| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Segment Anything 리뷰
- deep learning 논문 리뷰
- contrastive learning
- Segment Anything
- Self-supervised learning
- Computer Vision
- 자기지도학습
- ssl
- deep learning
- iclr 논문 리뷰
- iclr 2024
- Multi-modal
- ICLR
- Data-centric
- cvpr 2024
- iclr spotlight
- Computer Vision 논문 리뷰
- Prompt Tuning
- 논문 리뷰
- CVPR
- Prompt란
- active learning
- Data-centric AI
- 논문리뷰
- ai 최신 논문
- Stable Diffusion
- Segment Anything 설명
- Meta AI
- VLM
- cvpr 논문 리뷰
- Today
- Total
Study With Inha
[Paper Review] 고해상도 결과를 얻을 수 있는 Segment Anything 후속 연구, HQ-SAM 논문 리뷰 본문
[Paper Review] 고해상도 결과를 얻을 수 있는 Segment Anything 후속 연구, HQ-SAM 논문 리뷰
강이나 2023. 7. 27. 12:17Segment Anything in High Quality, ETH Zurich
논문링크: https://arxiv.org/abs/2306.01567
Segment Anything in High Quality
The recent Segment Anything Model (SAM) represents a big leap in scaling up segmentation models, allowing for powerful zero-shot capabilities and flexible prompting. Despite being trained with 1.1 billion masks, SAM's mask prediction quality falls short in
arxiv.org
Introduction
올해 상반기에 Meta AI에서 발표한 'SAM (Segment Anything Model)'이 뛰어난 Zero-shot Segmentation 성능을 보이면서 다양한 후속 연구들이 쏟아졌다.
HQ-SAM도 SAM의 후속 연구 중 하나로, HQ-SAM는 기존의 SAM 모델의 얇은 선과 같은 디테일한 부분에서 성능이 떨어지는 문제를 극복하고자 했다고 한다.

전체를 재학습하는 방법을 선택하기보다는 0.5% 미만의 파라미터를 추가하여 high quality segmentation을 위한 학습을 진행했다고 한다.
이처럼 잘 학습된 SAM weight는 그대로 가져가되, 추가된 파라미터만을 학습하는 방식을 채택하여 경제적으로 성능을 향상시켰다.
마지막으로 fine-grained mask를 얻기 위해서 44K개의 high-quality dataset인 'HQSeg-44k'를 구축하여 모델을 학습했다고 설명한다.
Related Works
1. Prompt Tuning
Visual Prompt Tuning은 말 그대로 이미지를 처리하는 모델에서 prompt와 함께 학습시키는 것을 말한다.
이 때, Prompt는 다양한 형태로 줄 수 있다.
타겟하는 영역을 point, bounding box, mask와 같은 prompt 형태로 정보를 제시해 줄 수도 있고,
text, voice와 같이 다른 모달리티의 prompt 형태로도 정보를 제시해 줄 수 있다.
Prompt Tuning의 장점은 같은 이미지라도 prompt를 주는 것에 따라 다른 결과를 얻을 수 있다는 것이다.
예를 들어서, 개와 고양이가 함께 있는 이미지에서 '개'만을 추출해 내고 싶을 때,
개 영역에 해당하는 bounding box prompt나 'dog'라는 text prompt 등 개를 특정할 수 있는 프롬프트를 입력하면 개에 대한 결과를 얻을 수 있고,
반대로 같은 이미지라 하더라도 고양이를 특정할 수 있는 프롬프트를 입력하면 고양이에 대한 결과를 얻을 수 있다.
이 말은 높은 zero-shot transfer 능력을 가지고 있어 inference 시에 자유도가 굉장히 높아진다는 것을 뜻한다.
예를 들어서, task-specific하게 훈련된 모델의 경우 training data에 포함된 class를 맞추는 것에만 최적화되어 있는데,
prompt 기반으로 대규모 데이터셋에 대해 학습시킨 모델의 경우 training data에 포함되어 있지 않는 이미지나 클래스에 대해서도 유연하게 대연할 수 있다고 한다.
Prompt Tuning은 LLM(large language model)이나 vision에서도 널리 사용되고 있는 개념이므로,
이전 포스팅도 읽어보면 큰 도움이 될 것 같다.
