
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Computer Vision
- Prompt Tuning
- Segment Anything 설명
- ai 최신 논문
- active learning
- Self-supervised learning
- cvpr 논문 리뷰
- ssl
- iclr spotlight
- Prompt란
- 자기지도학습
- Segment Anything
- iclr 2024
- VLM
- deep learning 논문 리뷰
- contrastive learning
- Multi-modal
- Meta AI
- Stable Diffusion
- Computer Vision 논문 리뷰
- CVPR
- Segment Anything 리뷰
- 논문 리뷰
- ICLR
- iclr 논문 리뷰
- Data-centric AI
- Data-centric
- deep learning
- cvpr 2024
- 논문리뷰
- Today
- Total
Study With Inha
[Paper Review] NeurIPS 2023, StableRep: Synthetic Images from Text-to-Image Models Make Strong Visual Representation Learners 논문 리뷰 본문
[Paper Review] NeurIPS 2023, StableRep: Synthetic Images from Text-to-Image Models Make Strong Visual Representation Learners 논문 리뷰
강이나 2024. 2. 13. 17:36Google Research, NeurIPS 2023 accepted
StableRep: Synthetic Images from Text-to-Image Models
Make Strong Visual Representation Learners
논문 링크: https://arxiv.org/pdf/2306.00984.pdf
StableRep은 NeurIPS 2023에 accept된 논문으로 LG AI Research에서 정리한 NeurIPS 2023 주요 연구주제에 선정된 논문이다.
LG AI 리서치 블로그: https://www.lgresearch.ai/blog/view?seq=379
[NeurIPS 2023] 주요 연구 주제와 주목할 만한 논문 소개 - LG AI Research BLOG
NeurIPS 2023, 연구 논문, Large Language Model, Large Multimodal Model, Diffusion Model, Reinforcement Learning, Computer Vision
www.lgresearch.ai
좋은 Data를 만드는 것은 Machine Learning 성능을 높이는 데에 주요한 역할을 한다.
1990년대에는 데이터셋을 생성하기 위해서 실제로 target object에 대해서 사진을 찍어 수집을 해야 했고, 2000년대에는 인터넷에서 crawling해서 다양한 이미지를 얻을 수 있었으나 다소 noisy하고 uncurated 이미지라는 단점이 있었다.
이러한 web dataset에 대해서 noisy한 데이터를 제거하거나 labeling을 해주는 작업을 거쳐 데이터셋을 만들 수도 있지만, 이 경우 많은 human cost가 들게 된다. 따라서 본 논문에서는 Natural Language Prompt를 입력으로 받아 Stable Diffusion이 생성한 Synthetic Images로 학습 데이터셋을 구성하는 StableRep을 제안한다.

StableRep은 같은 Text Promp로 여러 개의 이미지를 생성할 수 있기 때문에, 손 쉽게 multi-positive pair를 만들 수 있다. 이러한 장점을 활용하여 Multi-positive Contrastive Learning을 진행했을 때 높은 성능을 얻을 수 있었다고 한다.
StableRep이 가지는 장점과 Contribution은 아래와 같다.
🎬 StableRep의 Contribution
- Stable Diffusion을 통해 생성한 Synthetic Image를 사용하여 SSL 방법들을 사용했을 때 효과적임을 밝힘. 심지어 같은 sample size를 가진 데이터셋일 때 Real Image를 사용했을 때보다 Synthetic Image를 사용하는 것이 더 좋은 성능을 보였다고 함.
- 같은 텍스트 프롬프트로 생성한 이미지라 하더라도 다양한 이미지를 얻을 수 있었고, 이러한 multi-positive pair를 활용한 contrastive learning으로 좋은 representation을 학습할 수 있었음을 보임.
- 10M의 캡션으로 생성한 20M개의 synthetic image로 학습된 StableRep과 50M개의 캡션과 50M개의 real image로 학습된 CLIP을 비교했을 때, StableRep이 더 좋은 성능을 보였다고 함.
2. Standard Self-supervised Learning on Synthetic Images
보통의 Representation Learning Algorithm은 Input image를 입력으로 받고, 인코더(F)를 거친 Embedding Vector를 출력하게 된다.
StableRep에서는 인코더(F)를 학습시킬 때 real image가 아닌 synthetic image(x)를 사용하게 된다. 입력의 경우 synthetic image(x)와 pair가 되는 text(t)와 latent noise(z)를 함께 넣어주게 되고, 출력의 경우 t와 pair가 되는 x를 도출한다.
Synthetic images from Stable diffusion
Stable Diffusion은 Autoencoder의 Latent Sapce에서 Latent Noise로부터 이미지를 생성하는 Denoising Process(Forward)와 이미지로부터 Latent Noise로 가는 Diffusion Process(Forward)를 통해 다양하고 정교한 이미지를 생성하는 데에 성공했다.

