
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- deep learning
- Computer Vision 논문 리뷰
- cvpr 논문 리뷰
- CVPR
- Computer Vision
- VLM
- iclr 논문 리뷰
- Segment Anything
- Self-supervised learning
- Multi-modal
- Segment Anything 리뷰
- ssl
- Meta AI
- deep learning 논문 리뷰
- Data-centric AI
- Data-centric
- Stable Diffusion
- cvpr 2024
- 자기지도학습
- active learning
- Segment Anything 설명
- Prompt Tuning
- contrastive learning
- ai 최신 논문
- ICLR
- iclr 2024
- iclr spotlight
- 논문 리뷰
- 논문리뷰
- Prompt란
- Today
- Total
Study With Inha
[Paper Review] (BLIP, BLIP-2) Bootstrapping Language-Image Pre-training 설명 및 논문 리뷰 본문
[Paper Review] (BLIP, BLIP-2) Bootstrapping Language-Image Pre-training 설명 및 논문 리뷰
강이나 2023. 6. 15. 02:42BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
논문 링크: https://arxiv.org/abs/2201.12086
BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
Vision-Language Pre-training (VLP) has advanced the performance for many vision-language tasks. However, most existing pre-trained models only excel in either understanding-based tasks or generation-based tasks. Furthermore, performance improvement has bee
arxiv.org
BLIP: Bootstrapping Language-Image Pre-training
Introduction
Image-Text Retrieval이나 Image Captioning 등 Vision(image)과 Language(text)을 함께 활용하는 Multi-modal task가 많아지고 있다.
이런 task를 수행하는 모델을 학습하기 위해서는 {image, text} pair가 있는 대용량 데이터셋이 필요하다.
web 데이터의 경우 대용량의 {image, text} pair 데이터를 얻을 수 있다는 장점이 있지만, 데이터에 noise가 많다는 단점이 있다.
따라서 BLIP은 '질 좋은' large scale web 데이터셋으로 모델을 pretraining 시켜 downstream task를 수행할 수 있는 VLP (Vision-Language Pretraining) Framework를 제시한다.
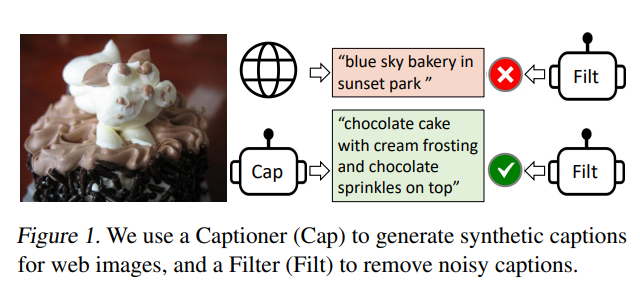
★ Contributions of BLIP ★
1. CapFilt (Captioner + Filter): web data의 noisy한 데이터들을 필터링할 수 있는 구조로, 이를 통해서 web data 및 synthesized data를 필터링한 후 데이터로 사용하는 dataset bootstrapping 과정으로 '질 좋은' large scale {image, text} pair 데이터셋 만듦.
2. MED(Multimodal mixture of Encoder-Decoder): 세 가지 multi-task pretraining을 수행하여 flexible한 transfer learning이 가능할 수 있도록 하는 모델 아키텍쳐 제시하여 성능 올림.
Methods
1. MED (Multimodal mixture of Encoder-Decoder)
BLIP의 architecture는 아래 세 가지 task를 수행하여 pretrain된다.
- Image-Text Contrastive(ITC) Learning
- Image-Text Matching (ITM)
- Image-conditioned Language Model (LM)
따라서 모델의 전체 loss function의 경우 세 가지 task의 loss를 모두 더한 것을 사용하게 된다.