[Paper Review] Visual Prompt Tuning, ECCV 2022 논문 리뷰
[Paper Review] Visual Prompt Tuning, ECCV 2022 논문 리뷰
ECCV 2022, Visual Prompt Tuning, M. Jia et al. 논문 링크: https://arxiv.org/pdf/2203.12119.pdf 1. Introduction 최근 GPT 계열 모델과 같이 대규모 데이터와 대규모 모델을 활용한 딥러닝 연구가 많아졌다. 그러한 데이터
2na-97.tistory.com
2. SAM
Meta AI에서 2023년 상반기에 공개한 Segment Anything Model은 prompt tuning을 도입한 segmentation model이다.
SAM은 이미지를 입력으로 받는 Image Encoder, 프롬프트를 받는 Prompt Encoder,
그리고 인코더를 통과한 이미지 임베딩과 프롬프트 임베딩을 입력으로 받아 최종 마스크를 출력하는 Mask Decoder로 이루어져 있다.
Segment Anything 초안 모델에서는 point, bounding box, mask의 형태로 prompt를 주는 것을 메인으로 하고 있고,
공개된 깃헙 코드에서는 point와 bounding box만 있지만 간단한 수정을 통해서 mask를 prompt로 주는 것 까지 가능하다.
여러 형태의 prompt를 동시에 주는 것도 가능하며 (point+bounding box),
프롬프트를 입력하지 않을 시 이미지 전체에 대한 segmentation map을 결과로 얻을 수 있다.
Segment Anything에 대한 설명은 아래 포스트에서 확인할 수 있으며, 본 포스팅을 잘 이해하기 위해서는 아래 포스팅을 꼭 읽어보는 것을 권장한다.
[Paper Review] Segment Anything Model (SAM) 자세한 설명, Meta AI 논문 리뷰
[Paper Review] Segment Anything Model (SAM) 자세한 설명, Meta AI 논문 리뷰
Meta AI, Segment Anything, Alexander Kirillov et al. 논문 링크: https://ai.facebook.com/research/publications/segment-anything/ 1. Introduction 2023년 4월 5일에 Meta AI가 공개한 Segment Anything이라는 논문은 모든 분야에서 광범위
2na-97.tistory.com
Methods
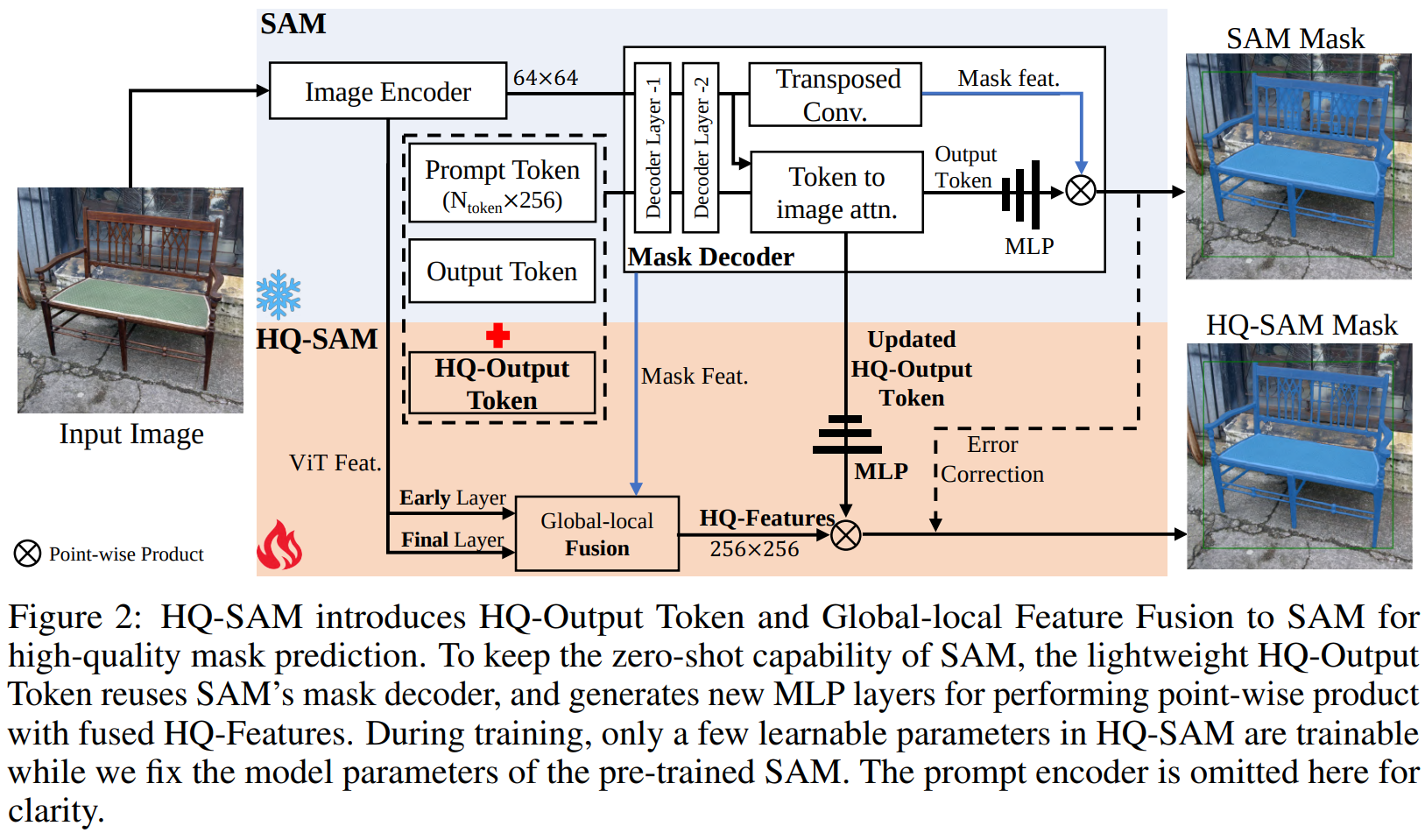
SAM의 높은 zero-shot transfer 능력을 그대로 유지하면서 detail에 대한 능력만 추가적으로 학습하기 위해서,