여기에서 Text와 Image 간의 Alignment를 맞춰주는 multi-modal 방법들을 Stable Diffusion에도 접목시켰을 때, 생성되는 이미지의 퀄리티가 더욱 상승했다고 한다.
따라서 본 논문에서는 CC3M과 CC12M과 같은 Vision Langugae Pretraining Dataset에서 Text 부분을 사용했다고 한다.
이미지에 대한 Caption에 해당하는 Text 한 개당 하나의 이미지를 생성할 수 있으므로,
Text 데이터셋의 크기만큼 (=기존 데이터셋의 크기만큼) 새로운 이미지를 생성해낼 수 있다.
Self-supervised Learning on Synthetic Images
최근 연구되고 있는 SSL 알고리즘들은 크게 두 가지로 나눌 수 있다.
1. Contrastive Learning: 한 이미지에 대해서 서로 다른 augmentation을 적용한 것은 positive pair가 되어 embedding space 상에서 서로 가까워지도록 하고, 다른 이미지들과는 negative pair가 되어 embedding space 상에서 서로 멀어질 수 있도록 하는 것
2. Masked Image Modeling: 랜덤한 이미지 패치에 mask를 적용한 뒤, masked patch를 reconstruct하는 pretask를 통해 더 좋은 representation을 학습할 수 있도록 하는 것
자세한 설명은 이전 포스팅에서 확인할 수 있다.
[Self-Supervised Learning 개론 - 3] Do we need labels?; Contrastive Learning부터 Deep Generative Model까지
[Self-Supervised Learning 개론 - 3] Do we need labels?; Contrastive Learning부터 Deep Generative Model까지
[Self-supervised Learning 개론 관련 이전 글] [Self-Supervised Learning 개론 - 1] [Self-Supervised Learning 개론 - 1] Do we need labels?; Contrastive Learning부터 Deep Generative Model까지 ⚽ GOAL 2020 ~ 2023 사이에 활발하게 이루어
2na-97.tistory.com
3. Multi-Positive Contrastive Learning with Synthetic Images
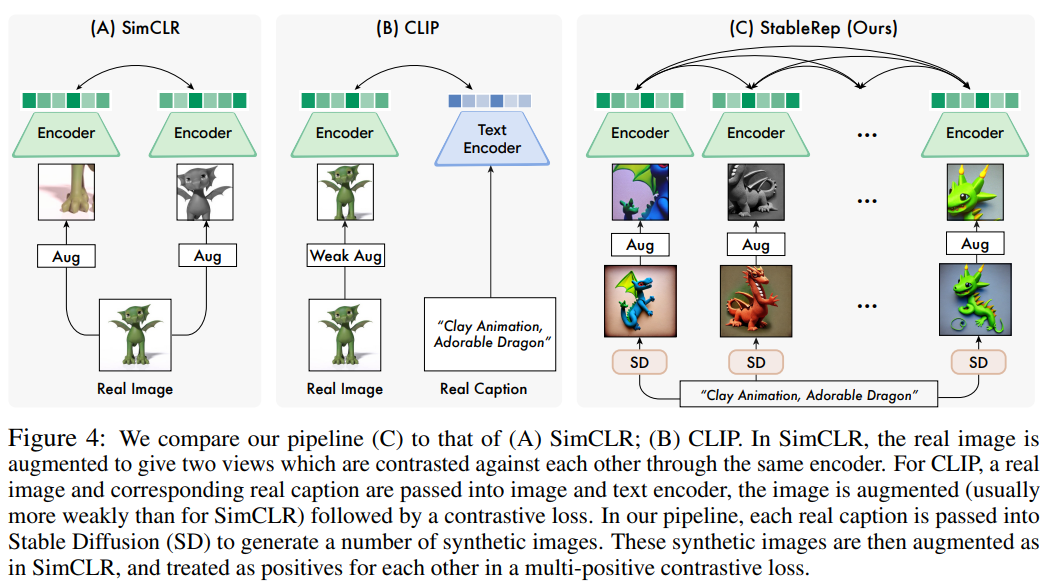
Text-to-image Generative Model의 장점은 Contrastive Learning을 할 때에 여러 개의 Positive Sample을 구성할 수 있다는 점이다.
Stable Diffusion을 통해 Synthetic Image를 생성하기 때문에 같은 Image Caption이더라도 다른 Latent Noise(z)를 사용하면 서로 다른 여러 개의 이미지들을 얻을 수 있게된다.
이 이미지들은 같은 Image Caption(=prompt)으로 생성되었기 때문에 유사한 visual sematic 정보를 담고 있을 것이고,
그렇기 때문에 이 이미지들은 서로 `positive pair`가 될 수 있는 것이다.
