
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Self-supervised learning
- Computer Vision
- cvpr 2024
- 논문리뷰
- Computer Vision 논문 리뷰
- Data-centric
- deep learning 논문 리뷰
- Stable Diffusion
- contrastive learning
- Segment Anything 설명
- ICLR
- Prompt Tuning
- Segment Anything
- Prompt란
- iclr 2024
- CVPR
- ai 최신 논문
- Data-centric AI
- Multi-modal
- deep learning
- iclr 논문 리뷰
- VLM
- 논문 리뷰
- Meta AI
- iclr spotlight
- ssl
- Segment Anything 리뷰
- active learning
- 자기지도학습
- cvpr 논문 리뷰
- Today
- Total
Study With Inha
[Paper Review] Meta AI (FAIR)의 새로운 논문, ImageBind: One Embedding Space To Bind Them All 논문 리뷰 본문
[Paper Review] Meta AI (FAIR)의 새로운 논문, ImageBind: One Embedding Space To Bind Them All 논문 리뷰
강이나 2023. 5. 11. 18:36Meta AI (현 메타 에이아이, 구 페이스북), Facebook Research team (FAIR)
IMAGEBIND: One Embedding Space To Bind Them All
논문 링크: https://arxiv.org/pdf/2305.05665.pdf

1. Introduction
최근 Segment Anything Model (SAM) 이라는 것을 발표한 Meta AI에서 또 다른 논문을 발표했다.
2023년 5월 9일 아카이브에 올라온 최신 논문인데, 신선한 아이디어를 제시하고 있어 리뷰할 논문으로 선정했다.
이 논문에서 제시하는 'ImageBind'는 여러가지 모달리티들의 embedding을 하나의 공통 space에 정렬함으로써
긴밀한 관계를 형성하고, 이를 통해 다양한 multi-modal task들을 수행할 수 있도록 한 모델이다.
이를 통해 image, text, audio, depth, heat map, 그리고 IMU 간의 변환이 가능하도록 했다.