기존 SAM에 'High-Quality Output Token'과 'Global-local Fusion'만 추가로 도입하여 해당 부분만 학습시켰다고 한다.
1. High-Quality Output Token
기존 SAM은 prompt token($N_{prompt} \times 256$)과 output token($4 \times 256$)만을 concat하여 decoder에 넣어주었는데,
여기에 HQ-Output token ($1 \times 256$)을 새롭게 도입하여 학습시켜주었다고 한다.
HQ-Output token은 아래와 같은 단계를 거쳐 얻을 수 있다.
- 다른 토큰들과 self-attention 수행
- token-to-image attention 수행
- image-to-token attention 수행
이렇게 얻은 prompt token + output token + HQ-Output token 형태로 point-wise concat되어 SAM의 decoder layer에 입력된다.
추가적으로, global image context에 대해 HQ-Output token을 업데이트 하기 위해서 3-layer MLP를 활용했다고 한다.
이 3-layer MLP같은 경우는 SAM의 output token이 잘못 예측한 마스크를 바로잡기 위해서 학습된다.
이와 같은 가벼운 MLP layer만 학습시키기 때문에 training time을 아낄 수 있으며
특정 데이터셋에 오버피팅되지 않기 때문에 SAM의 기존 능력은 보존하면서도 error를 보정하는 방향으로 잘 학습할 수 있었다고 한다.
2. Global-local Fusion for High-quality Features
이미지의 edge와 boundary detail (local features)들과 global context를 동시에 잘 학습할 수 있도록 하기 위해서
SAM 이미지 인코더의 early layer의 정보와 final layer의 정보를 합쳐서 사용했다고 한다.
early layer의 경우 24개의 블록으로 이루어진 SAM 이미지 인코더의 6번째 블록의 아웃풋을 사용했다고 하며,
이것을 global feature를 갖고 있는 finaly layer와 elemnt-wise 합쳐서 사용하게 된다.
이처럼 크기가 다른 feature들을 합치기 위해서 transposed convolution을 통해 upsampling 시켜 256 x 256 사이즈로 만들어 합치는 과정을 거쳤다고 한다.
3. Training Data and Inference
효과적인 학습을 위해 SAM이 학습 시에 사용한 SA-1B를 그대로 사용해서 학습하기보다는 새로운 HQSeg-44K 데이터를 구축하고, 이에 대해서 학습을 시켰다고 한다.