Multi-positive Contrastive Loss
- anchor sample: a, (l2 normalized)
- encoded candidates: {b1,b2,...,bK}, (l2 normalized)
- contrastive categorical distribution: q
- scalar temperature: τ (hyper-parameter)
Categorical Distribution q는 anchor sample인 a가 b와 매칭될 확률을 나타내며,
직관적으로는 encoded candidate들에 대한 K-way Softmax Classification Distribution이라고 볼 수 있다.
식은 아래와 같다.
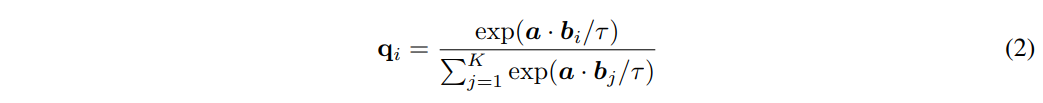
anchor a와 매칭되는 candidate가 적어도 하나 이상이라고 가정하면,
Ground-truth Categorical Distribution을 뜻하는 p는 아래와 같이 나타낼 수 있다.
여기서 ${1}_{match}$ 는 Indicator Function으로, ancor와 candidate가 매치됨을 의미한다.
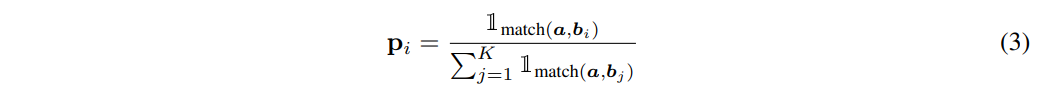
최종적으로, Multi-positive Contrastive Loss는 GT distribution에 해당하는 p와 Contrastive distribution에 해당하는 q간의 Cross-entropy가 된다.
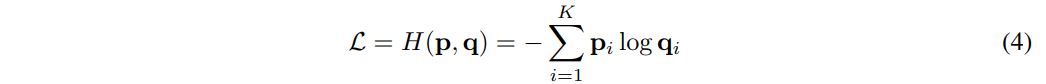
Multi-positive Contrastive Loss는 p가 one-hot vector가 되도록 감소시킨다는 점에서
흔히 사용되는 Single-positive Contrastive loss의 Generalized Form이라할 수 있다.
이러한 부분이 Supervised Contrastive Loss와 비슷하다고 할 수 있다.
하지만 Multi-positive Contrastive Loss에서는 Label을 활용하지 않고,
같은 캡션에서 생성된 이미지인가 아닌가만 고려한다는 점에서 Supervised Contrastive Loss와 다르다고 할 수 있다.

- n: captions
- m: images
- n∗m: # of images for each batch
생성 이미지를 사용하지만, 생성 이미지에도 Data Augmentation을 적용해 주었다고 한다.
(생성 모델의 속도가 매우 빨라지면 Data Augmentation을 적용시키는 대신 Data Loader부터 생성을 해서 사용하는 방식을 채택하면 더 좋을 것 같다는 말도 있음)
그리고 Random Crop을 사용한 SimCLR와는 다르게 Single Crop만을 적용했다고 한다.
4. Experiments
Dataset
아래 데이터에 있는 text를 활용하여 생성한 이미지로 Pretraining을 진행했다고 한다.
- CC3M: 270만개 (2.7 million samples)
- CC12M: 1000만개 (10 million samples)
- RedCaps: 1160만개 (11.6 million samples)
Pretraning을 한 후 아래 두 가지 방법을 통해 Evaluation을 진행했다고 한다.
- Linear Probing: Encoder를 freeze한 채로 ImageNet-1k 및 다른 smaller scale의 classiciation 데이터셋에 대해서 학습 후 평가하는 것
- Few-shot Image Recognition: 학습된 Representation의 Generalization 성능을 평가하기 위함.
실험시 사용한 학습 환경은 아래와 같다.
- Backbone: ViT 모델 (ViT-B/16)
- Batch Size: 8192 (i.e. m∗n = 8192)
- Optimizer: AdamW
- Pre-generate 10 images for each text prompt. (학습 시에는 10개 중 랜덤으로 6개를 선택하여 positive로 사용)
- 즉, SimCLR는 m = 2인데 반해 StableRep의 경우 m = 6으로 더 많은 positive sample들을 활용하는 셈임
- 이는 "SimCLR의 3 epoch"과 "StableRep의 1 epoch"은 서로 같은 연산량을 필요로 함을 의미.
- 따라서 실험에서 표기한 epoch은 SimCLR 기준이고, StableRep의 결과를 보이기 위해서는 SimCLR-equivalent epoch에 대한 결과를 보였다고 함.
Main Results on CC12M and RedCaps
StableRep 모델 실험을 위해서 CC12M과 RedCaps 데이터셋에서 중복된 캡션을 제거하여 사용했다고 한다.
그 결과 CC12M은 10.0M → 8.3M개로, RedCaps는 11.7M → 10.5M개로 줄었다고 한다.