$Total_{Loss} = ITC_{Loss} + ITM_{Loss} + LM_{Loss}$

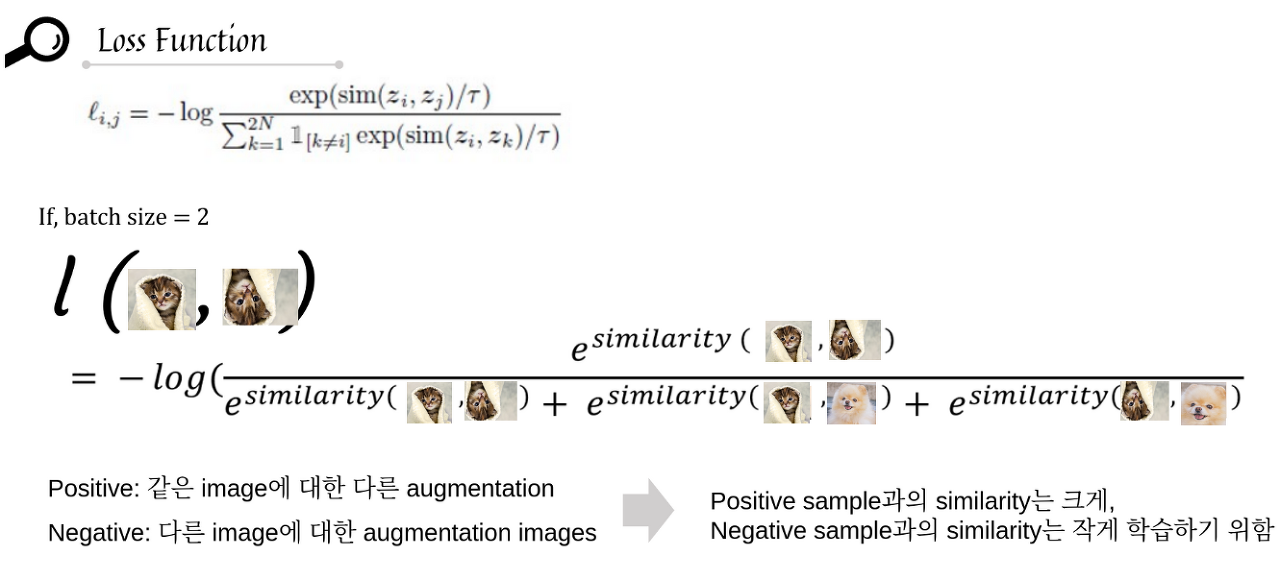
1. ITC (Image-Text Contrastive Loss)
image는 image encoder에 입력한 임베딩 값과 text는 text encoder에 넣은 임베딩 값을 서로 비교하게 된다.
이 때, 같은 {image, text} pair에 있는 positive pair의 경우에는 cosine similarity가 높아지고 다른 {image, text} pair에 있는 negative pair의 경우에는 cosine similarity가 낮아지도록 학습되는 Contrastive Learning의 개념을 활용하여 unimodal encoder를 학습시켰다.
하지만 데이터가 Noisy한 특성을 가지고 있다는 뜻은, negative pair로 분류된 것 중에서도 positive pair가 있거나 그 반대 경우도 있을 수 있다는 뜻이다.
따라서 이러한 문제로 인한 성능 저하를 최소화 하기 위해 momentum encoder를 사용하여 soft label을 만든 후 학습에 활용했다고 한다.
ITM과 LM에서는 Image를 입력받아 Text를 생성해내는 Image-grounded Text Encoder-Decoder Model이 필요하다.
2. ITM (Image-Text Matching)
ITM은 그 모델의 인코더(=image-grounded text encoder)에 text를 넣어서 얻은 임베딩을 image encoder의 임베딩과 cross attention을 시킨 후,
해당 text와 image가 잘 matching이 됐는지 예측하도록 학습시키는 loss를 의미한다.
학습을 위한 negative sample을 선택할 때 image나 text와 semantic 정보가 비슷한 hard sample들을 활용하여 negative pair로 구성했다고 한다.