HQSeg-44K 데이터셋은 현존하는 데이터셋 중 fine-grained mask labeling을 갖고 있는 6개의 이미지 데이터셋을 합쳐서 만들었다.
최종적으로 HQ-SAM에서 학습되는 것은 3-layer MLP, 그리고 3개의 conv로 이루어진 HQ-Features fusion 뿐이다.
HQ-SAM도 SAM과 같이 flexible한 prompt에 대해서 학습하기 위해서 points, bounding box, 그리고 coarse mask들을 randomly sampling하여 사용했다.
Inference 시에는 SAM의 mask 결과와 HQ-Output Token이 예측한 mask 결과를 합하여 최종 마스크로 산출했다.

Experiments
Experimental Setup
- Datasets: Extremely fine-grained dataset과 general한 데이터셋에 대해서 성능 평가함
- Extremely fine-grained segmentation dataset: DIS (valid set), ThinObject-5K (test set), COIFT, HR-SOD
- Popular & Challenging Benchmakrs: COCO, UVO, LVIS, HO-YTVIS, BIG
- Evaluation Metrics: 일반적인 mIoU, AP와 더불어서 다른 metric도 사용함
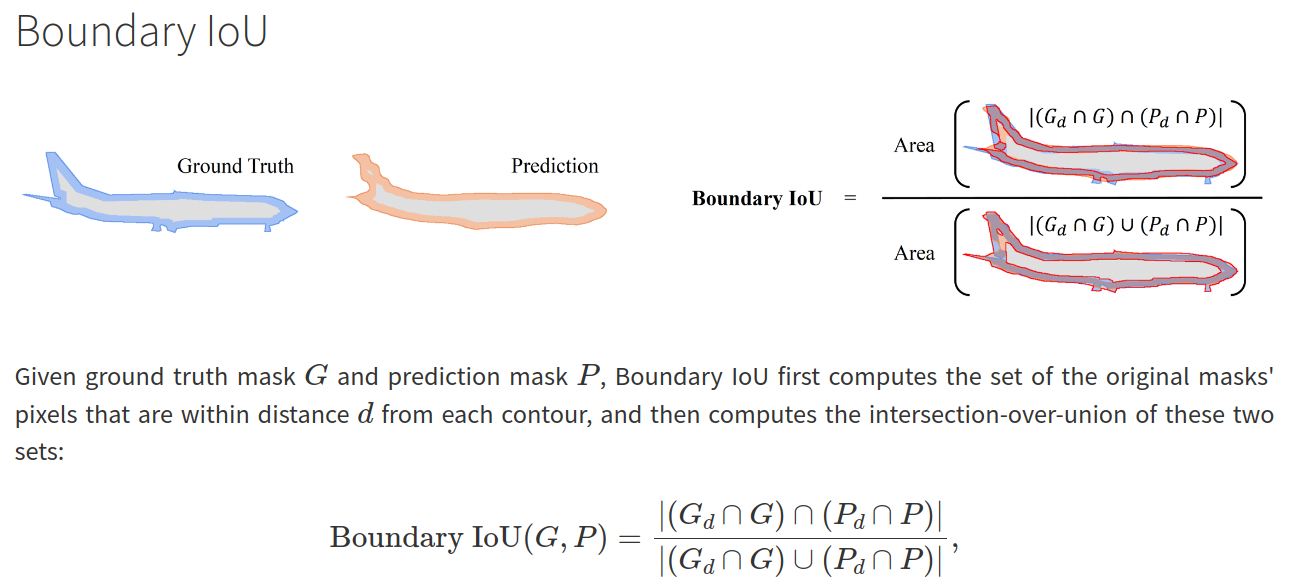
- $AP^{strict}_{B}$의 경우 dilation ratio를 0.02에서 0.01로 조절한 조금 더 strict한 기준이다.
Ablation Study
Effect of the High-Quality Output Token.
