
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Prompt란
- Data-centric
- Multi-modal
- deep learning 논문 리뷰
- iclr 논문 리뷰
- Prompt Tuning
- Meta AI
- Self-supervised learning
- iclr 2024
- iclr spotlight
- 논문리뷰
- contrastive learning
- active learning
- Computer Vision
- cvpr 2024
- ai 최신 논문
- CVPR
- Computer Vision 논문 리뷰
- Segment Anything 리뷰
- Segment Anything
- ssl
- VLM
- 자기지도학습
- cvpr 논문 리뷰
- Data-centric AI
- Segment Anything 설명
- deep learning
- 논문 리뷰
- Stable Diffusion
- ICLR
- Today
- Total
Study With Inha
[Paper Review] Dataset Distillation 논문 리뷰 본문
MIT CSAIL, T. Wang et al, Dataset Distillation, 2018
논문 링크: https://arxiv.org/pdf/1811.10959.pdf
1. Introduction
일반적으로 딥러닝에서는 대용량의 데이터셋으로 큰 모델을 학습시키는 것이 좋은 성능을 내고 있다.
하지만 그 경우 많은 메모리, 노동력, 시간 등등의 자원이 필요하므로 효율성 측면에서 좋은 학습 방법이라고 말하기는 어렵다.
그래서 많은 연구진들이 적은 자원으로 최대한의 효율을 낼 수 있는 방법론들에 대한 연구를 진행했고,
본 논문에서 소개하는 'Dataset Distillation (데이터셋 증류)' 도 그 중 하나라고 볼 수 있다.
데이터셋 증류란 대규모 데이터셋을 대표되는 몇 장의 합성 이미지로 압축한 뒤,
그 압축된 이미지로만 학습시켜서 전체 데이터셋으로 학습한 것과 비슷한 퍼포먼스를 내는 것을 말한다.
예를 들면 10개의 classes, 그리고 전체 60,000장의 training images를 포함하고 있는 MNIST 데이터셋을
클래스 당 한 개의 합성 데이터로 압축시킨 단 10장의 이미지로 모델을 학습하는 것이다.
전체 데이터셋을 모두 활용하여 학습한 모델의 경우 99%의 정확도를 보였는데,
같은 모델로 dataset distillation을 거친 10장의 이미지로만 학습했을 때 94%의 정확도를 얻을 수 있었다고 한다.

성공적인 Dataset Distillation의 장점은 다음과 같다.
- 적은 이미지로 학습을 할 수 있게 되어 학습 시간을 줄여줄 수 있다.
- 데이터셋을 저장하는 데에도 많은 메모리가 드는데 이를 아껴줄 수 있다.
- 여러 장의 real-world 이미지들을 몇 장의 '합성' 이미지로 재생산해 사용하기 때문에, privacy 문제 등을 해결 할 수 있다.
2. Related Works
- Knowledge Distillation
: DD (Dataset Distillation)과 '증류'를 한다는 개념 자체는 비슷하나, '무엇'을 증류하는가의 차이가 있다.
Knowledge Distillation의 경우 거대한 모델에서 학습한 지식 (Knowledge)를 작은 모델로 증류하여
작은 모델에서도 큰 모델에서의 성능과 비슷한 성능을 낼 수 있도록 하는 것을 목표로 한다.
- Active Learning
: DD와 같이 적은 이미지로 전체 데이터셋을 쓴 것과 비슷한 성능을 내는 것을 목표로 한다는 점에서 비슷한 점이 있다.
하지만 Active Learning의 경우 데이터셋의 전체 이미지에서 학습에 큰 도움을 주는 몇 장의 이미지만 선별한는 방법을 연구하는 것이라면,
DD의 경우 전체 이미지들을 몇 장의 이미지에 압축한 합성 데이터로 학습하는 것이 차이이다.
따라서 Active Learning에서는 선별된 이미지 그대로를 사용하지만 DD의 경우 real-world 이미지를 그대로 사용하지 않는다.
Active Learning의 대표적인 방법인 'Core-set'에 대한 논문 리뷰는 아래에서 확인할 수 있다.