대신 SimCLR나 CLIP에 대해서 실험할 때는 중복된 샘플을 제거하지 않고 모두 사용했다고 한다.
CLIP은 30 epoch부터 over-fitting이 되기 시작했지만, StableRep은 더 오래 학습하더라도 over-fitting이 되지 않았다고 한다.
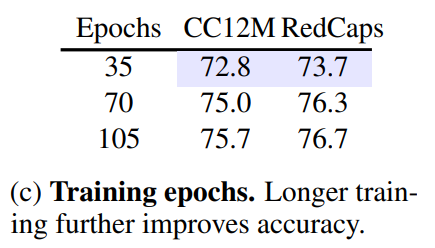
Table1은 ImageNet-1k에 Linear Probing한 결과를 보이고 있다.
아래 표를 보면, Real Data로 학습한 SimCLR보다 Synthetic Data로 학습한 SimCLR가
CC12M과 RedCaps에 대해서 각각 2.2%, 1.0%정도 더 높은 성능을 보였다.
하지만 CLIP의 경우 Synthetic Data로 학습했을 때 CC12M과 RedCaps에 대해서 각각 2.6%, 2.7%정도 성능이 하락했다.
반면에 StableRep의 경우 모든 경우의 다른 모델들보다 더 좋은 성능을 보이고 있다.

Table2는 다른 다양한 데이터셋들에 Linear Probing한 결과를 보이고 있다.
다른 데이터셋들에 대해서도 가장 좋은 성능을 보임을 알 수 있다.
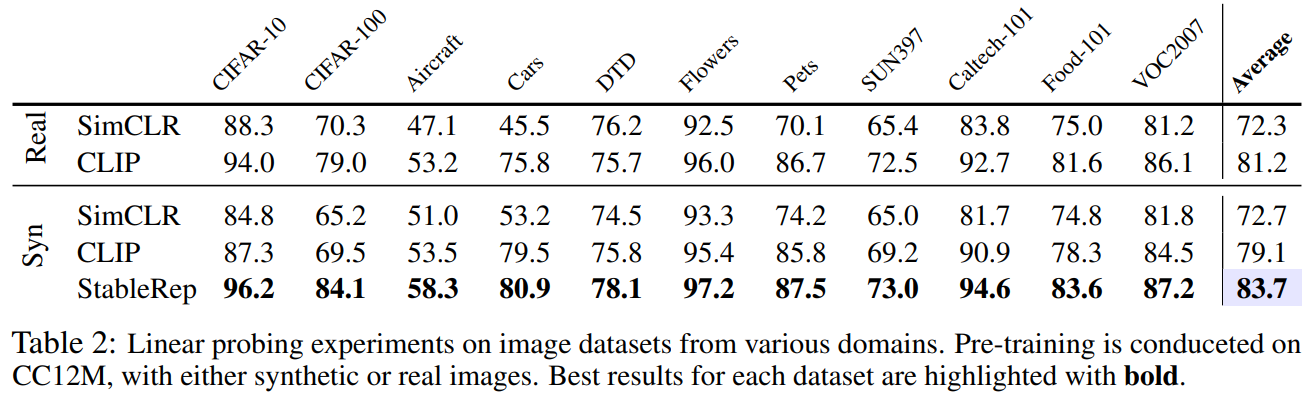
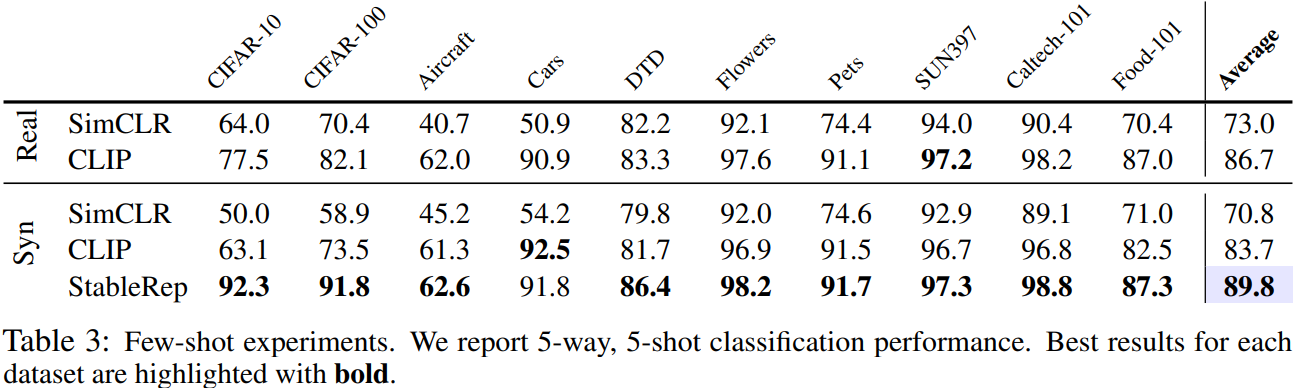
Table3은 다른 데이터셋들에 대해서 Few-shot Image Classification을 한 결과이다.