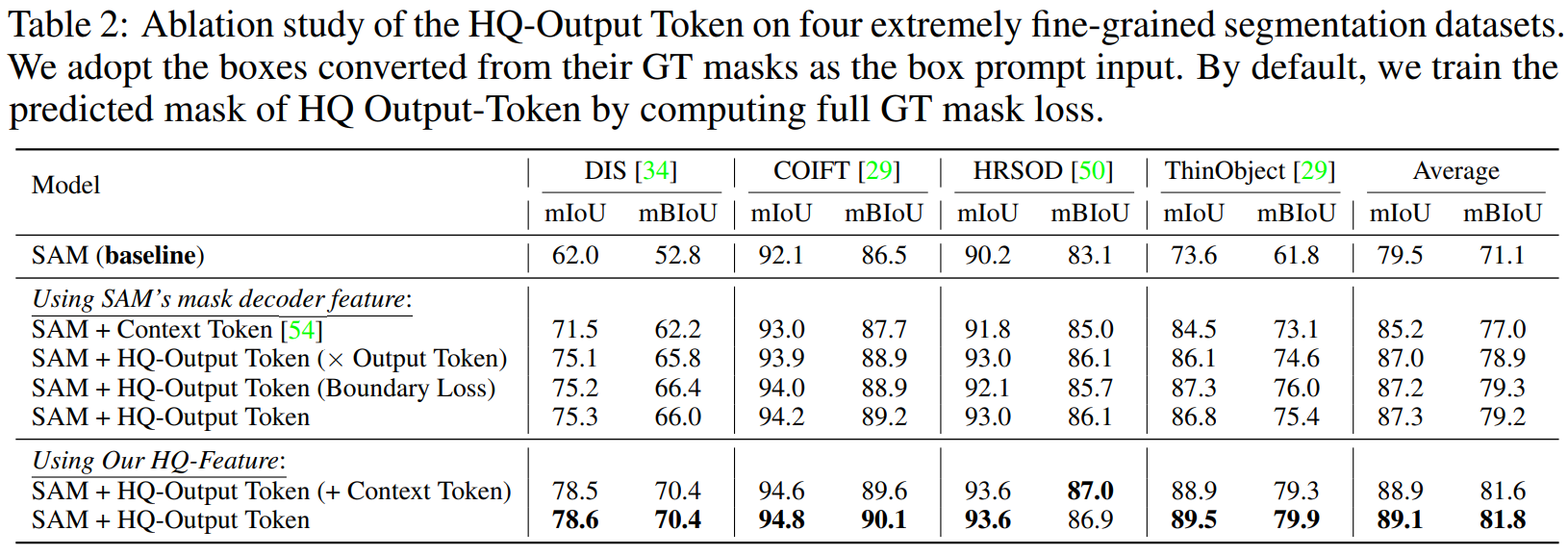
HQ-output token의 성능을 평가하기 위해서 현존하는 prompt/token learning 방법인 Context Token과 비교를 진행했다고 한다.
Context Token 방법을 도입한 것보다 HQ-Output Token을 활용한 방법들이 더 높은 성능을 보였다.
또한 HQ-Output Token을 활용할 때 original SAM의 output에 dot product를 하는 것과,
boundary region 안쪽에 대한 mask의 loss를 계산하여 학습하는 것도 시도해 보았는데 제안한 방법보다는 약간 낮은 성능을 보였다고 한다.
Ablation on the Global-local Fusion for HQ-Features.

SAM 디코더의 feature를 바로 사용하는 것보다 HQ-Feature를 사용했을 때 mBIoU가 2.6정도 상승했다.
Fusion conv을 도입하고, Final layer와 Early layer를 모두 사용하는 것이 가장 좋은 성능을 보인다.
Comparison to SAM finetuning or post-refinement.