[Paper Review] Core-set: Active Learning for Convolutional Neural Networks 리뷰
Core-set: Active Learning for Convolutional Neural Networks 논문 링크: https://arxiv.org/abs/1708.00489 Active Learning for Convolutional Neural Networks: A Core-Set Approach Convolutional neural networks (CNNs) have been successfully applied to many r
2na-97.tistory.com
3. Approach
3.1. Optimizing Distilled Data
- 보통 모델의 파라미터는 아래와 같이 매 iteration마다 현재 파라미터에 learning rate $\times$ loss 계산 결과를 빼면서 새롭게 설정된다.
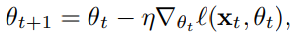
- 본 논문에서는 합성 데이터셋 ($\widetilde{x}$) 과 기존 데이터셋 ($x$)간의 차이를 없애는 것이 목표다. 따라서 합성 데이터셋에 대해서는 다음과 같은 방식으로 모델의 파라미터가 정해진다.
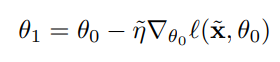
- 그리고 $\widetilde{x}$와 $\widetilde{\eta}$는 아래 식과 같이 기존 데이터셋과의 차이를 줄이는 loss를 통해서 얻을 수 있다.
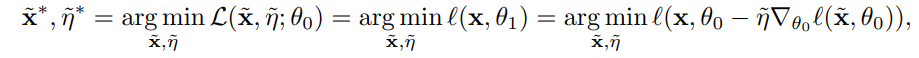
3.2. Distillation for Random Initialization
- 위 식에서는 initial parameter인 $\theta_{0}$에 따라서 결과가 달라지기 때문에, 다른 파라미터에 대한 generalization이 부족하다는 문제가 생긴다.