5-way, 5-shot classification을 수행했을 때, 10개의 데이터셋 중 9개의 데이터셋에서 가장 좋은 성능을 보이고 있었다.
이를 통해 StableRep이 Representation Learning을 잘 수행했다고 말할 수 있다.
다른 Downstream task도 잘 수행하는 지 알아보기 위해서 Semantic Segmentation 실험도 진행했다.
Table4에서 StableRep이 real ImageNet으로 학습된 MAE보다 더 좋은 성능을 보이고 있음을 알 수 있다.

Ablation Study
Ablation Study의 간결성을 위해서 이 파트에서만 Random Downsample Augmentation과 Linear Classifier에 BN Layer를 적용하지 않았다고 한다.
여기서 학습 시 사용한 데이터는 CC3M 캡션이고, 중복 제거 후 3M에서 2.7M개가 남았다고 한다.
아래는 전체 데이터셋의 개수(=T)는 2.7M개, batch size는 8192개로 고정한 채로
한 캡션에 대해서 몇 개의 이미지를 생성해야 하는가 (=l)와
학습 시 한 개의 캡션 당 l 중 몇 개의 이미지를 사용해야 하는가 (=m)에 대한 실험을 진행했다.
즉 같은 캡션 당 여러 이미지를 생성하여 사용하는 것이 좋은지,
혹은 한 캡션 당 조금의 이미지를 생성하더라도 많은 캡션을 사용하여 이미지를 생성하는 것이 좋은지에 대한 실험이다.
(같은 캡션에 대해 최대한 많은 이미지 생성 vs. 최대한 많은 캡션을 사용하여 생성)
아래 표의 (a)를 보면 캡션마다 하나의 이미지만 생성하는 것 보다는
한 개의 캡션 당 두 개 이상의 이미지 (=l≥2)일 때 더 좋은 성능을 보였다고 한다.
또한 l이 커질 수록 더 좋은 성능을 보이고 있었기 때문에 l=10으로 설정하여 사용했다고 한다.
(l>10일 경우 성능 차이가 크지 않아 l=10으로 사용함)
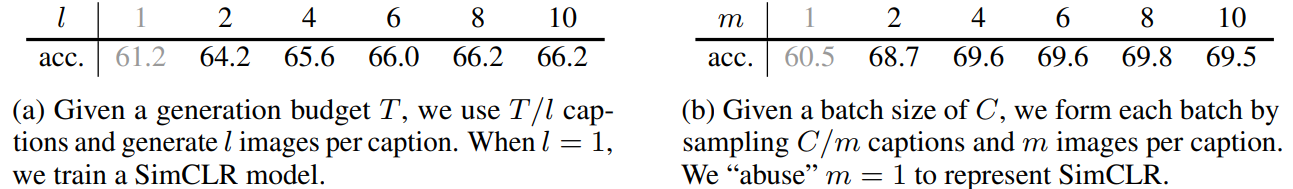
위 표의 (b)를 보면 캡션 당 생성된 이미지 개수인 m에 따른 성능을 보이고 있다.
m이 커질수록 같은 캡션으로 생성된 이미지에 대해서 stronger invariance를 가지고 있음을 뜻하고,
n이 커질수록 negative pair의 수가 더 많아지므로 representation 간의 분리성이 더 커질 수 있음을 말한다.
(m이 커지면 positive pair 비율이 더 커지는 것이므로 representation이 응집되는 경우가 많을 것이고,
n이 커지면 negative pair의 수가 더 많아지므로 representation간에 멀어지는 경우가 더 많아져 분리성이 커진다는 말인듯)
(b)를 보면 m=8일 때 가장 좋은 성능을 보이지만,
m=4일 때와 m=10일 때까지 성능 차이가 크진 않았다고 한다.
이는 StableRep의 Robustness를 보여주는 것이며, 추후 실험에서 m의 default 값은 6으로 설정했다고 한다.