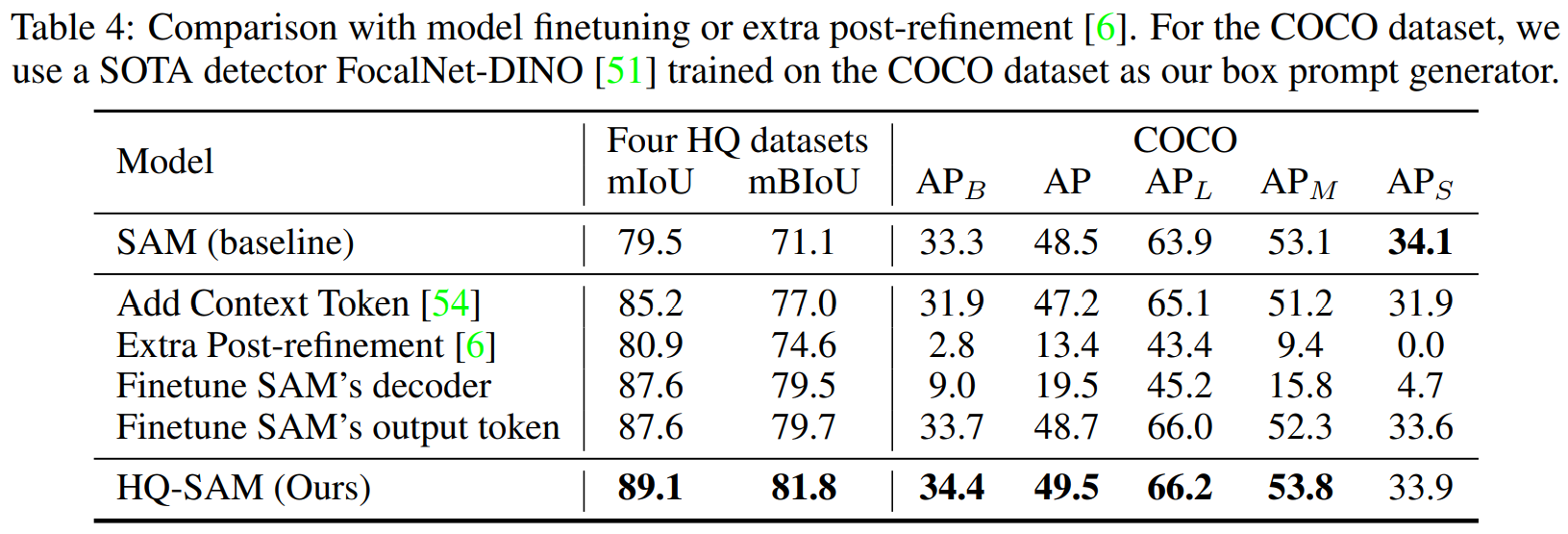
heavy한 post-refinement 네트워크를 추가했을 때 Four HQ dataset에 대해서는 높은 성능을 보이나, COCO에 대해서는 아주 낮은 성능을 보이고 있으므로 overfitting이 되었다고 할 수 있다.
SAM의 decoder를 직접적으로 finetuning했을 때도 비슷한 결과를 볼 수 있었다.
SAM의 output token만을 finetuning했을 때는 overfitting 현상은 덜했으나 여전히 HQ-SAM보다는 낮은 성능을 보이고 있다.
Accuracy analysis at different BIoU thresholds.
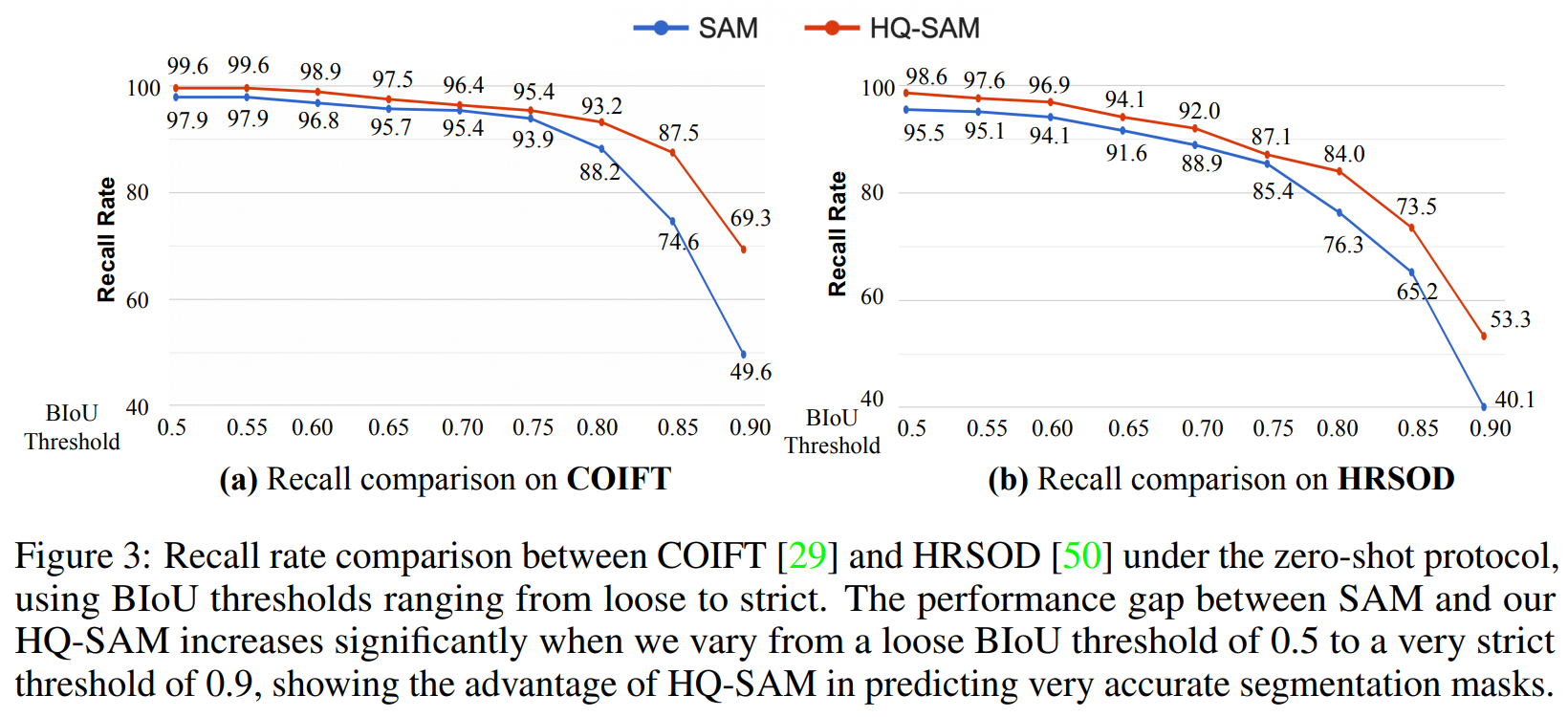
