-Supervised Learning 개론 - 1] 링크 [Self-Supervised Learning 개론 - 1] Do we need labels?; Contrastive Learning부터 Deep Generative Model까지 ⚽ GOAL 2020 ~ 2023 사이에 활발하게 이루어진 연구들의
2na-97.tistory.com
(2) SSL - Contrastive Learning 👬
: 입력 받은 이미지들의 비슷함 정도 (Similarity)를 비교하는 과정을 거침. 비슷한 이미지끼리는 positive pair로 분류하고 다른 이미지끼리는 negative pair로 분류하여 대조하는 과정을 통해서 representation을 학습하게 됨.

이번 글에서는 Contrastive Learning 관련한 대표적인 세 가지 논문을 소개할 것이다.
1. SimCLR
2. BYOL
3. Masked AutoEncoder
1. SimCLR, A Simple Framework for Contrastive Learning of Visual Representations
논문링크: https://arxiv.org/abs/2002.05709
A Simple Framework for Contrastive Learning of Visual Representations
This paper presents SimCLR: a simple framework for contrastive learning of visual representations. We simplify recently proposed contrastive self-supervised learning algorithms without requiring specialized architectures or a memory bank. In order to under
arxiv.org
한 이미지에 서로 다른 augmentation을 적용한 후,
같은 이미지에서 augmentation된 이미지들의 similarity는 높게 하되
다른 이미지(class)와의 similarity는 낮추는 방향으로 학습
- 같은 이미지에 대해서는 augmentation으로 인한 변화를 무시하는 방향으로 학습
- 다른 이미지에 대해서는 representation간의 간격을 크게 하는 방향으로 학습
- 그 결과, label이 없더라도 이미지의 유의미한 feature를 뽑아내는 pre-train된 인코더를 얻을 수 있게 된다.