text를 입력하면 원하는 이미지가 나오거나, 이미지를 입력하면 해당하는 소리가 나오기도 한다.
중요한 것은 어떤 방향이든지 위 6개의 모달리티들 간 변화가 가능하도록 했다는 것이다.
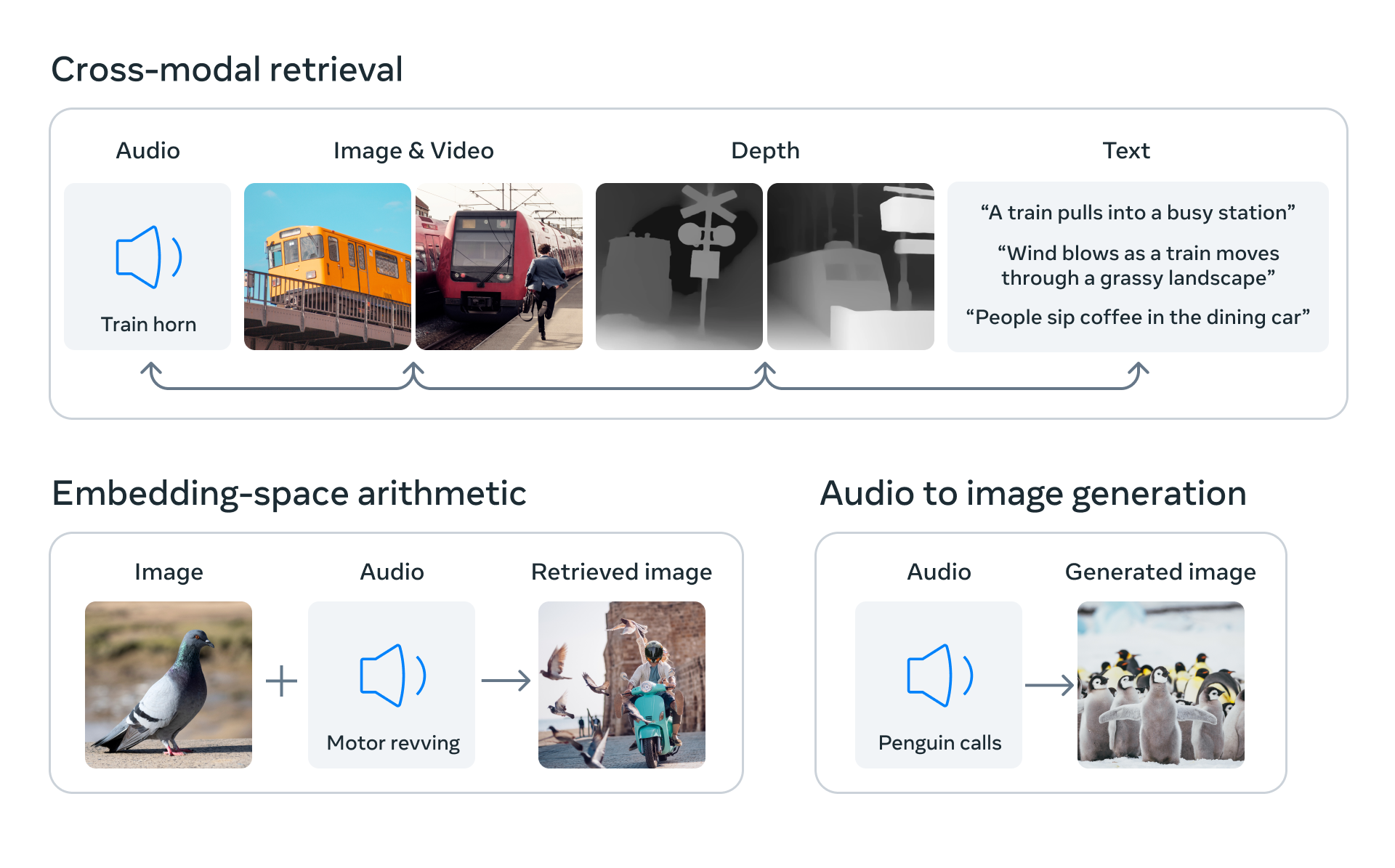
놀라운 점은 다른 모달리티의 embedding들을 image embedding의 align과 통일시키는 방법으로
아주 간단하고 실용적으로 cross-modality model을 구현했다는 점이다.
이 말은 (text, image), (audio, image), (depth, image), (heat map, image), 그리고 (IMU, image) 의 pair로 이루어져있는 데이터셋으로만 학습을 하더라도
audio를 입력하여 원하는 text를 얻을 수 있다는 것이다.
(audio-text로 이루어진 데이터셋으로 학습한 적이 없는데도 불구하고)
이처럼 모든 모달리티간의 학습을 하지 않아도 완전한 cross-modality가 가능한 모델을 만들어 냈다는 것이 논문의 주요한 contribution이다.
2. Method

모든 모달리티는 이미지 혹은 비디오와 pair를 이루고 있는 데이터셋들로 학습을 하게 된다.
이 때, 다른 모달리티들을 image의 embedding space와 align 시키는 과정을 거치게 되는데 이를 "Joint Embedding"이라 부른다.
image embedding space에 align을 시키기 위해 InfoNCE loss로 optimization을 진행했다.
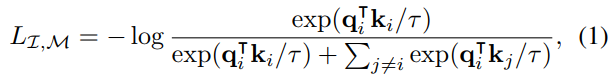
- $I_{i}$: 주어진 이미지
- $M_{i}$: 다른 modality
- $f$, $g$: deep network
- $q_{i}$: $f(I_{i})$로 얻은 normalized embedding
- $k_{i}$: $g(M_{i})$로 얻은 normalized embedding
이를 통해서 $q_{i}$와 $k_{i}$가 joint embedding space 상에서 서로 가까워지도록 학습이 되고,
결과적으로 이미지와 모달리티 간의 align이 맞춰지게 된다.
위 그림 Figure2의 마지막 그림에서 진한 실선으로 이어진 모달리티는 paired dataset에 의해서 align된 모달리티 관계고,
점선으로 이어진 모달리티는 직접적으로 같이 training 된 적은 없지만 전부 image와의 align이 잘 맞춰져 있어
호환이 가능하게 'binding'된 모달리티 관계를 말한다.