strict한 BIoU threshold값을 설정할수록 HQ-SAM의 성능이 더 좋다는 것을 확인할 수 있다.
Zero-shot Comparision with SAM
Zero-shot Open-world Segmentation
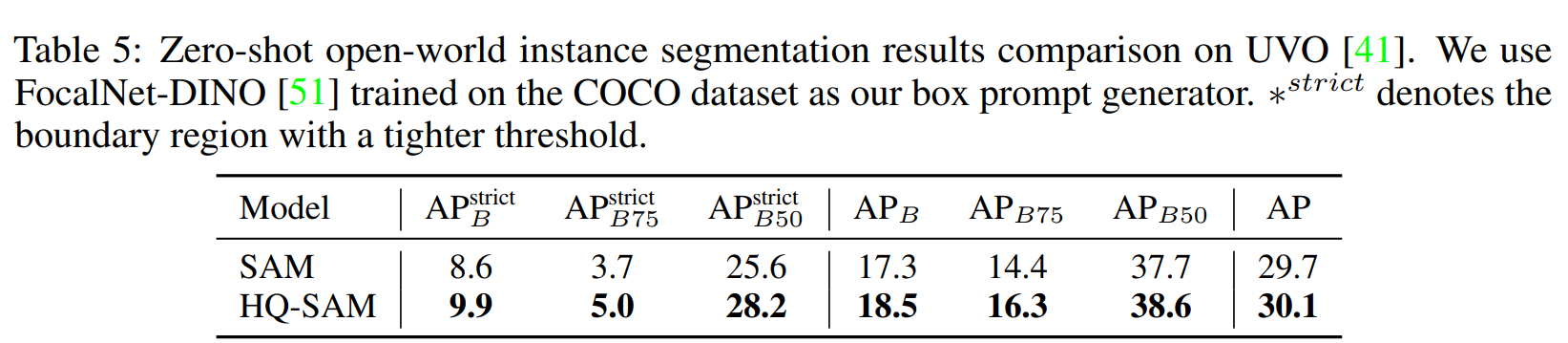
Diverse and Dense objects mask annotation을 가지고 있는 UVO 데이터셋에 대해서 성능을 평가했다.
같은 object detector를 사용하여 bbox를 prompt로 주었을 때, HQ-SAM이 더 좋은 성능을 보였다.
Zero-shot Visual Results Comparison

HQ-SAM이 broken hole이나 large portion error같은 경우를 잘 보완해주었다.