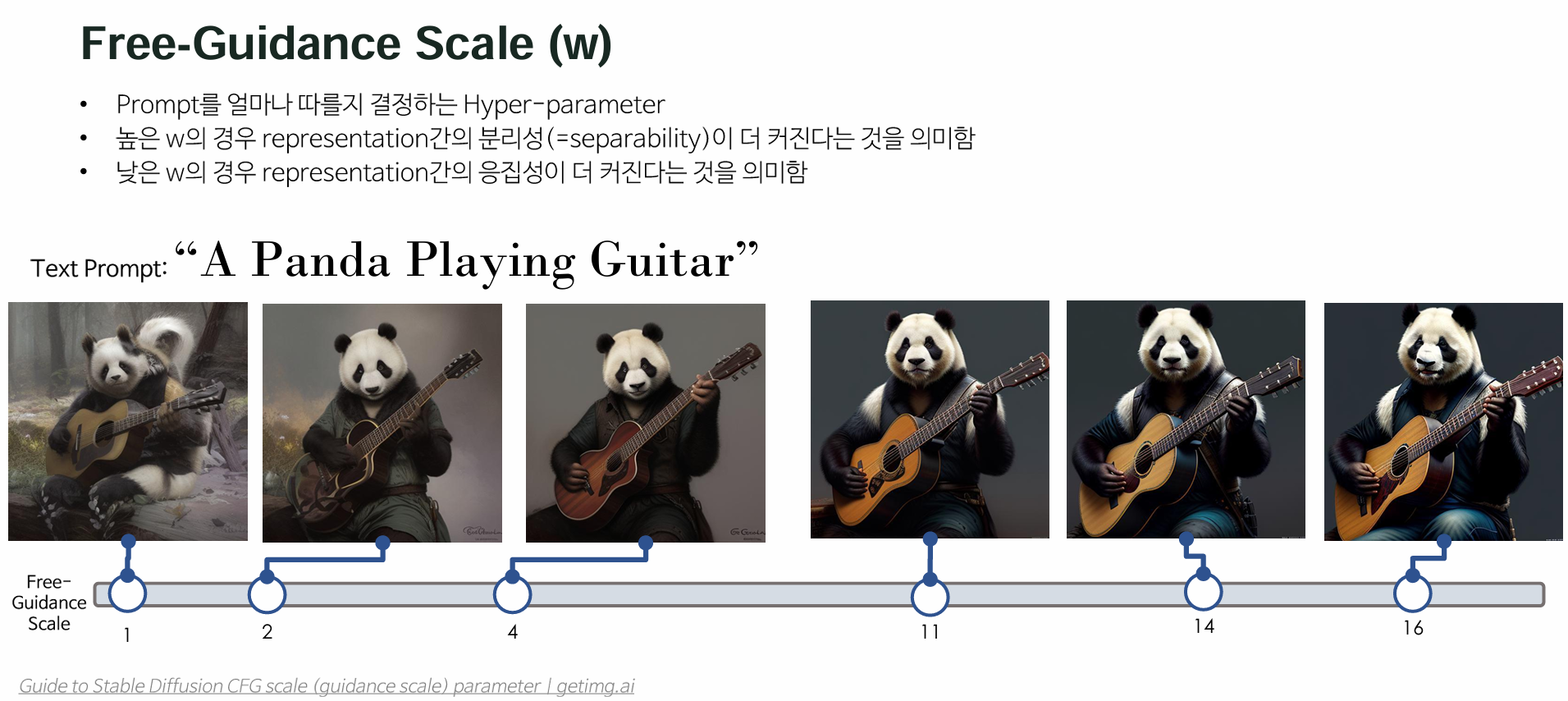
Classifier Free Guidance Scale (=w)는 Prompt를 얼마나 따를지 결정하는 Hyper-parameter다.
따라서 높은 w의 경우 위의 Figure 2의 맨 오른쪽과 같은 상태가 되며 representation간의 분리성(=separability)이 더 커진다는 것을 의미한다.
StableRep은 어떤 w 값에서 가장 좋은 성능을 내는지 확인하기 위해서 세 가지 케이스에 대해서 실험을 진행했다.
- large scale: w∈8,10
- small scale: w∈2,3
- mixed scale: w∈2,3,4,5,6,8,10,12
아래 표를 보면 small scale의 w를 사용했을 때
ImageNet과 Fine-grained Classification Dataset에 대해서 가장 좋은 Linear Transfer Accuracy를 보였다.
이는 작은 w를 사용할 경우 생성된 이미지 간의 큰 intra-caption variation이 발생하여
StableRep이 Stronger Invariance를 배울 수 있도록 유도했다고 한다.
이는 lager scale w를 사용한 SimCLR와는 다른 점이라고 할 수 있으며,
이는 SimCLR 모델은 Intra-image Invariance만을 사용하여 높은 이미지 퀄리티를 가진 것이 더 도움이 되기 때문이라고 분석했다.
(SimCLR는 이미지 내에서의 변화나 변형에 대한 불변성, 즉 intra-image invariance를 사용하여 학습되기 때문에
이미지 사이의 intra-caption variation을 더 크게 만들어 강력한 불변성을 유도하는 것 보다는
변동성이 작으면서도 더 높은 퀄리티의 이미지를 사용하는 것이 더 좋게 작용된다는 뜻인듯)
5. Adding Language Supervision
합성 이미지를 사용한 CLIP은 어떤 원리로 학습이 되는 건지에 대한 답을 찾기 위한 실험을 진행했다.