Implementation Details
실험에 사용한 모달리티에 따른 인코더 정보는 다음과 같다.
- Image, Video: ViT 사용
- Audio: 128 mel-spectorgram으로 변경 후 ViT 사용
- Thermal image, Depth image: 1-channel image로 처리 후 ViT 사용
- IMU signals: 영상에서 5초간 gyroscope 측정 후 1D convolution 처리하여 얻어진 sequence를 Transformer에 넣음
- Text: CLIP의 text encoder 사용
3. Experiments
보통 'zero-shot'이라고 하면 같은 모달리티 내에서 training 할 때 없었던 class에 대한 예측을 하는 경우가 많다.
예를 들어 (image, text) pair로 이루어진 데이터로 학습된 모델에서
트레이닝 셋에 없었던 text prompt로도 classification이 가능한 지를 테스트 하는 경우가 이에 해당한다.
하지만 본 실험에서는 training할 때 없었던 modality pair에 대해서 zero-shot이 가능한지 테스트한다.
예를 들어 (image, text) 그리고 (image, audio)로 학습된 모델이
(text, audio)에 대해서 classification이 가능한지 평가하게 된다.
이를 'Emergent zero-shot' 이라 부르기로 한다.
Emergent zero-shot Classificaiton
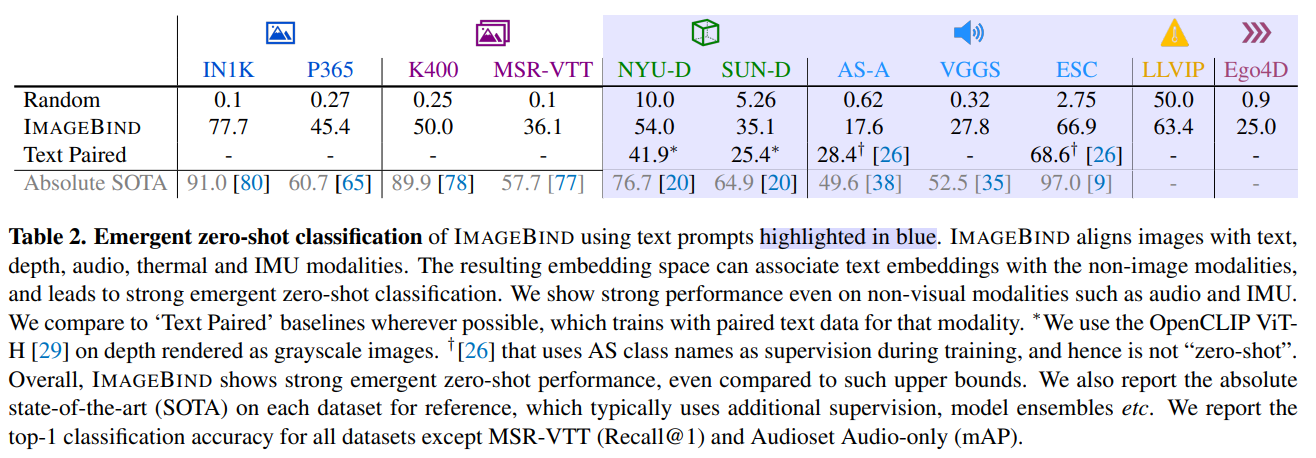
- 본 논문에서 주장했던 모달리티들이 image의 embedding space와 모두 잘 align이 되어 있다면 image 외의 다른 모달리티들 간에도 좋은 성능이 나올 수 있다는 점을 보여주는 실험 결과
- 각 benchmark들의 SOTA(supervised learning으로 진행된 것)들과 비교했을 때는 성능이 좋지 않지만, text embedding이 non-image modalities과도 호환이 잘 된다는 것을 확인할 수 있다.