(Appendix) Effect of HQSeg-44K
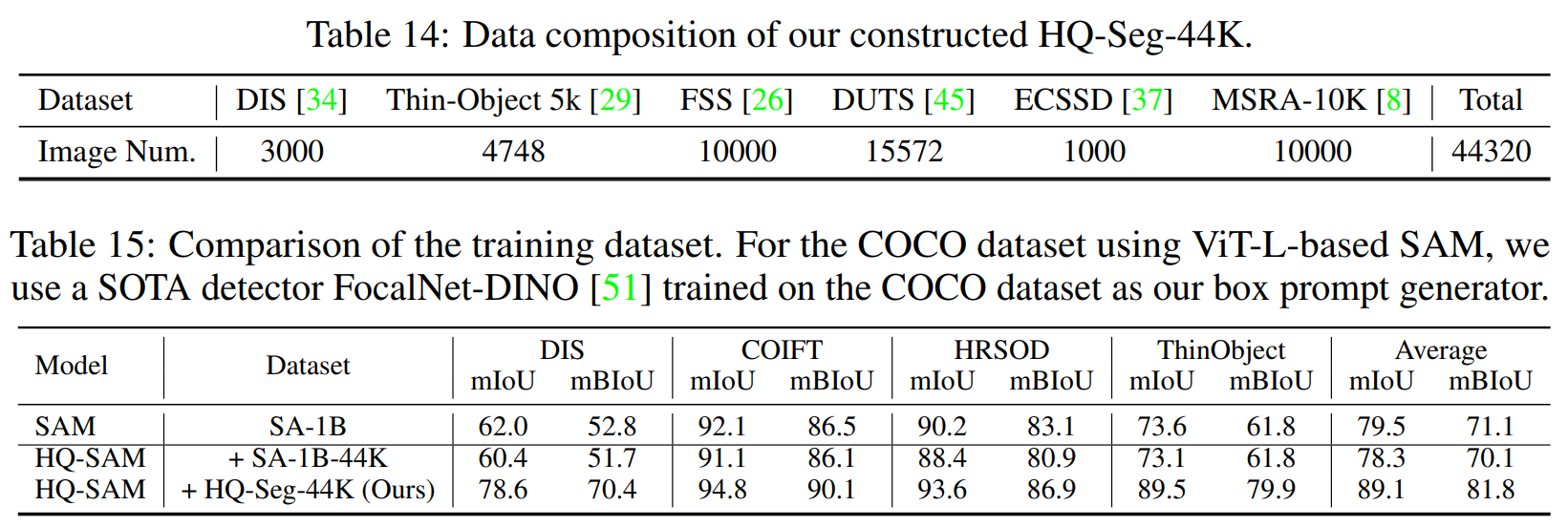
HQSeg-44K에 사용된 데이터셋과 training data를 서로 달리 하였을 때의 결과를 보여준다.
기존 SAM의 경우 SA-1B에 대해서 학습을 했고, HQ-SAM은 이렇게 학습된 weight를 freeze한 채 HQ Token만 추가적으로 학습하게 된다.
SA-1B에서 44K개를 랜덤으로 골라서 학습시켰을 때와 HQ-Seg-44K 데이터셋으로 학습시켰을 때를 비교했을 때 HQ-Seg에서 훨씬 더 높은 성능을 보이고 있다.
SA-1B-44K로 학습시킨 것은 오히려 기존 SAM보다 낮은 성능을 보이고 있는데,
이런 것을 보았을 때 HQ-SAM의 방법론들보다 HQSeg-44K라는 Fine-grained annotation을 포함하는 데이터셋으로 학습시킨 것이 성능 향상에 더 큰 영향을 끼친게 아닌가? 라는 생각을 하게 되었다...
Conclusion
적은 양의 파라미터만 추가 학습하여서 SAM이 잘하던 것들의 성능은 유지하되, 부족했던 detail에 대한 성능 향상만 이뤄질 수 있도록 하는 HQ-SAM을 제안했다.
하지만 HQ-SAM은 SAM의 heavy한 ViT 인코더를 학습만 시키지 않을 뿐 inference 시에 사용해야 하기 때문에, real-time으로 inference 결과를 얻기에는 무리가 있다는 한계점이 존재한다.