| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Computer Vision 논문 리뷰
- Data-centric AI
- Segment Anything
- 논문리뷰
- ai 최신 논문
- deep learning 논문 리뷰
- Data-centric
- deep learning
- Meta AI
- CVPR
- cvpr 2024
- contrastive learning
- 논문 리뷰
- VLM
- Segment Anything 설명
- ssl
- Stable Diffusion
- 자기지도학습
- iclr 2024
- cvpr 논문 리뷰
- Computer Vision
- Multi-modal
- Self-supervised learning
- ICLR
- iclr 논문 리뷰
- active learning
- Prompt Tuning
- iclr spotlight
- Prompt란
- Segment Anything 리뷰
- Today
- Total
Study With Inha
[Paper Review] CVPR 2020, Hyperbolic Image Embeddings 논문 리뷰 및 설명 본문
[Paper Review] CVPR 2020, Hyperbolic Image Embeddings 논문 리뷰 및 설명
강이나 2023. 5. 24. 15:57CVPR 2020, Hyperbolic Image Embeddings
논문 링크: https://arxiv.org/abs/1904.02239(https://arxiv.org/abs/1904.02239)
Hyperbolic Image Embeddings
Computer vision tasks such as image classification, image retrieval and few-shot learning are currently dominated by Euclidean and spherical embeddings, so that the final decisions about class belongings or the degree of similarity are made using linear hy
arxiv.org
Introduction
Self-supervised Learning 방법론들이 좋은 성능을 내고 있는데, 그 중 많은 방법들이 이미지 간의 유사도를 비교하면서 학습하는 'Contrastive Learning'을 채택하고 있다.
간단하게 말하면 같은 클래스 내 이미지들 (=positive pair)의 representation은 embedding space에서 더 가까워질 수 있도록,
다른 클래스 내 이미지들 (=negative pair)의 representation은 embedding space에서 더 멀어지도록 학습시키는 것을 말한다.
자세한 설명은 아래의 Self-supervised Learning 개론 글에서 확인하면 좋을 것 같다.
[Self-Supervised Learning 개론 - 1] Do we need labels?; Contrastive Learning부터 Deep Generative Model까지
[Self-Supervised Learning 개론 - 1] Do we need labels?; Contrastive Learning부터 Deep Generative Model까지
⚽ GOAL 2020 ~ 2023 사이에 활발하게 이루어진 연구들의 개념을 알아본다 각 개념의 대표적인 논문들을 간단하게 소개하여 연구의 흐름을 알아본다 이를 통해서 본인 연구/개발에서 써 볼만한 insigh
2na-97.tistory.com
[Self-Supervised Learning 개론 - 3] Do we need labels?; Contrastive Learning부터 Deep Generative Model까지
[Self-Supervised Learning 개론 - 3] Do we need labels?; Contrastive Learning부터 Deep Generative Model까지
[Self-supervised Learning 개론 관련 이전 글] [Self-Supervised Learning 개론 - 1] [Self-Supervised Learning 개론 - 1] Do we need labels?; Contrastive Learning부터 Deep Generative Model까지 ⚽ GOAL 2020 ~ 2023 사이에 활발하게 이루어
2na-97.tistory.com
이 때, 이미지 representation 간의 '유사도'를 측정하기 위해서 'cosine similarity'를 사용하는 경우가 많다.
하지만 본 논문에서는 cosine similarity loss보다 더 좋은 성능을 가진 'Hyperbolic Loss'를 제안하며, 다양한 실험을 통해 유효성을 입증한다.
최근에는 NLP 분야에서도 활용되고 있는 metric 중 하나라고 하며, self-supervised learning을 할 때에 활용할 수 있는 general한 방법이지 않나 싶다.
'Hyperbolic loss'는 평면 상의 벡터라고 가정하고 계산하는 cosine similarity loss와는 달리, 벡터 간의 유사도를 구체 상에서 계산하겠다는 것이다.
이미지 간의 관계는 복잡한 특성을 지니고 있기 때문에 평면 상의 유사도를 측정하는 것보다 구체 상에서 계산을 했을 때,
관계의 특성을 잘 보존할 수 있어 좋은 성능을 낸다고 한다.