Comparison to prior work
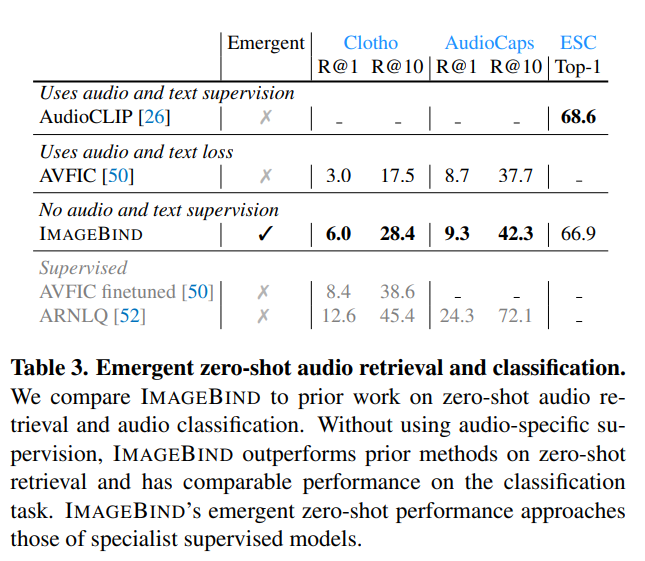
- Zero-shot text to audio retrieval and classification
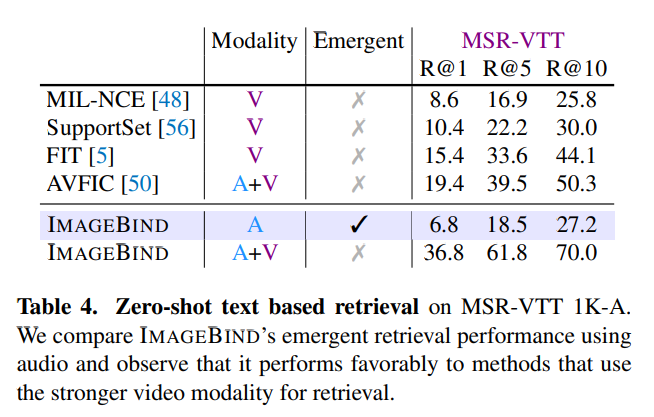
- ImageBind는 'Emergent'한 특징을 가지고 있음에도 불구하고 다른 zero-shot audio retrieval and classification 성능보다 우수한 결과를 보이고 있다.
- audio와 text 모달리티 간의 다리 역할을 해주는 image의 공이 혁혁하다고 볼 수 있다.
- Text to audio and video retrieval
- audio만 사용했을 때도 MSR-VTT 데이터셋에 대해서 우수한 성능을 보이고 있다.
- Table 2에서 볼 수 있듯이 ImageBind의 text to video의 성능은 R@1이 36.1%로 매우 강력한데, audio와 video를 결합하면 성능을 더 올릴 수 있다.
Few-shot classification
- ImageBind의 label efficiency를 평가하기 위해서 audio와 depth에 대한 few-shot classification을 진행
- Few-shot audio classification
- self-supervised 방법으로 학습된 AudioMAE와 supervised 방법으로 학습된 AudioMAE를 비교군으로 설정
- AudioMAE는 ImageBind의 audio encoder와 비슷한 capacity를 가지고 있음에도 self-supervised 방법 모델과는 ~40%의 성능 차이를 보여줌
- supervised 방법과 비교했을 때 2-shot 까지는 더 좋은 성능을 보여주고, 그 이후는 비슷한 성능을 보임
- Few-shot depth classification
- images, depth, semantic segmentation data로 학습한 multimodal MultiMAE와 비교
- ImageBind는 모든 few-shot setting에 대해서 MultiMAE의 성능을 능가함