Loss Function 설명




SimCLR 왜 사용함?
→ supervised learning만 사용했을 때보다 더 좋은 결과를 얻음
→ data 자체의 representation을 잘 학습했기 때문!
→ but, 엄청나게 큰 batch size가 필요 (batch가 클 수록 비교를 더 많이 할 수 있기 때문)
→ SSL 연구의 시조새라고 해도 무방할 정도. 이후 contrastive learning 연구가 폭풍 이루어짐.
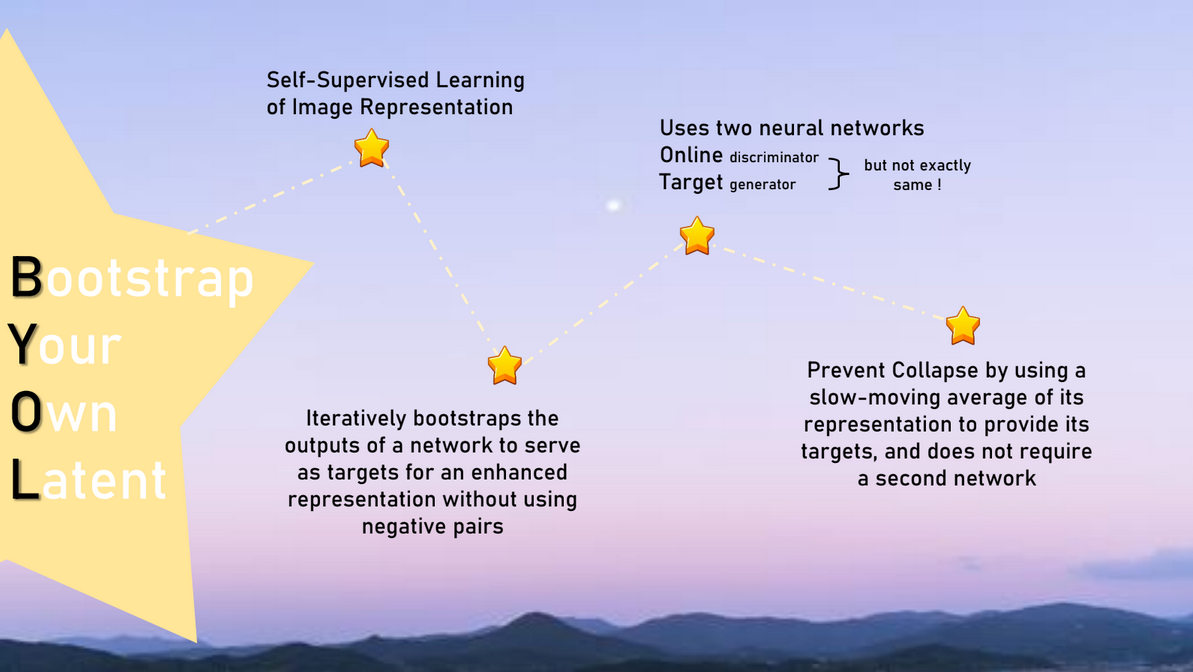
2. BYOL, Bootstrap your own latent: A new approach to self-supervised Learning
논문 링크: https://arxiv.org/abs/2006.07733
Bootstrap your own latent: A new approach to self-supervised Learning
We introduce Bootstrap Your Own Latent (BYOL), a new approach to self-supervised image representation learning. BYOL relies on two neural