
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- deep learning
- Meta AI
- Segment Anything 설명
- ssl
- contrastive learning
- CVPR
- Data-centric AI
- Self-supervised learning
- Segment Anything 리뷰
- Data-centric
- iclr 2024
- 자기지도학습
- Stable Diffusion
- Computer Vision
- cvpr 논문 리뷰
- Multi-modal
- 논문리뷰
- VLM
- iclr spotlight
- iclr 논문 리뷰
- ai 최신 논문
- Computer Vision 논문 리뷰
- Prompt란
- 논문 리뷰
- Segment Anything
- cvpr 2024
- deep learning 논문 리뷰
- ICLR
- active learning
- Prompt Tuning
Archives
- Today
- Total
Study With Inha
[Paper Review] Core-set: Active Learning for Convolutional Neural Networks 리뷰 본문
Paper Review
[Paper Review] Core-set: Active Learning for Convolutional Neural Networks 리뷰
강이나 2023. 3. 22. 15:18Core-set: Active Learning for Convolutional Neural Networks
논문 링크: https://arxiv.org/abs/1708.00489
Active Learning for Convolutional Neural Networks: A Core-Set Approach
Convolutional neural networks (CNNs) have been successfully applied to many recognition and learning tasks using a universal recipe; training a deep model on a very large dataset of supervised examples. However, this approach is rather restrictive in pract
arxiv.org
Active Learning
- aims to select a small subset of the data that contains the most informative and diverse samples for training the CNNs, which can lead to better model performance with fewer labeled samples
- 말하자면 annotation cost를 낮추고 싶어서 몇 개의 subset만 labeling하여 트레이닝을 시키고 싶을 때, 어떤 subset에 labeling을 해야 가장 효율적일까?
- 모델이 학습될 때 더 도움이 되는 subset에 labeling을 하면 적은 label로도 전체를 labeling한 효과, 혹은 그에 준하는 효과가 나타날 수 있다는 가정.
- active learning은 레이블링을 진행할 가장 효율적인 subset을 고르는 것을 목표로 하는 것.
- Self-supervised learning 혹은 Weakly-supervised learning이 이미 소수의 데이터셋이 label된 것을 어떻게 활용할까?를 고민하는 분야라면, Active Learning은 그 이전에 어떤 데이터셋을 label하는 것이 좋을까?를 고민하는 분야임.
Core-set Approach
- It selects a diverse set of samples that capture the variation in the data
- It is done by using a k-means clustering on the feature representations of the unlabeled data, and then selecting the most representative samples from each cluster to form the core-set.
- 전체 데이터셋의 수가 n개라고 할 때, labeled된 데이터 수에 상관없이 center가 되는 데이터의 set이 모든 데이터를 커버할 수 있는 것을 목표로 함. → 레이블 있어도 되고 없어도 상관 없는 방법론임 (“a set s is a δ cover of a set s⋆” means a set of balls with radius δ centered at each member of s can cover the entire s⋆)
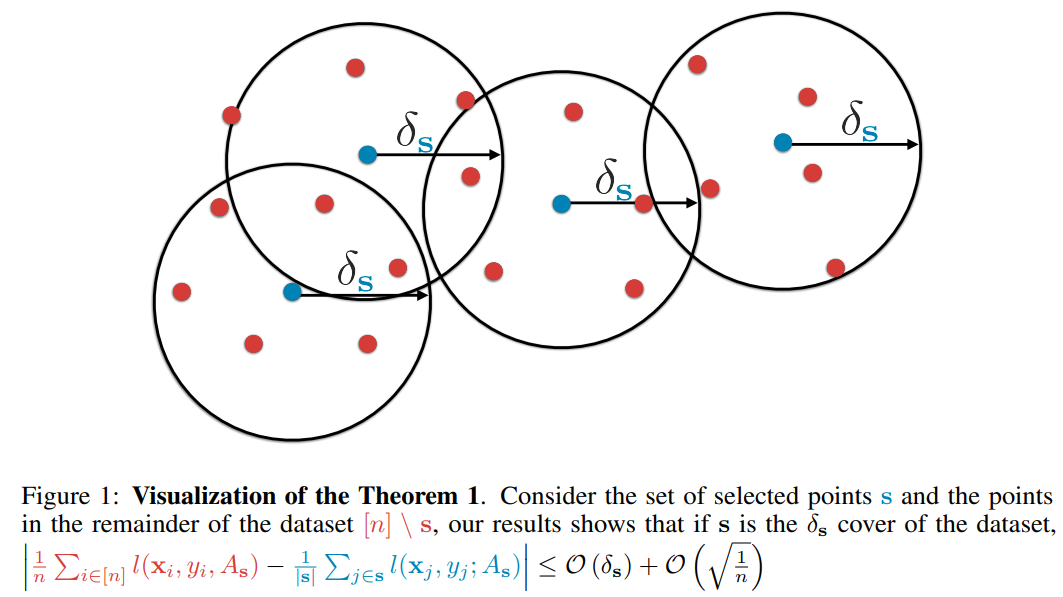
- “Most representative samples”: The samples that are farthest from the centroid are considered the most representative samples. (= decision boundary에 위치한 것이 가장 informative한 샘플이라고 간주하는 것)
- The authors propose to use a measure called "core-set loss" to rank the samples in the core-set based on their potential to reduce the model's error. The samples with the highest core-set loss are considered the most informative and are labeled.