- 따라서 아래 psuedo code에서 볼 수 있듯 랜덤한 분포 $p(\theta_{0})$에 대해서 optimization을 진행하여 보지 않은 initialization에 대해서도 좋은 성능을 낼 수 있도록 했다고 한다.

3.4. Multiple Gradient Descent Steps and Multiple Epochs
- 위에서는 한 에폭만 거쳐서 얻은 $\theta_{1}$을 사용했다면, 여러 번의 epoch를 통해서 $\theta$를 업데이트 할 수도 있다. 그 경우 위 psuedo code에서 Gradient Descent하는 부분 (코드의 6번째 줄)을 아래와 같이 고치면 된다고 한다.
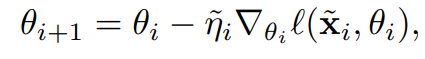
4. Experiments
4.1. Dataset Distillation
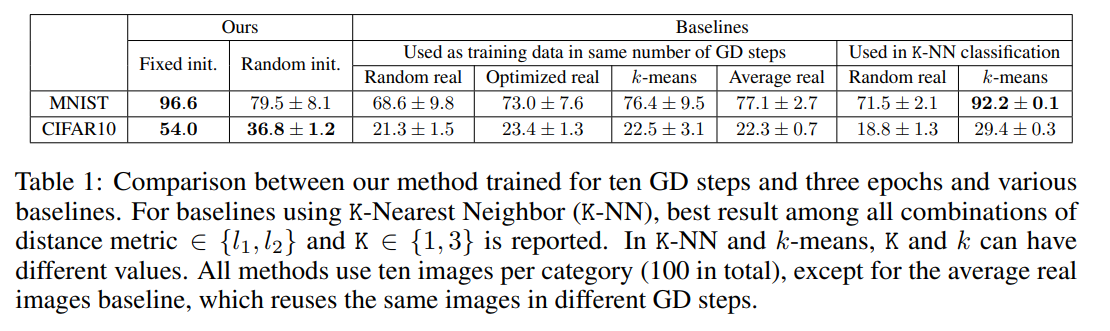
- Fixed Initialization: 1epoch만으로 class 당 단 한 장의 이미지로 압축한 DD에 대해서 실험했을 때
- MNIST의 경우 initial accuracy 12.90% $\to$ 93.76%의 결과
- CIFAR 10의 경우 initial accuracy 8.82% $\to$ 54.03%의 결과

- Random Initialization: 3epoch을 통해서 얻어낸 DD 데이터셋의 테스트 결과
- MNIST: 79.5%
- CIFAR10: 36.79%
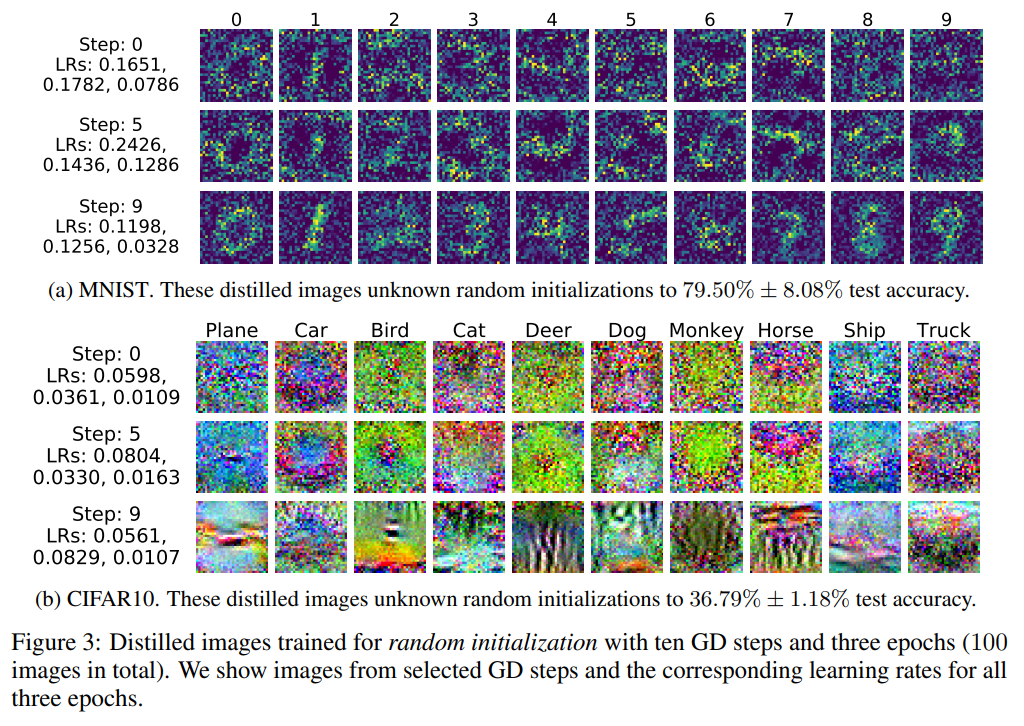
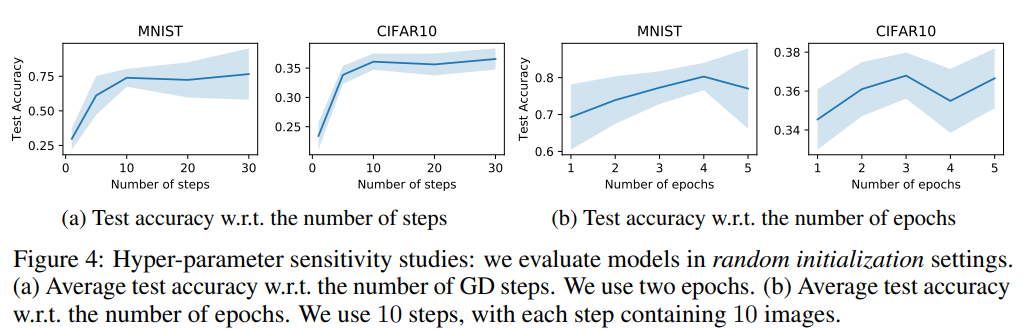
- Multiple GD steps and Multiple Epochs
- 위의 Figure 3에서 보면, 초반 step의 이미지들이 조금 더 noiser해보이고 step이 계속될수록 노이즈가 줄어드는 것 같은 양상을 보인다고 한다.