Motivation for Hyperbolic Image Embeddings = Hierarchical Relations
- Classification tasks in-the-wild, we want to learn image embeddings that obey the hierarchical constraints.
- 하나의 이미지에 여러 개의 클래스가 포함되어 있는 데이터셋의 경우, 이러한 이미지들의 임베딩은 hierarchy를 가지고 있다는 뜻.
- 따라서 hierarchy함을 잘 반영할 수 있는 metric이 필요
- In some tasks, more generic images may correspond to images that contain less information and are therefore more ambiguous.
- face recognition task에서 이미지의 resolution이 굉장히 낮을 경우 이 이미지는 많은 정보를 가지고 있지 않아서 ambiguous한 경우가 있음
- 이미지별로 image quality 혹은 ambiguity가 다를 경우 이 데이터셋 또한 hierarchical structure를 가지고 있다고 생각할 수 있음
- Many of the natural hierarchies investigated in natural language processing transcend to the visual domain.
- 이미지를 서로 다른 동물 종들을 구분하는 것은 hierarchical grouping으로 볼 수 있음

Experiments
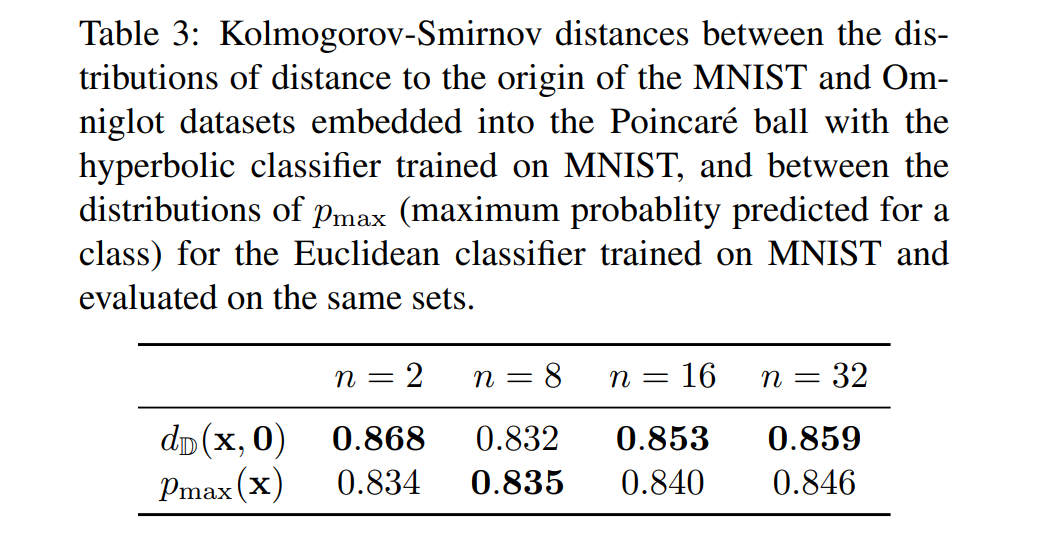
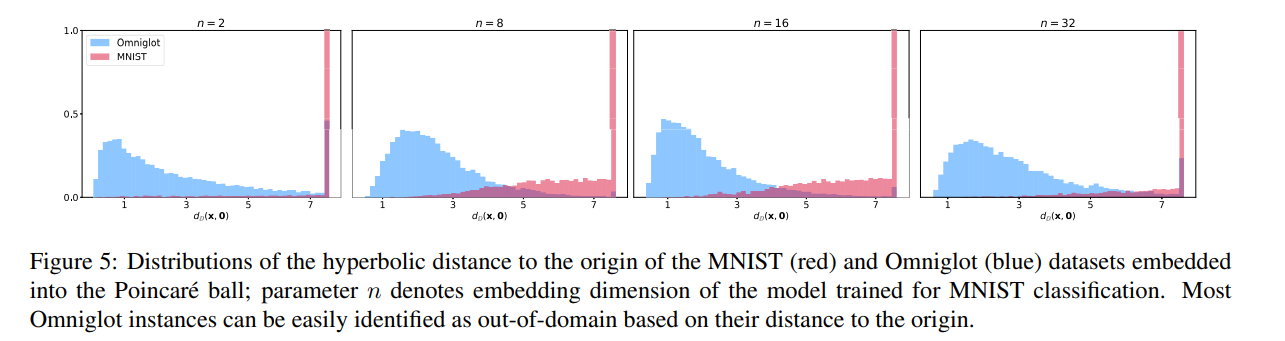
1. Distance to the Origin as the Measure of uncertainty
- 실험 의도
- Hyperbolic Classifier로 학습하게 되면 hierarchical structure를 학습할 수 있으므로, ambiguous한 이미지의 경우 center에 가깝도록 학습되고 확실한 이미지의 경우 boundary에 가깝게 학습될 것이다.