Guidance Scale w를 {1, 2, 3, 4, 6, 8, 10}으로 변경해가면서 하나의 캡션 당 하나의 이미지를 생성했고,
각 데이터셋으로 CLIP을 학습한 뒤 ImageNet에 대한 zero-shot 성능을 비교해 보았다고 한다.
아래의 Figure5를 보면 높은 w에서 좋은 성능을 냈던 SSL method와는 다르게
CLIP은 낮은 w에서 더 좋은 성능을 보이고 있다.
w = 2일 때 가장 높은 accuracy를 보였는데, 이마저도 real image로 학습했을 때의 결과인 40.2%보다 5.4% 낮은 결과라고 한다.
저자들은 이를 Figure 7에서 볼 수 있듯이 generated image와 caption간의 misalignment 때문일 것이라 분석했다.

아래 그림의 첫 번째 줄을 확인해 보면 "Headhammer Shark"에 대한 캡션으로 생성한 이미지에 종종 그냥 "Shark"가 생성된 경우가 있었다고 한다.
또한 두 번째 줄을 보면 Toilet Roll(화장지) 브랜드인 "Andrex Puppies"를 생성해 달라고 했지만, 그냥 강아지를 생성한 경우도 있었다고 한다.
이런 misalignment는 Fine-grained Class들에 대한 성능 저하에 분명히 영향을 끼쳤을 것이다.

StableRep에 아래와 같은 Loss를 추가하여 Language Supervision을 추가해줄 수 있으며,
Language Supervision을 더한 StableRep을 StableRep+이라고 정의했다.
LLangSup=0.5∗(Li2t+Lt2i)
- Li2t: image-to-text contrastive loss
- Lt2i: text-to-image contrastive loss
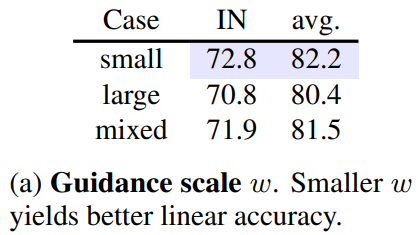
그 결과 CC12M에서는 성능이 72.8%에서 74.4%로 상승했고,
RedCaps에 대해서 학습한 뒤 ImageNet에 대해 Linear Probing을 했을 때는 73.7%에서 75.4%로 상승했다고 한다.
StableRep+의 성능 확인을 위해서 LAION-400M 데이터셋에서 랜덤으로 50M의 subset을 고르고,
여기에 대해서 캡션 당 2개의 이미지를 w = 2로 설정하여 생성했다.
이렇게 생성한 synthetic dataset과 real dataset을 함께 사용하여 CLIP을 학습한 결과를 Figure6에서 확인할 수 있다.
그 결과 real dataset만 활용하는 CLIP보다는 StableRep+가 항상 더 좋은 성능을 보였다.
더 많은 캡션을 사용하여 많은 synthetic dataset을 활용했을 때 더 좋은 성능을 보였음을 알 수 있고,
50M개의 캡션을 사용한 CLIP보다 10M 캡션을 사용한 StableRep+의 성능이 더 좋다는 것을 확인할 수 있다.
즉, StableRep+는 CLIP과 비교했을 때 캡션당 5배의 efficiency를 가지고 있다고 말할 수 있다.

Fairness and compositionality
StableRep의 fairness와 compositional understanding을 알아보기 위해서
"FairFace"와 "ARO"라는 데이터셋에 대한 결과를 비교해 보았다고 한다.
Fairness를 평가하기 위해서 FairFace에 대해 zero-shot classification을 수행했을 때,
인종이나 성별에 관계 없는 균등한 결과가 나왔다고 한다. (e.g., treating Black male, Black female, Indian female, and so on)
CC12M의 real image로 학습한 CLIP의 경우 동남아시아 남성에 대한 정확도가 0.3%밖에 되지 않았지만,
CC12M을 활용한 synthetic image로 학습한 CLIP의 경우 동남아시아 남성에 대한 정확도가 3.1%로 올랐다고 한다.
반면에 StableRep+의 경우 동남아시아 남성에 대한 정확도가 27.2%로 가장 높은 결과였다고 한다.
redcap의 real image로 학습한 CLIP의 경우 동아시아 남성에 대한 정확도가 0.4%인 것에 반해,
synthetic image로 pre-training을 진행한 StableRep+의 경우 동아시아 남성에 대한 정확도가 22.8%로 올랐다고 한다.
그 결과 합성 데이터로 학습할 경우 worst-class에 대한 정확도를 올리는 데에 도움이 될 수 있다는 것을 알 수 있다.
(하지만 여전히 geographic bias는 존재한다.)
