
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- Data-centric AI
- iclr spotlight
- ICLR
- Stable Diffusion
- 자기지도학습
- ai 최신 논문
- iclr 2024
- 논문 리뷰
- Segment Anything
- deep learning 논문 리뷰
- Data-centric
- cvpr 논문 리뷰
- VLM
- Computer Vision 논문 리뷰
- Computer Vision
- Segment Anything 설명
- Segment Anything 리뷰
- cvpr 2024
- Self-supervised learning
- Meta AI
- iclr 논문 리뷰
- active learning
- Prompt란
- Multi-modal
- CVPR
- ssl
- deep learning
- contrastive learning
- 논문리뷰
- Prompt Tuning
- Today
- Total
Study With Inha
[Paper Review] 카카오 브레인 (Kakao Brain) CVPR 2023, Learning to Generate Text-grounded Mask for Open-world Semantic Segmentation from Only Image-Text Pairs 논문 리뷰 본문
[Paper Review] 카카오 브레인 (Kakao Brain) CVPR 2023, Learning to Generate Text-grounded Mask for Open-world Semantic Segmentation from Only Image-Text Pairs 논문 리뷰
강이나 2023. 7. 4. 17:44CVPR 2023 accepted paper, TCL (Text-grounded Contrastive Learning):
Learning to Generate Text-grounded Mask for Open-world Semantic Segmentation from Only Image-Text Pairs
논문링크: https://arxiv.org/abs/2212.00785
Learning to Generate Text-grounded Mask for Open-world Semantic Segmentation from Only Image-Text Pairs
We tackle open-world semantic segmentation, which aims at learning to segment arbitrary visual concepts in images, by using only image-text pairs without dense annotations. Existing open-world segmentation methods have shown impressive advances by employin
arxiv.org
TCL: Text-grounded Contrastive Learning
Introduction
최근 서로 다른 modality들을 같이 다룰 수 있는 multi-modal model들이 많이 연구되고 있다.
특히 잘 학습된 text model과 vision model을 활용하여 (text, image) pair로 다양한 task를 수행하고 있다.
이미지를 넣었을 때 이미지를 설명해주는 텍스트(caption)를 출력해주는 task를 하나의 예로 들 수 있다.
하지만 이미지에서 타겟하는 부분을 text prompt로 입력해주었을 때 해당하는 영역의 segmentation map을 얻고자 하는 경우,
training을 할 때 (text, image) pair 뿐만 아니라 segmentation mask GT도 필요하게 된다.
이렇게 (text, image, segmentation mask)가 모두 주어지는 'supervised method'로 학습될 경우 labeling cost가 높을 뿐만 아니라 train dataset과 test dataset간의 간극이 있는 경우 성능이 떨어지는 문제들이 있다.
실제로 얼마 전 Meta AI에서 발표한 SAM (Segment Anything Model)의 경우 레이블이 존재하는 대규모 데이터셋으로 학습시켜 좋은 성능을 내 주목을 받은 바 있다.
하지만 아직 zero-shot transfer로 평가를 했을 때 text prompt를 활용하여 이미지에서 원하는 영역을 찾아내는 부분에서는 한계가 존재했다.
따라서 본 논문에서는 (text, image) pair만으로 학습시키더라도 원하는 영역을 segment할 수 있는 'unsupervised method'를 제안한다.

정리하자면, 본 논문은 region에 대한 annotation 및 class에 대한 제한 없이 (text, image) pair만으로 open-world에서 text-grounded segmentation (=입력받은 텍스트에 해당하는 object가 이미지에서 어디에 있는 것인지 찾아내는 task)를 하려고 한다.
여기서 'Open-world' (=Open-vocabulary)란 class 개수나 카테고리 등에 제한을 두지 않고 학습시킴으로써 free-form text에 대해서도 inference가 가능하도록 한다는 것을 뜻한다.
정해진 class에 대해서 학습한 모델의 경우 아래의 두 번째 그림처럼 'dog'라는 클래스는 있어서 거기에 대한 segmentation mask를 생성하는 것은 가능하나,
'corgi'나 'shepherd'와 같이 개의 종류까지는 학습시에 포함되지 않았기 때문에 free-form text로 semantic segmentation을 수행하는 것이 어려워진다.