- step을 늘릴 때와 epoch을 늘렸을 때의 test 결과를 보면 더 늘어날수록 좋은 결과를 보이고 있다고 한다.
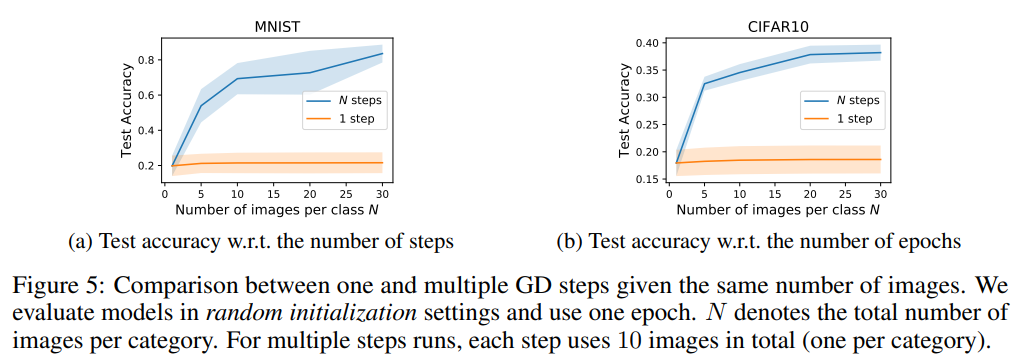
- 클래스 당 DD로 저장할 이미지의 개수(N)를 달리 했을 때 1 step만 거친 것과 N step을 거친 것을 비교 했을 때의 결과를 보면 차이가 더 극명한 것을 확인할 수 있다.
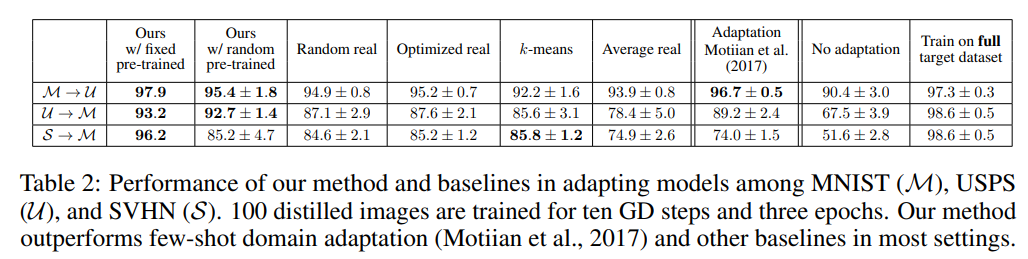
- Fixed and Random Pre-trained Weights on Digits
- 숫자에 관련된 세 가지 데이터셋 (MNIST, USPS, SVHN)에 대해서 digit 데이터셋 중 어느 한 데이터셋으로 pretrain 시킨 뒤 다른 digit 데이터셋으로 adaptation을 진행했을 때 좋은 성능을 보이고 있음을 입증했다.
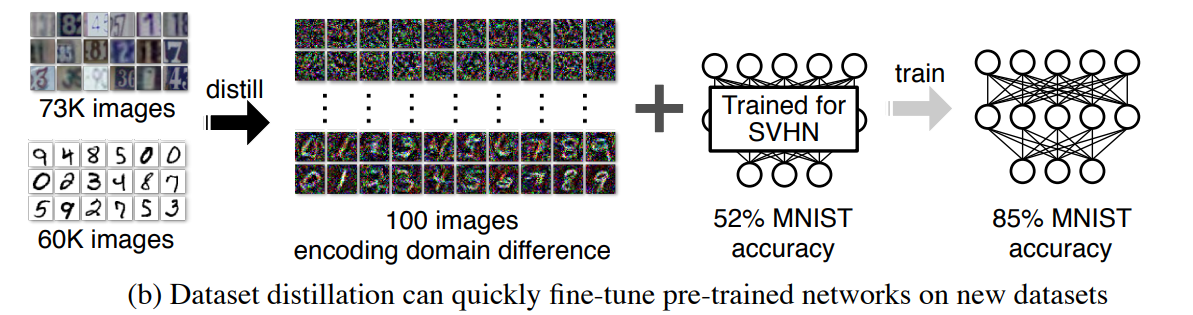
- Fixed Pre-trained Weights on ImageNet
- ImageNet 데이터셋으로 pretrain된 AlexNet 모델의 weight를 fix한 뒤 클래스 당 하나의 DD를 생성해 학습시킨 뒤 다른 데이터셋에 대해서 테스트해 보았을 때 우수한 성능을 보이고 있다.