- 만약 위의 가설이 맞는 경우 Poincare ball distance가 모델의 confidence를 보여줄 수 있는 좋은 metric이 될 것이다.
- 따라서 위의 가설이 맞는지 확인하기 위한 실험 step.
- 실험 방법
- MNIST 데이터셋으로 학습시킨 후, test accuracy 99% 나오는 모델 준비
- 위 모델을 Omniglot data (MNIST같은 숫자 데이터) 로 evaluation하기 위해 MNIST와 같은 배경을 가지도록 Normalize하여 평가 진행.
- 모델에서 얻은 embedding들을 origin으로부터의 hyperbolic distance를 계산함
- 실험 결과
- hyperbolic classifier로 학습시킨 경우 ($d_{D}(x, 0)$)와 Euclidean classifier로 학습시킨 경우 ($p_{max}$)를 비교해 보았을 때 4개의 case 중 3개의 case에서 hyperbolic classifier가 더 좋은 결과를 보임
- MNIST로 학습시킨 모델을 MNIST, Omniglot 데이터셋에 대해 각각 test를 진행했을 때 쉬운 이미지들은 boundary에 있는 경향이, 분류하기 어려운 이미지 (대부분 Omniglot 데이터셋에 포함된 이미지들)는 중심에 위치하고 있는 경향이 있음을 확인할 수 있다

2. Few-shot Classification
- 실험 의도
- Hyperbolic embedding의 경우 아주 복잡한 hierarchical relation이더라도 이를 잘 반영하고 있기 때문에 few-shot classification에서 좋은 성능을 보일 수 있음을 보여주기 위함
- 실험 방법
- (baseline) ProtoNets: 클래스마다 이미지들의 embedding 평균을 prototype representation으로 지정하여 사용하는 방법
- Hyperbolic ProtoNets: Embedding 평균을 계산할 때 Euclidean mean을 사용하는 것이 아닌 HypAve 사용