3. LM (Language Modeling Loss)
LM은 image-grounded text decoder에서 생성된 text를 학습에 활용하게 된다.
ITM과 마찬가지로 Image Encoder에서 얻은 representation을 cross attention을 통해 받아오게 되는데,
Language Modeling Loss는 이미지에 맞는 caption이 생성될 수 있도록 decoder를 학습시키는데 활용된다.
2. CapFilt (Captioner & Filter)
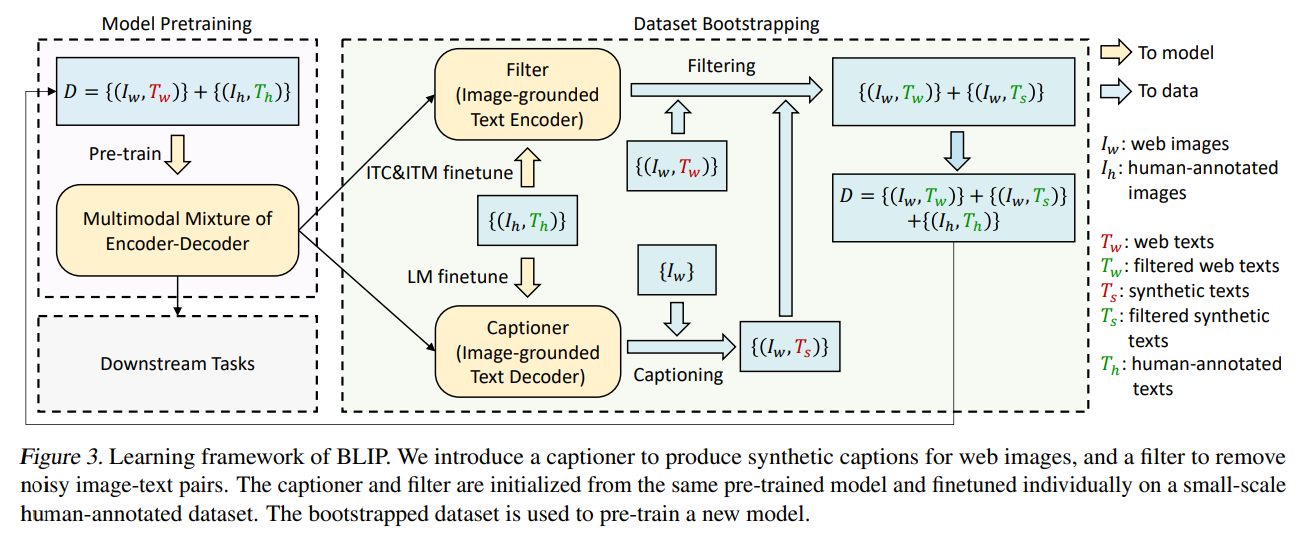
- Captioner (Image-grounded Text Encoder): 인간이 레이블링한 {image, text} 데이터셋으로 LM loss를 통해 학습된 Captioner는 web에서 수집한 image에 대한 텍스트, 즉 캡션을 생성한다.
- Filter (Image-grounded Text Decoder): 인간이 레이블링한 {image, text} pair 데이터셋으로 ITC와 ITM loss를 통해 학습된 Filter는 web에서 수집한 {image, text} pair들과 Captioner가 생성한 {image, text} pair들을 걸러주는 데에 사용된다. 이 때, {image, text} pair가 서로 맞지 않게 짝지어진 경우를 제거하는 방식으로 noise를 가질 수 있는 데이터들을 정제하는 역할을 한다.

BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
논문 링크: https://arxiv.org/abs/2301.12597
BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
The cost of vision-and-language pre-training has become increasingly prohibitive due to end-to-end training of large-scale models. This paper proposes BLIP-2, a generic and efficient pre-training strategy that bootstraps vision-language pre-training from o
arxiv.org
BLIP-2: BLIP with Frozen Image Encoders and Large Language Models
Introduction
- Vision, Language 각각으로 보면 각자의 modality에서 좋은 성능을 내는 모델들은 많음
- 잘 학습된 Vision Encoder와 Large Langauage Model을 그대로 사용하여 각자의 장점을 활용하되 두 모달리티 간의 간극을 줄여주는 ‘Q-Former’를 도입하여 좋은 VLP를 만듦
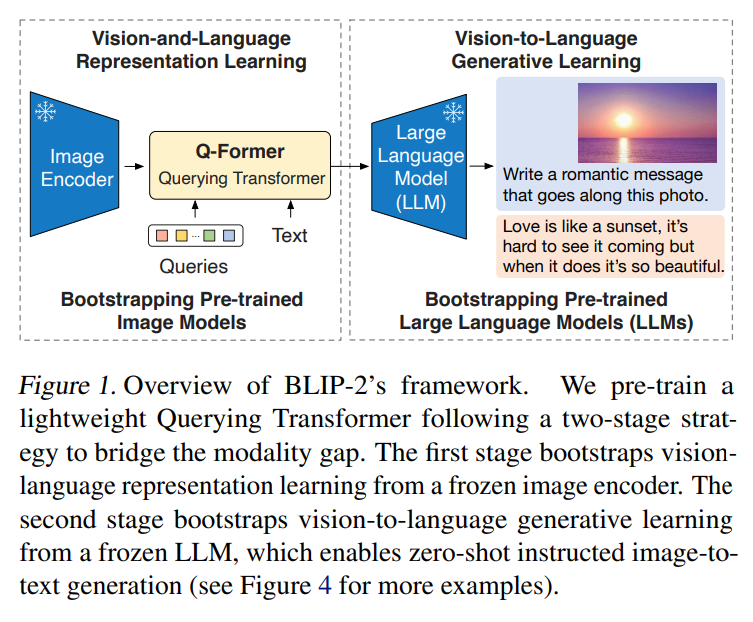
Contributions.
- BLIP-2는 frozen pre-trained image and text network를 효율적으로 사용하면서 Q-former를 통해 modality gap을 줄일 수 있는 방법을 제시
- BLIP-2는 기존 방식들에 비해 간단한 구조를 토대로 다양한 VL task에서 SOTA를 기록
- OPT, FlanT5와 같은 성능 좋은 LLMs을 기반으로 BLIP-2는 zero-shot image to text generation을 진행
- Frozen unimodal models를 사용하고 lightweight Q-former를 학습함으로써 BLIP-2는 compute-efficient하게 성능을 높임
Method
Stage1. (Q-Former 학습) Bootstrap vision-language representation learning from a frozen image encoder
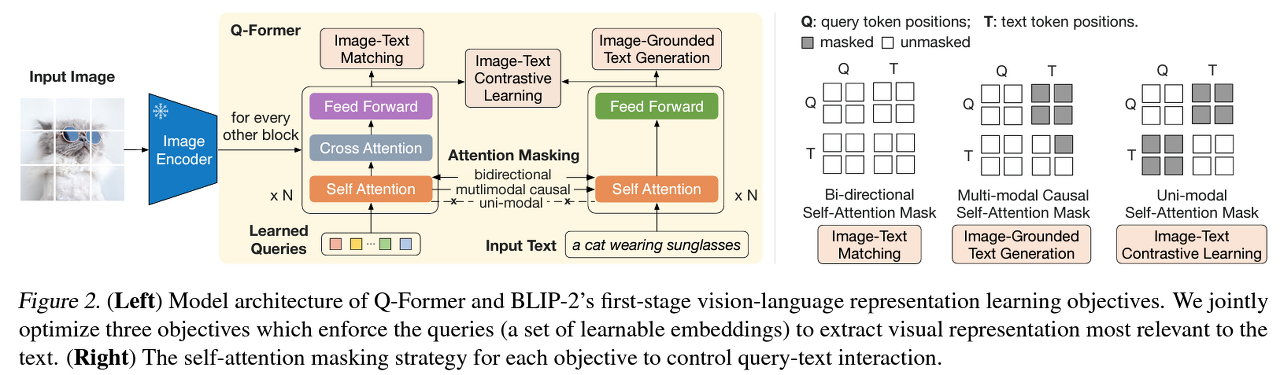
1. ITC(Image-Text Contrastive Learning)
- Image representation, text representation을 align하기 위한 loss 함수.