networks, referred to as online and target networks, that interact and learn from each other. From an augmented view o
arxiv.org
기존 방법들은 similarity 비교를 위해서 많은 negative pair와 positive pair가 필요하여
엄청나게 큰 batch size가 있어야 좋은 성능을 보인다는 단점이 있었다.
따라서 BYOL은 negative pair를 사용하지 않고,
image들로부터 양질의 representation을 배우기 위해서
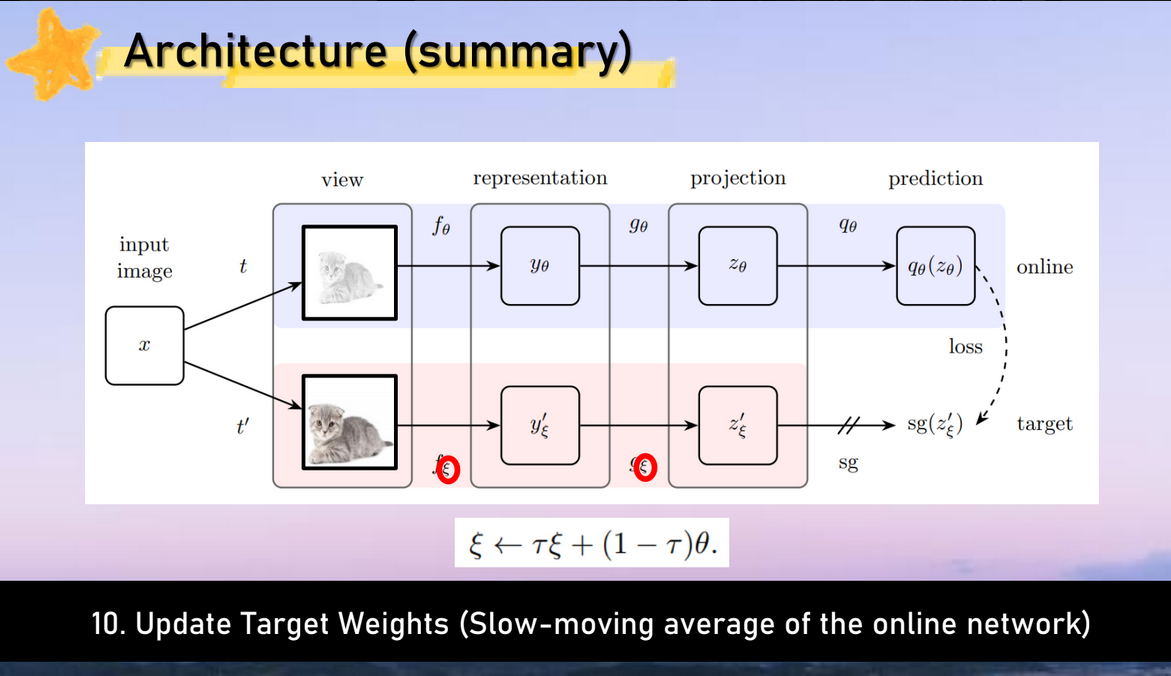
2개의 network를 활용하여 학습하는 방법을 제안





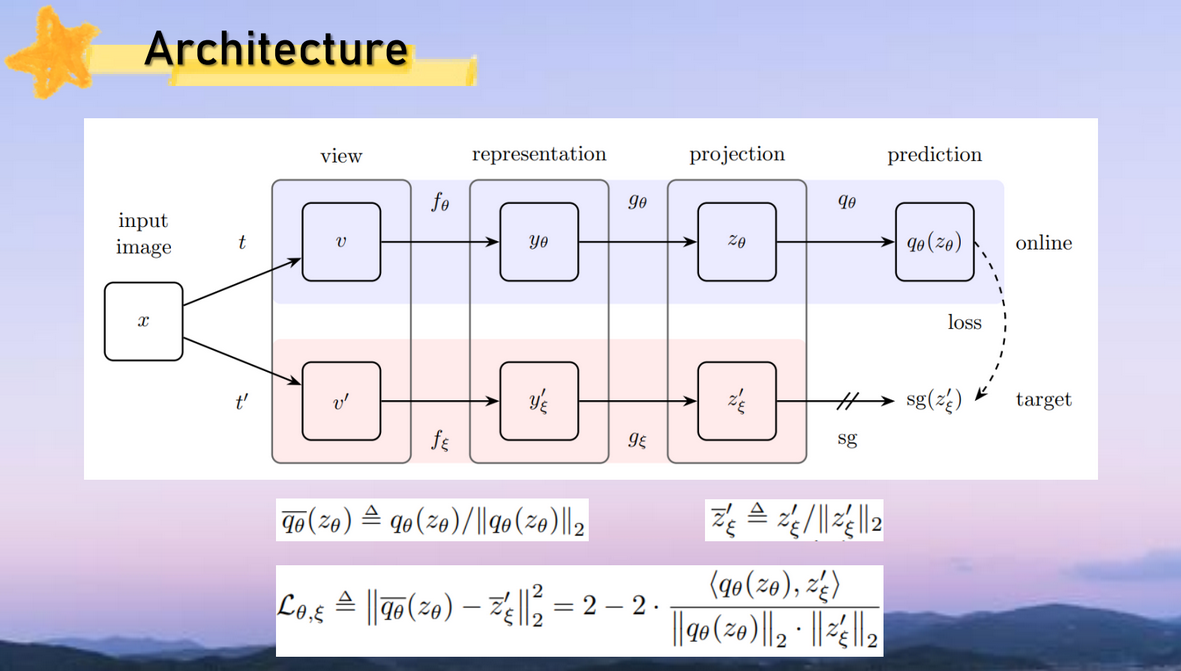

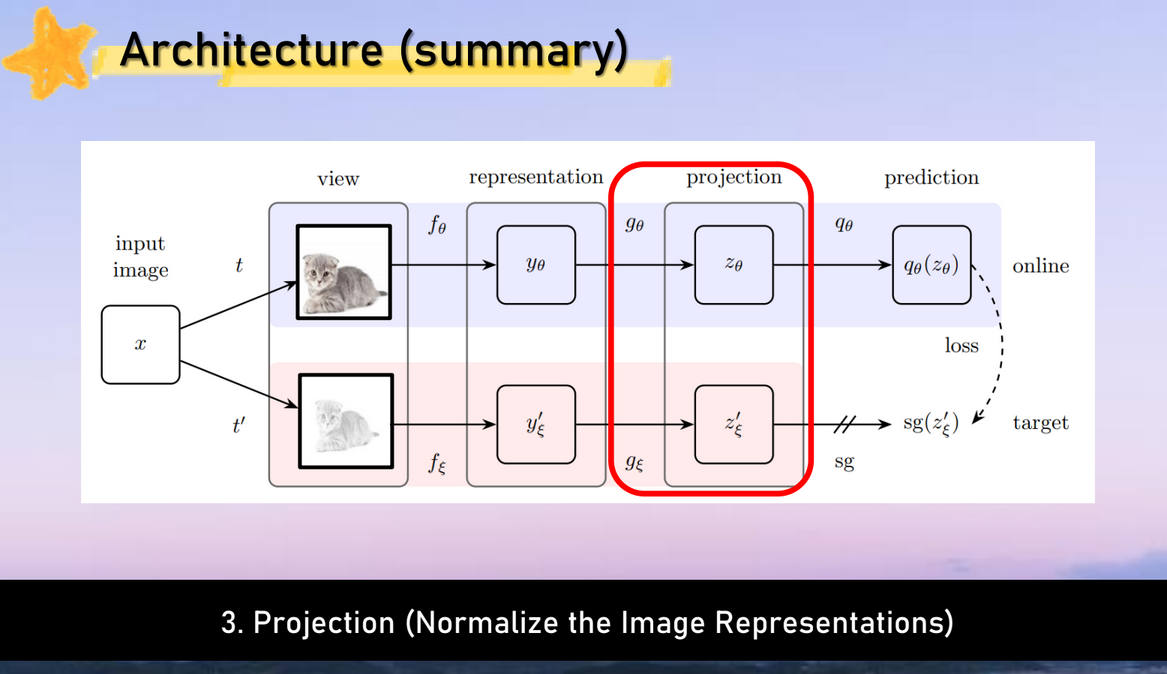
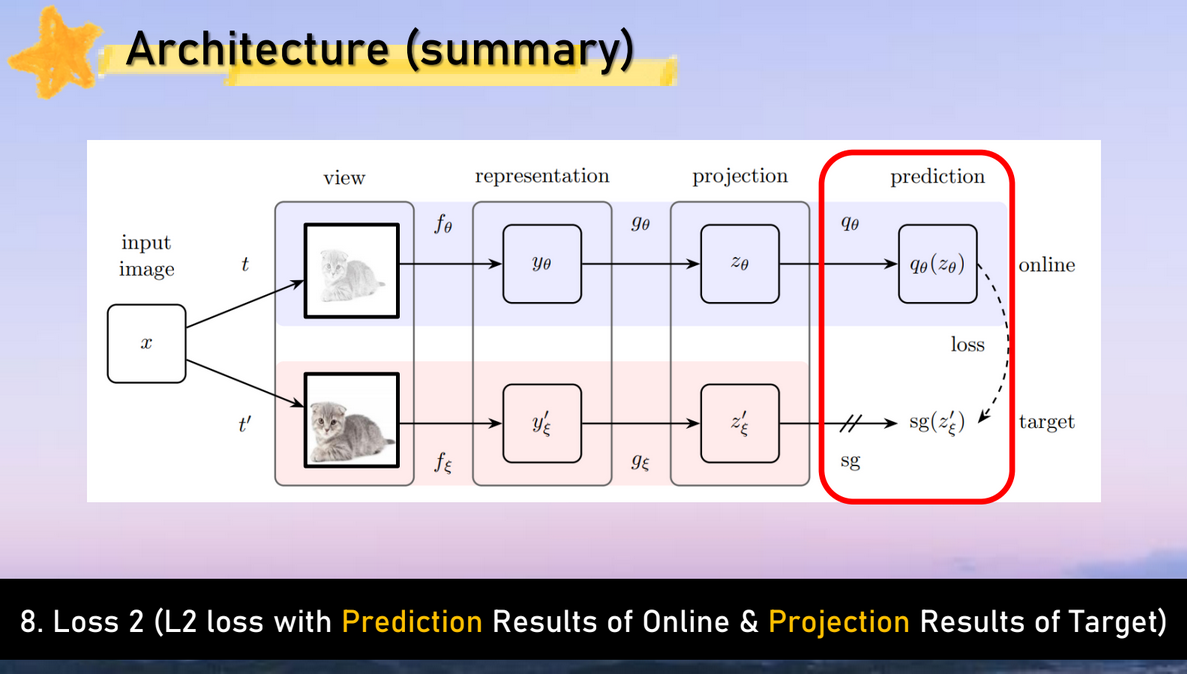
전체 과정 설명








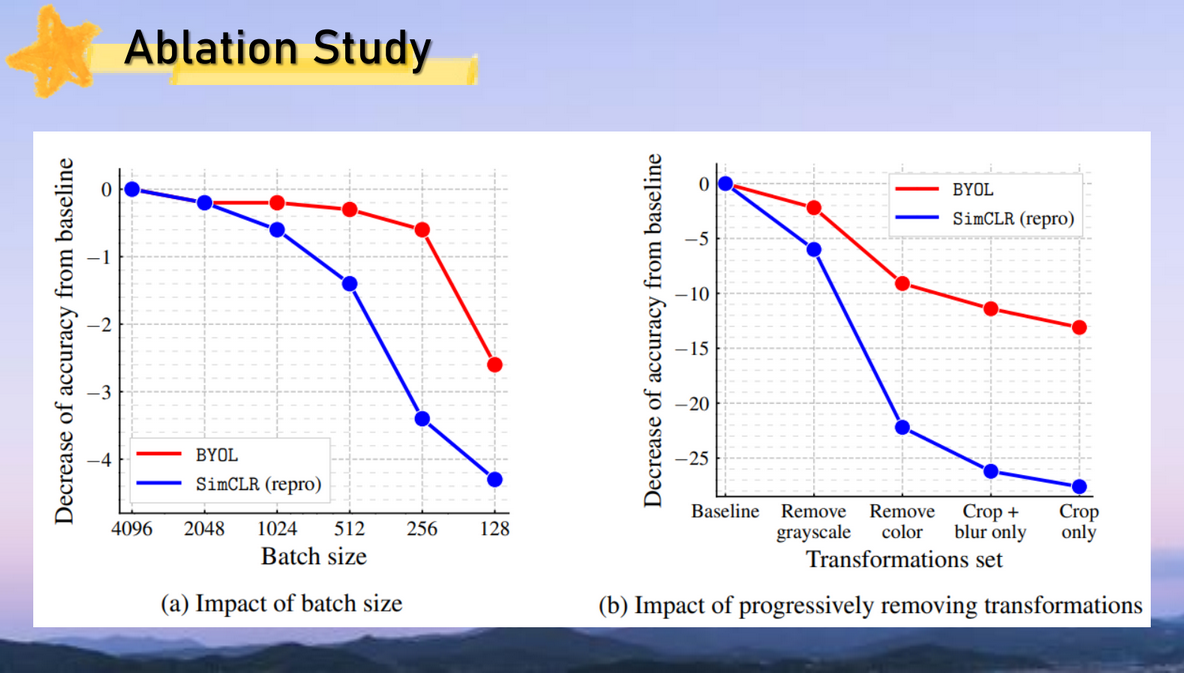
실험 결과


3. Masked Auto Encoder, Masked Autoencoders Are Scalable Vision Learners (FAIR)
논문 링크: https://arxiv.org/abs/2111.06377
Masked Autoencoders Are Scalable Vision Learners
This paper shows that masked autoencoders (MAE) are scalable self-supervised learners for computer vision. Our MAE approach is simple: we mask random patches of the input image and reconstruct the missing pixels. It is based on two core designs. First, we
arxiv.org
ViT 구조의 모델에서 masked된 token을 prediction하는
pretext task를 제안하여 기존보다 좋은 성능을 낼 수 있도록 함.
동기 및 아이디어 설명



실험 결과 설명





- Transformer를 잘 활용하여 SSL을 한 case.
- Analysis 파트가 굉장히 좋으므로 시간이 나신다면 한 번 읽어보아도 좋을 것 같음