하지만 input text와 region간의 align을 잘 맞추는 unsupervised method로 Open-world에 대한 task를 수행할 수 있도록 만들어진 본 논문의 TCL이라는 모델의 경우에는 어떤 형식으로 text를 넣든지 아래의 세 번째 그림과 같이 원하는 영역을 얻어낼 수 있다는 장점이 있다.


Methods
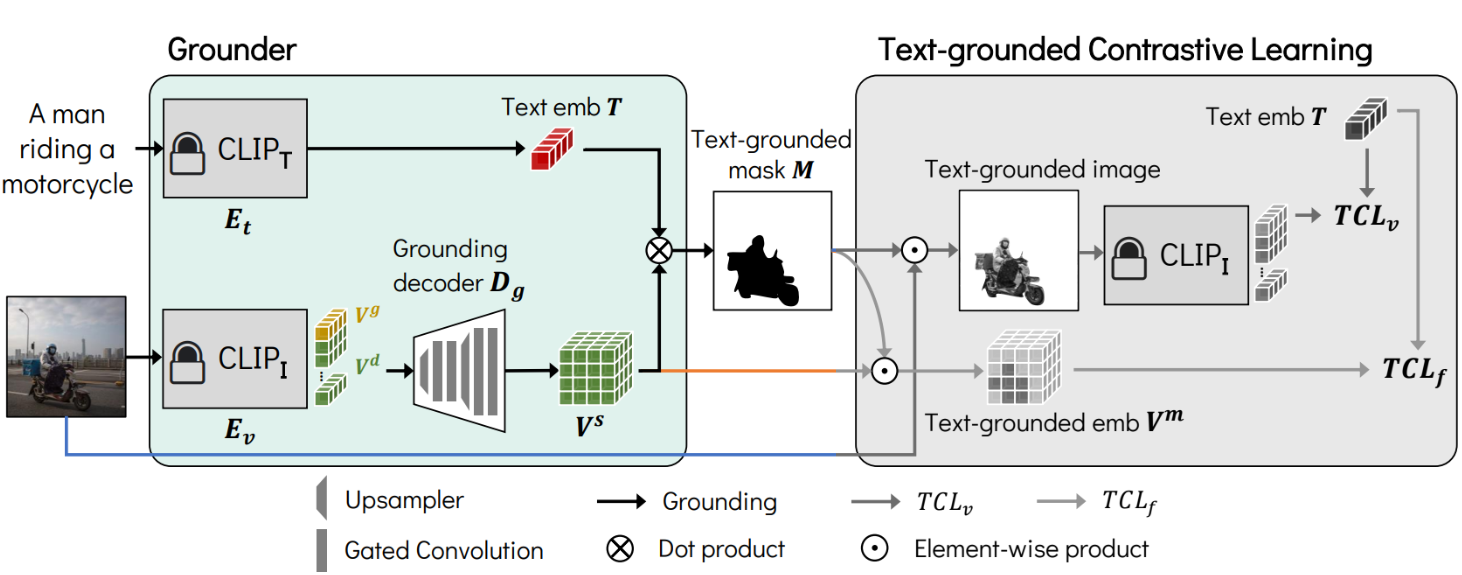
1. Grounder
Grounder는 입력한 텍스트에 해당하는 영역, 즉 text-grounded mask($M$)을 찾아내는 과정으로 총 3가지 요소로 구성되어 있다.
- CLIP Text Encoder ($CLIP_{T}$): CLIP의 텍스트 인코더를 고정(froze)시키고 사용
- CLIP Image Encoder ($CLIP_{I}$): CLIP의 이미지 인코더를 고정(froze)시키고 사용
- Grounding Decoder ($D_{g}$): 이미지 인코더를 통해서 얻은 축소된 차원의 임베딩 벡터를 디코딩하는 역할. Grounding Decoder의 결과로 얻은 벡터와 텍스트 임베딩 벡터 간의 Dot product를 적용한 결과가 올바른 text-grounded mask를 생성하도록 학습된다.
2. Text-grounded Contrastive Learning
Grounder 단계를 거쳐서 얻은 text-grounded mask($M$)를 활용하여 image-level의 conatrastive learning과 feature-level의 conatrastive learning을 수행하는 단계다.