- 이러한 결과는 image alignment의 중요성을 증명함

Analysis and Applications
- Multimodal embedding sapce arithmetic
- 서로 다른 모달리티를 합쳐서 input으로 제공해 주는 것도 가능하다
- 예를 들어 과일 이미지와 새 소리를 함께 입력해주면, 과일 나무 위에 새가 있는 이미지를 얻을 수 있다

- Upgrading text-based detectors to audio-based
- text-based pretrained 모델인 'Detic'을 사용
- 여기서 CLIP 기반 text embedding을 ImageBind의 audio embedding으로 교체함
- 아무런 training 없이도 audio를 입력했을 때 그에 해당하는 object를 detect하고 segmentation함

- Upgrading text-based diffusion models to audio-based
- pretrained DALLE-2 diffusion model 사용
- 이것의 prompt embedding을 audio embedding으로 대체
- 다양한 종류의 sound로 그럴듯한 image를 생성해낼 수 있음
- 아래 그림의 3)부분 참고

4. Ablation Study
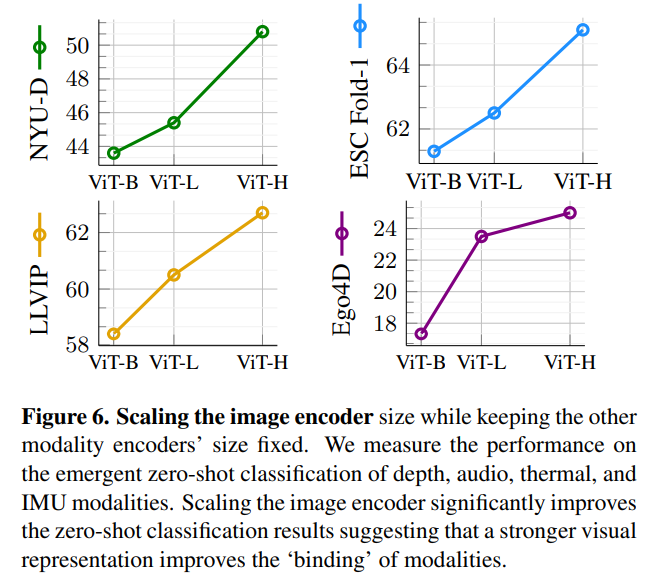
Scaling the Image Encoder
- ImageBind의 키 아이디어는 이미지 임베딩 스페이스와 다른 모달리티 간의 align을 맞춘다는 점임
- 따라서 image encoder가 중요한 역할을 함
- 다른 모달리티들의 encoder의 크기는 고정하고 image encoder의 스케일을 달리하며 실험
- Image encoder의 scale이 커질수록 emergent zero-shot classification에서 좋은 성능을 보임
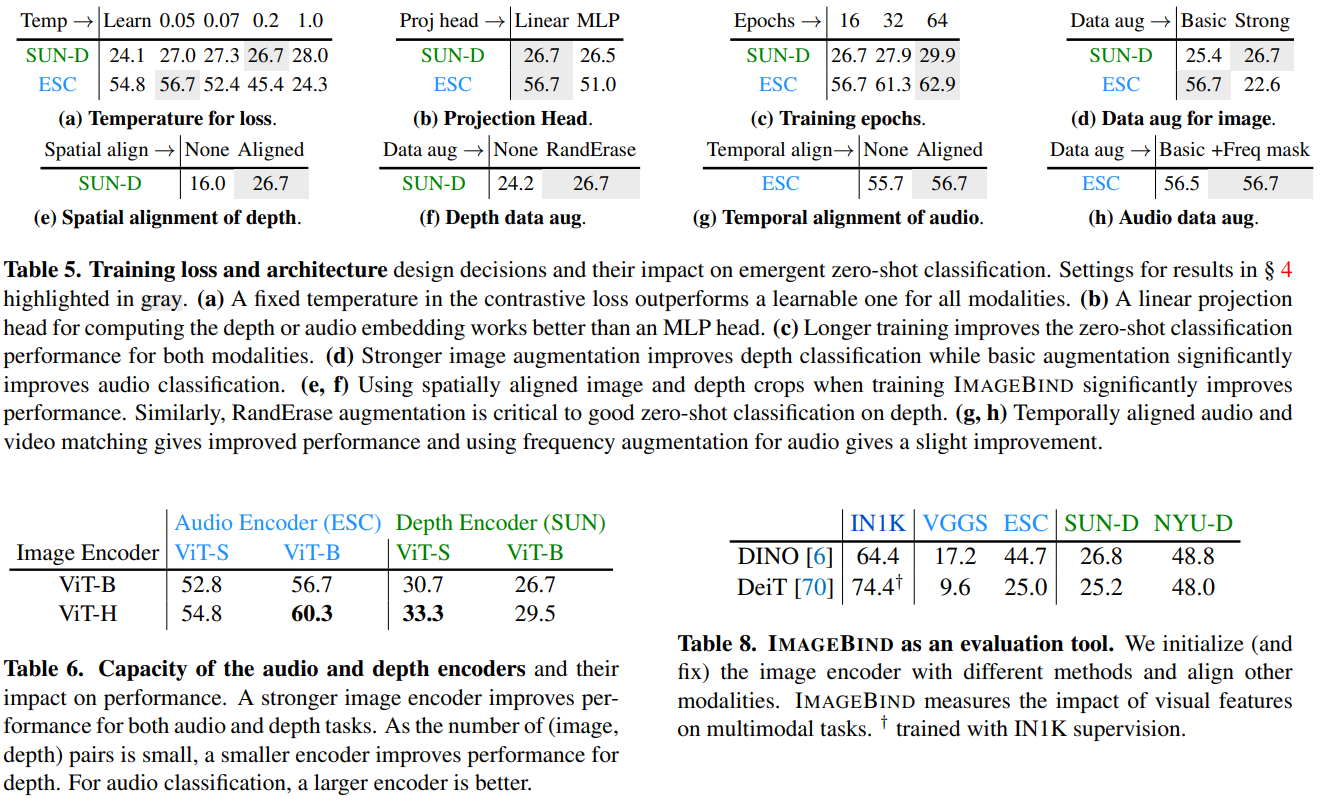
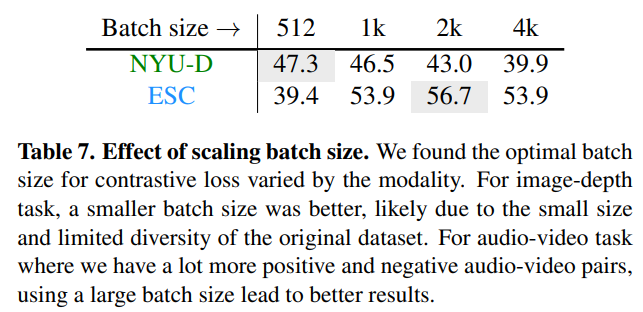
Training Loss and Architecture
- Fixed temperature가 가장 좋은 성능을 보임