- image transformer에서 나온 query output과 text transformer에서 나온 output간의 pairwise 유사도를 계산하고, 가장 값이 높은 pair를 query-text pair로 선정
2. ITG(Image-grounded Text Generation)
- 주어진 image에 맞는 text를 생성하도록 하는 loss
3. ITM(Image-Text Matching)
- image와 text pair가 매칭될 수 있도록 align 시키는 loss
Stage2. Q-Former를 LLM에 연결하는 과정
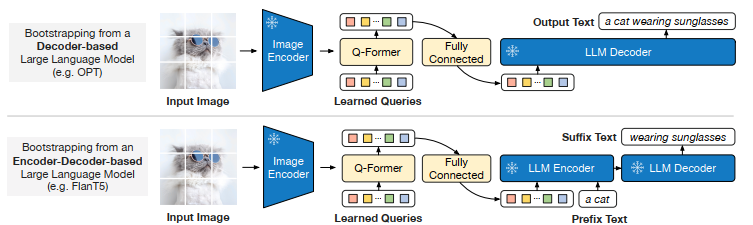
- Q-Former의 output query는 Text와의 차원을 맞추기 위해서 Fully Connected Layer를 통과한 후 LLM로 전달
Experiments
- Pretraining dataset: BLIP에서 사용한 데이터를 그대로 사용(CapFilt 사용)
- Pretrained Encoder: ViT 계열(ViT-L/14, ViT-G/14)
- LLM: OPT, FlanT5 계열
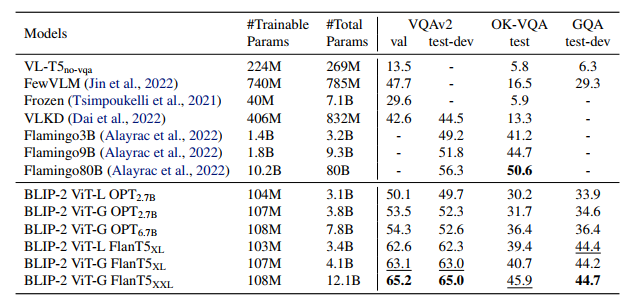
BLIPv2's overall performances on zero-shot VL tasks

기존 모델들보다 파라미터 수는 훨씬 작지만, 더 뛰어난 zero-shot 성능을 보임
Comparison with SOTA on zero-shot VQA
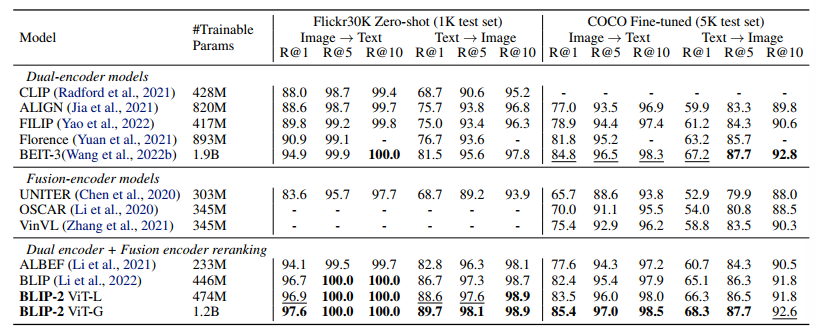
Comparison with SOTA on image-text retrieval
Loss Ablation Study