- 데이터셋: MiniImageNet, CUB
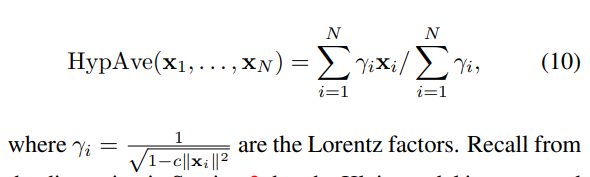
- 실험 결과
- Baseline Model
- 4 Conv (4개의 Conv 블록으로 이루어진 일반적인 CNN 모델)
- ResNet18
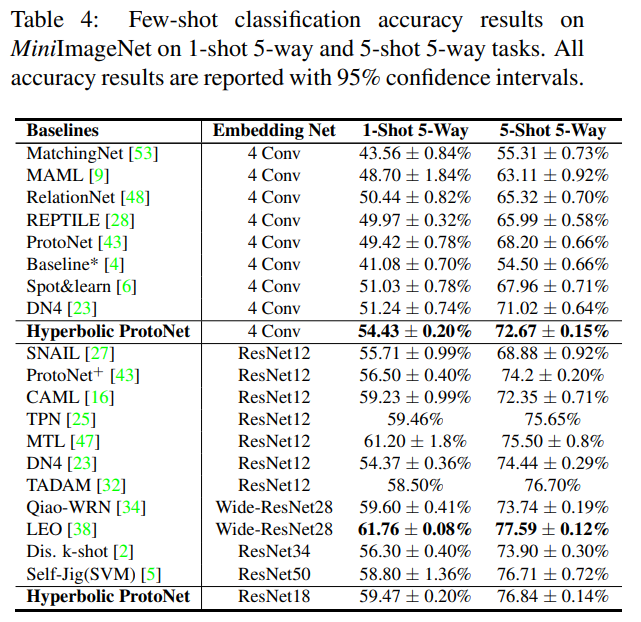
- Mini-ImageNet
- 그냥 ProtoNet보다 Hyperbolic ProtoNet이 더 좋은 결과를 보임
- 특히나 5-shot setting보다 1-shot setting에서 더 큰 성능 향상이 있었음
- CUB dataset
- Eculidean 방법들보다 좋은 성능을 보임
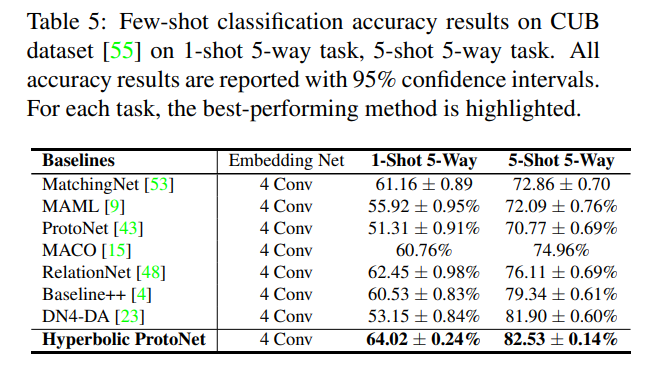
- Eculidean 방법들보다 좋은 성능을 보임
- Baseline Model
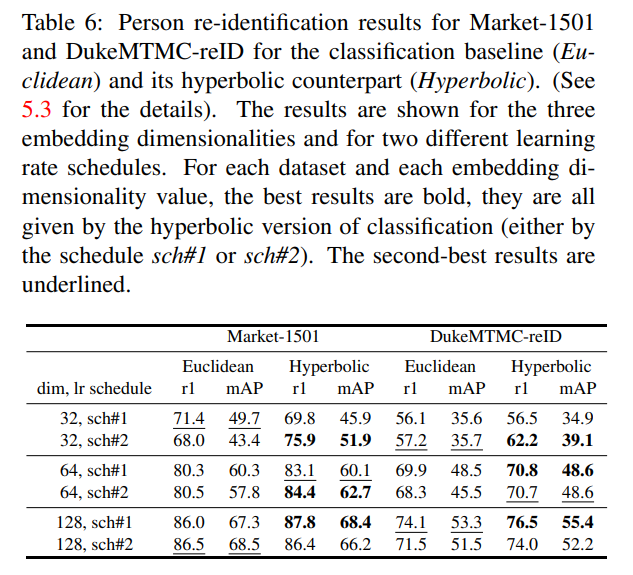
3. Person re-identification
- 실험 방법
- 데이터셋: DukeMTMC-reID, Market1501
- 성능평가 방법
- Rank 1 of the Cumulative Matching Characteristic Curve: 주어진 이미지를 Rank 몇 번만에 맞출 수 있는지
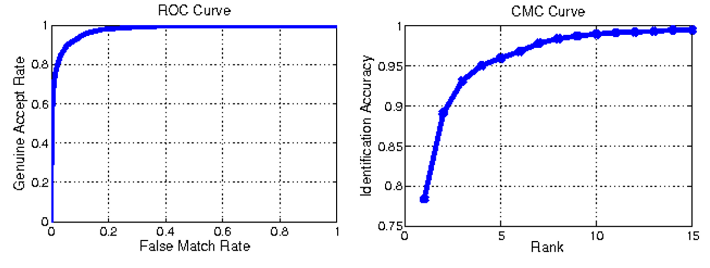
- Mean Average Precision
- Rank 1 of the Cumulative Matching Characteristic Curve: 주어진 이미지를 Rank 몇 번만에 맞출 수 있는지
- sch#1, sch#2의 두 개의 다른 learning rate scheduler 사용하여 평가
- Backbone: ResNet50
- 300 epoch training 후의 결과
- 실험 결과
- Euclidean baseline보다 Hyperbolic 방법들이 더 좋은 성능을 보임
- 더 낮은 차원의 embedding에 대해서 실험했을 때 Hyperbolic 방법론들의 성능 향상 폭이 더 컸음