- $TCL_{v}$ (Image-level Contrastive Learning)
- Gumbel-Max를 통해서 $M_{i,i}$를 binary mask화한 것과 원본 이미지를 elemental-wise product하여 Text-grounded Image를 얻어낸다.
- Text-grounded Image를 (frozen) CLIP 인코더에 통과시키고 text-grounded image embedding을 얻는다.
- InfoNCE로 text-grounded image embedding과 text embedding 간의 similarity matrix를 계산한 것이 $TCL_{v}$이 된다.
- $TCL_{f}$ (Feature-level Contrastive Learning): Image-level Contrastive Learning을 통해서 text에 해당하는 mask를 얻어낼 수 있지만, negative 부분도 모두 포함시키려는 경향이 있어 negative에 대한 피드백을 주기 위해서 추가한 스텝
- $M_{i, j}$에서 $i \neq j$인 부분에 대해서 feaure-level text-grounded image embedding을 계산하여 negative pair에 대한 임베딩을 얻는다.
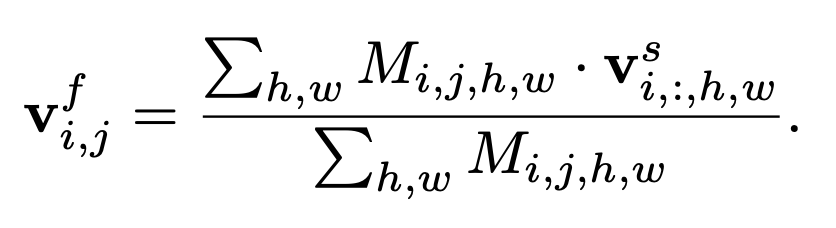
2. 위 과정에서 얻은 text-grounded image embedding과 text embedding간에 InfoNCE를 계산해 similarity loss를 구한다.
3. Area TCL loss
Trivial solution, 즉 이미지 전체를 positive region으로 보는 것에 빠지는 것을 방지하기 위한 loss이다
- $\bar{M^{+}}$: positive mask인 영역
- $\bar{M^{-}}$: negative mask인 영역
- $p^{+}$: positive area prior
- $p^{-}$: negative area prior

4. Smooth Regularization
Image-Text가 pair로 제공되는 데이터셋들의 경우 대개 text는 이미지의 중요한 부분이나 개념을 설명하고 있다고 말한다.
이 때 이미지에서 text에 해당하는 region들은 noisy하기보다는 smooth하다는 것을 발견하여 이와 같은 regularization을 추가했다고 한다.
(아마 텍스트에 해당하는 픽셀들은 이미지에서 흩뿌려져 있지 않고 부드럽게 모여져 있다는 의미인 것 같다)
- $Total\ Variation$ ($TV$): object의 smoothness를 regulate하기 위하여 도입. mask 결과($M$)와 pixel-level dense embedding($V^{S}$)에 모두 적용됨.
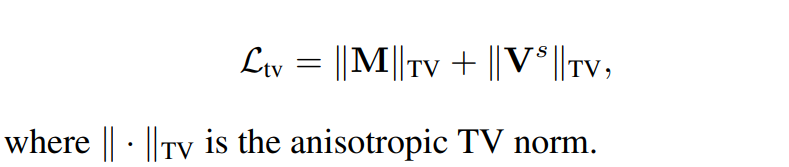
Final Loss
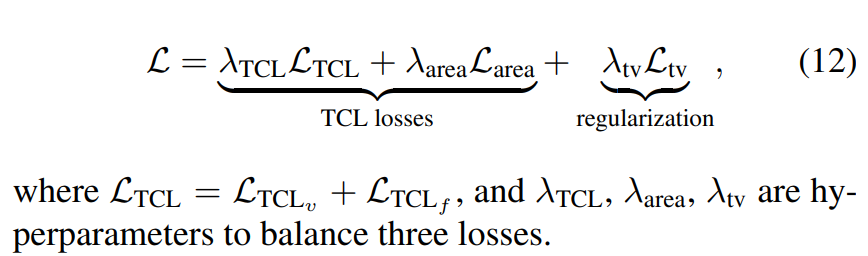
Inference Pipeline
- Training에서 사용되었던 TCL 파트 (회색으로 표시된 블럭)은 사용하지 않고, Grounder의 결과(컬러로 표시된 블럭)를 inference 결과로 사용하게 된다.