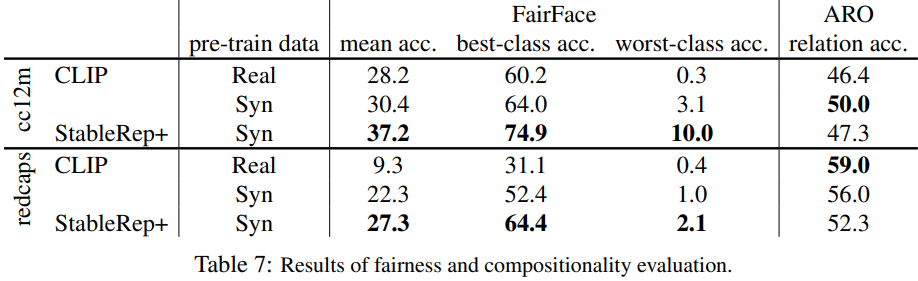
ARO 데이터셋으로 실험한 Compositionality Evaluation 결과는 다소 모호하다고 한다.
ARO란 Attribution, Relation and Order의 약자로, Vision-Language Model에서
composition과 order understanding을 평가하기 위한 벤치마크이다.
CC12M 데이터셋으로 pretraining하는 경우 synthetic dataset을 사용하는 것이 real data만 사용하는 것보다 relation accuracy를 높이는 데에 더 도움이 되었지만,
redcaps 데이터셋에 대해서는 반대의 결과가 나왔다고 한다.
(이 이유에 대해서는 future works로 남겨 둠)
7. Conclusion, Limitations and Broader Impact
Conclusion
- text-to-image 분야의 State-of-the-Art 모델인 Diffusion Model을 사용하여 생성한 Synthetic Image들로 모델을 사전 학습 (Pretraining) 시킨 "StableRep"은 다양한 Down-stream Task에 대해서 좋은 성능을 보임.
- Stable Diffusion을 활용하여 하나의 캡션에 대해 다양한 Synthetic Image들을 생성할 수 있기 때문에 multi-positive를 활용할 수 있었고, multi-positive contrastive loss를 적용하여 더 좋은 representation을 학습할 수 있었음을 보임.
- 이를 통해 같은 양의 Real Dataset으로만 학습시킨 모델보다 Synthetic Dataset으로 학습한 모델이 더 좋은 성능을 보임.
Limitations
- Training on Synthetic Images vs. Real Images: SSL (Self-supervised Learning) 방법들을 합성 이미지에서 실제 이미지와 동일한 양으로 훈련하는 효과에 대한 이유를 아직 완전히 이해하지 못함. 따라서, 이 방법이 일반적인 상황에서 적용 가능한지 여부에 대한 불확실성이 존재함.
- Slow Image Generation Process: 이미지 생성 프로세스가 느림 (GPU에서 이미지당 약 0.8초(A100 GPU) 또는 2.2초(V100 GPU with xFormers)가 걸림). 따라서 매 epoch마다 실시간으로 생성된 이미지로 학습시키는 것이 어려움.
- Semantic Mismatch and Quality of Synthetic Data: 입력 프롬프트와 생성된 이미지 간의 의미적 불일치 문제 존재. (위의 Figure7에서 설명된 내용). 이는 합성 데이터의 품질과 유용성에 영향을 미칠 수 있음.
- Potential for Bias and Mode Collapse: 합성 데이터는 Mode Collapse로 인해 다양한 변형이 부족한 상황에서 특정 유형의 이미지만 생성되는 현상이 생길 수도 있음.
- Challenges with Image Attribution: 합성 데이터를 사용할 때 이미지 속성을 추적하는 것이 어려울 수 있음 (=합성된 데이터의 특성이나 원본 소스를 명확하게 식별하는 것이 어려울 수 있다)
Boarder Impacts
본 논문은 거대한 양의 real image를 모아 다양한 visual representation을 학습해야 한다는 부담을 덜어 줄 수 있는 방법론을 제안한다.
이는 사람이 직접 이미지를 모으고 이미지에 대한 설명 (=caption, labeling,..)을 할 때 발생하는 cost를 최소화할 뿐만 아니라,
데이터 수집 및 Labeling 작업에서 생길 수 있는 human-bais를 줄이는 데 기여할 수 있다.
하지만 "StableRep"은 large-scale, uncurated web data를 활용하여 생성된 이미지이므로 사회에 내재되어 있는 편향이나 오류를 포함하고 있을 수 있다.
또한 그들이 합성 데이터를 생성할 때 사용한 text prompt가 완전히 bias-free라고 보기 어렵다고 한다.
StableRep에서 사용할 text prompt를 고르는 것은
기존의 SSL에서 visual representation learning을 할 때 학습에 사용할 real image들을 선택하는 것이나 마찬가지이므로,
어떤 prompt를 선택했느냐에 따라 결과가 달라질 수 있다고 한다.
#AI최신논문 #AI최신논문리뷰 #딥러닝최신논문리뷰 #컴퓨터비전최신논문