- MLP projection head가 좋은 성능을 보인 SimCLR와 달리 Linear Projection이 더 좋은 성능을 보임
- 트레이닝 epoch이 클 수록 좋은 성능을 보임
- audio 데이터셋에서는 기본적인 augmentation만 하는 것이, 다른 데이터셋에서는 strong augmentation까지 같이 하는 것이 좋은 성능을 보임
- 데이터셋에 따라 적합한 batch size가 다름
- supervised DeiT 모델과 self-supervised DINO 모델을 emergent zero-shot으로 성능평가를 했을 때, DINO 모델이 더 좋은 성능을 보임
- 일반적인 vision classification task와의 성능 결과와 완전 일치하는 결과가 아니기 때문에, ImageBind의 emergent zero-shot은 멀티모달 모델에서 새로운 방법의 evaluation tool이 될 수 있음
5. Discussion and Limitations
1. 모든 모달리티 간의 emergent alignmet를 할 수 있는 새로운 방법 제시
2. 이를 통해 cross-modal retrieval과 text-based zero-shot task 수행 가능
3. non-vision task인 Detic과 DALLE-2의 모델들도 ImageBind를 통해서 'upgrade'시킬 수 있음
4. 다른 alignment data와의 loss를 통해서 성능 향상을 할 수 있을 것으로 예상됨 (ex. audio with IMU)
5. emergent zero-shot이라는 새로운 evalution tool을 제안
관련 링크들
ImageBind Blog Link: https://imagebind.metademolab.com/
ImageBind by Meta AI
A multimodal model by Meta AI
imagebind.metademolab.com
ImageBind Demo Link: https://imagebind.metademolab.com/demo
ImageBind by Meta AI
A multimodal model by Meta AI
imagebind.metademolab.com