- 즉, Text-grounded mask ($M$)이 test 시의 마스크가 된다.
Experiments
- Implementation Details
- Grounder: CLIP ViT-B/16 (224 x 224 input image with 16 x 16 patch size)
- Grounding Decoder: four gated convolution blocks with two upsampling interpolations + pixel-adaptive mask refinement (PAMR) for mask refinement
- Training Dataset: CC3M + 12M datasets
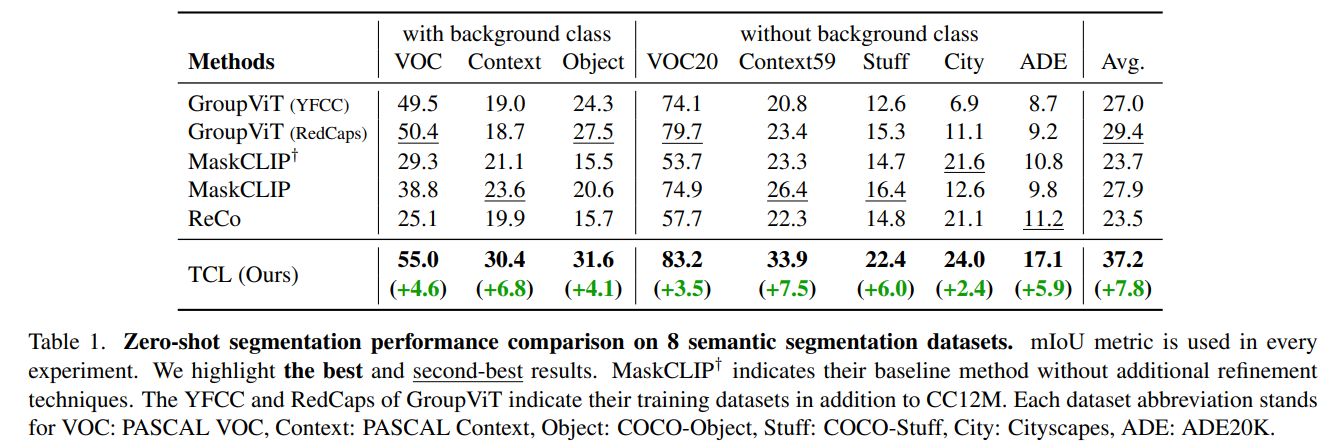
Zero-shot Transfer to Semantic Segmentation
- GroupViT: VOC, VOC20, 그리고 COCO-object와 같이 object-oriented dataset에서는 높은 성능을 보임. 하지만 stuff classes(잔디, 하늘과 같이 배경인 classes)에 대해서는 낮은 성능을 보임
- MaskCLIP: Context, Context59, COCO-stuff와 같이 stuff-oriented dataset에서 높은 성능을 보임. MaskCLIP의 refinement technique들은 대부분 좋은 성능을 보였으나 Cityscape에서는 21.6에서 12.6으로 낮아지는 결과를 보였는데 이는 heuristic refinement 방법들의 한계를 보여주는 것이라고 설명
- ReCo: MaskCLIP 방법론들에 비해서 VOC와 VOC20과 같이 background를 포함한 데이터셋에서 많은 성능 하락이 있었음.
- TCL (Ours): 가장 높은 성능을 보임. train 데이터셋과 test 데이터셋간의 간극을 최소화하며 잘 학습된 것이라고 말할 수 있음. 또한 background도 잘 구별해 냈는데, 이는 data-driven manner로 학습되었기 때문에 heuristic post-processing보다 좋은 성능을 낸 것으로 설명
Qualitative Results
- Visualization of the generated text-grounded masks
- target하지 않는 부분은 보지 않고 target하는 부분만 보고 있는 것을 시각적으로 확인할 수 있음

- Qualitative Comparison
- Fig 5b에서와 같이 free-form test sample에서도 좋은 성능을 보인다는 것을 알 수 있음. 이 때 moon, sunset같은 것은 보통의 데이터셋에 포함되어 있지 않은 클래스임에도 불구하고 좋은 성능을 보임.

Ablation Study
- Baseline: initial model before training based on MaskCLIP
- + Decoder: add grounding decoder
- +TCL: 모든 TCL loss를 다 더한 것