- Random Pre-trained Weights and a Malicious Data-poisoning Objective
- 데이터셋 증류 방법은 모델에게 혼란을 주는 데이터를 생성하는 데에도 사용할 수 있다.
- 단순히 공격 대상이 되는 클래스 K를 정답이 아닌 다른 클래스 T로 설정한 뒤 DD 단계를 거치고 나면 모델의 정확도는 현저히 낮아지게 된다.
- 잘 학습된 모델에 대해서 잘못된 레이블을 주어 attacking하는 단 한 번의 GD step을 거쳤을 때의 결과는 아래와 같다.

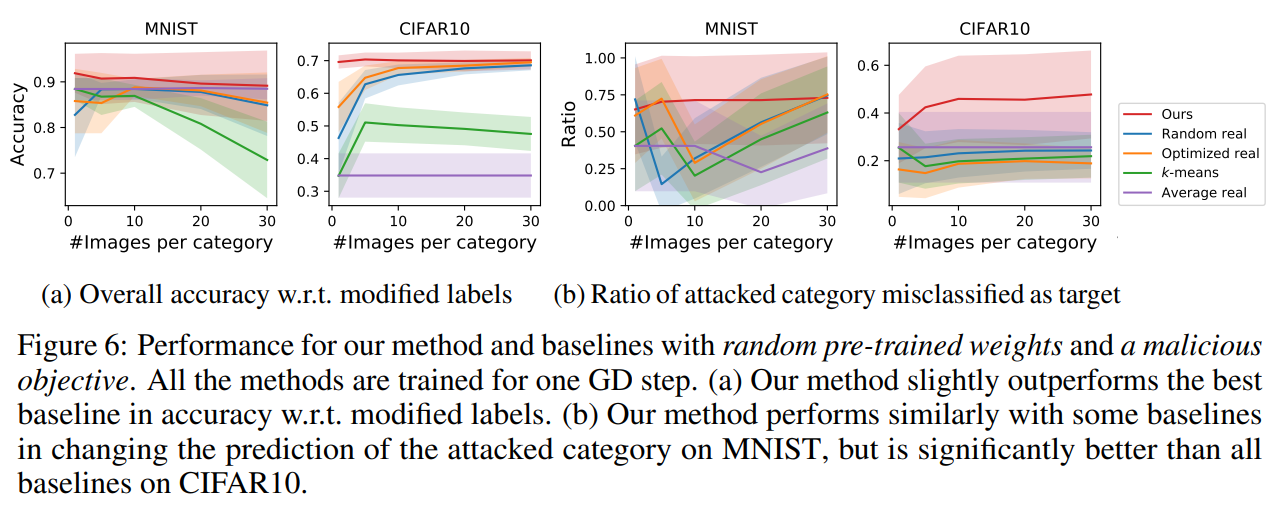
5. Discussion
- 'Dataset Distillation'이라는 개념을 처음으로 선보인 논문
- pretraining weight을 활용하는 방법이나, data-poisoning attack을 하는 방법 등 새롭게 활용 가능한 방안에 대해서도 제시함
- MNIST에 대해서는 좋은 성능을 보이나, CIFAR10에 대해서는 비교적 낮은 성능을 보이고 있다. 따라서 CIFAR 10 뿐만 아니라 large-scale dataset에 대해서도 좋은 성능을 보이는 방법에 대한 추가 연구가 필요하다.
- 아직은 initialization이 어떻게 되었느냐에 따라서 성능이 많이 달라지기 때문에, 이러한 dependency를 낮추는 것에 대한 연구도 필요하다.