💡 Procedure
- Feature extraction: The first step is to extract features from the unlabeled data using a pre-trained CNN. The pre-trained CNN can be either a general-purpose CNN, such as VGG or ResNet, or a CNN that has been specifically trained on the target dataset.
- K-means clustering: The next step is to cluster the feature vectors of the unlabeled data into k clusters using a k-means clustering algorithm. The number of clusters, k, is a hyperparameter that needs to be set based on the size and complexity of the dataset.
- Core-set selection: After clustering the feature vectors, the core set is selected by choosing the most representative samples from each cluster. The representatives are chosen based on their distance to the cluster center, with the goal of selecting samples that are diverse and informative. The size of the core set is another hyperparameter that needs to be set.
- Fine-tuning: Finally, the CNN is fine-tuned on the core set, using either the labeled samples from the core set only or a combination of labeled and unlabeled samples from the original dataset.
Results
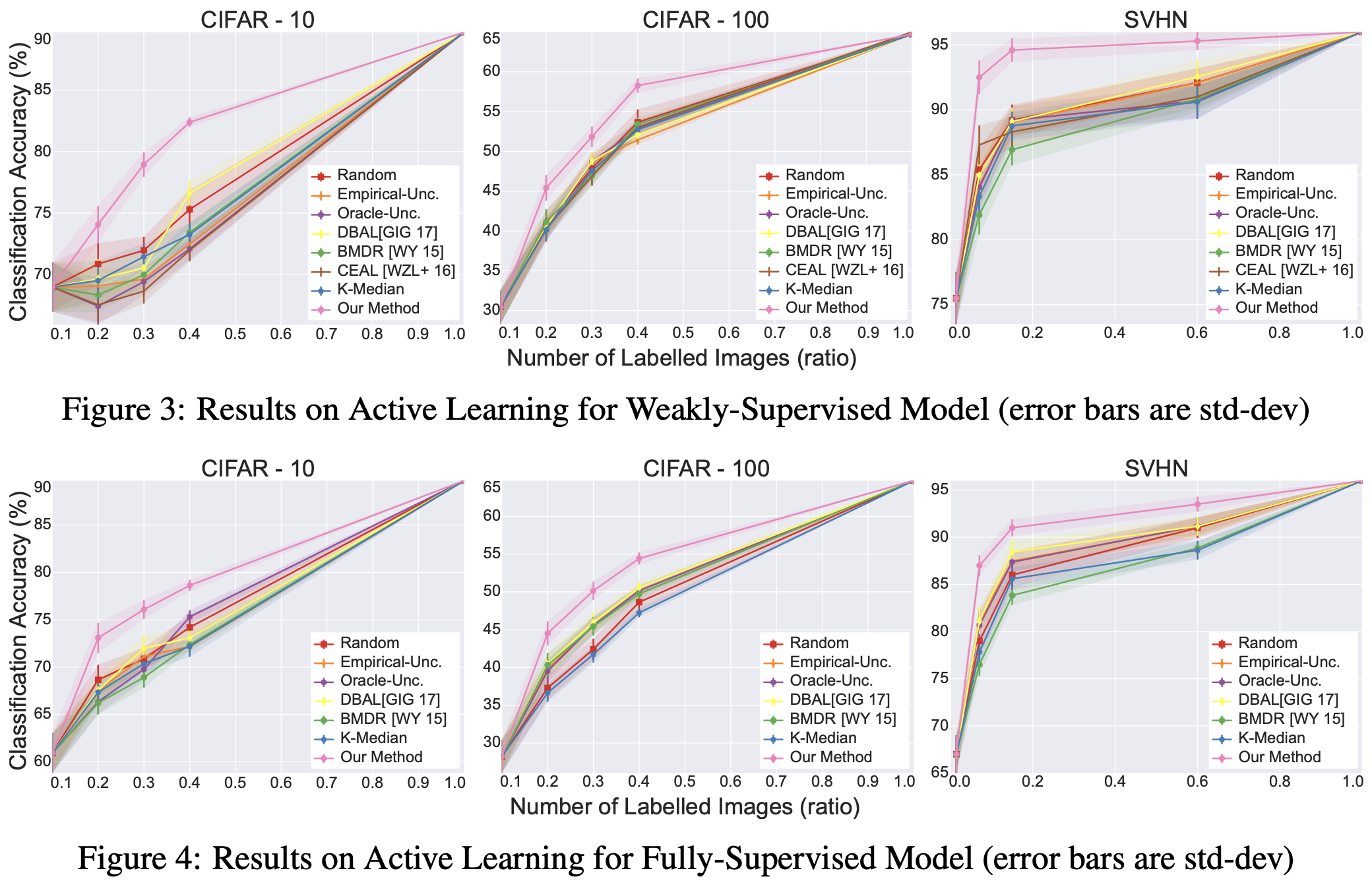
Compare with other methods
- Weakly-Supervised Model = labeled data + unlabeled data
- Fully-Supervised Model = only labeled data
- CIFAR 100에서는 비교적 약한 성능 상승
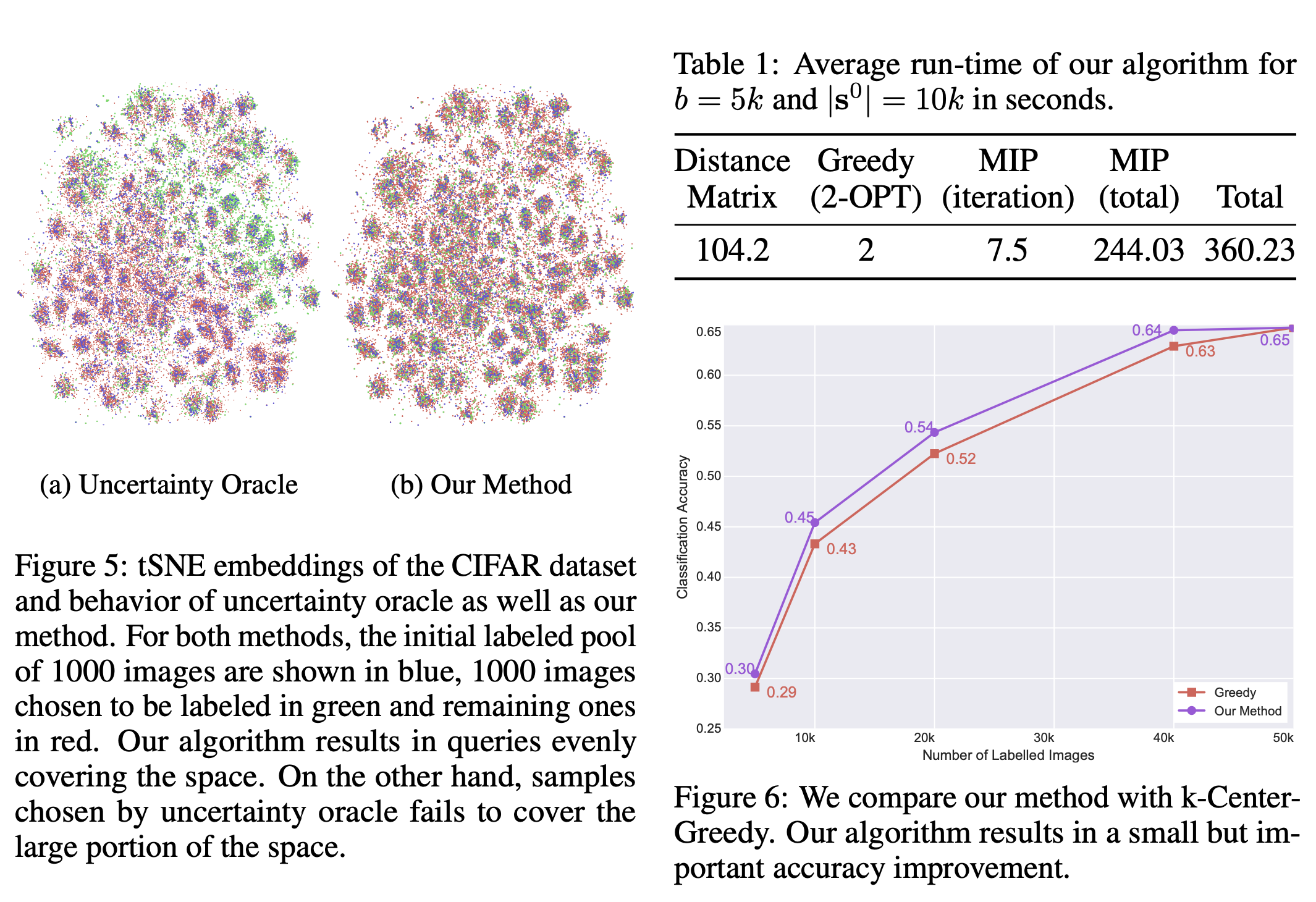
t-SNE visualization & Compare with other centering algorithms
- Overall, the difference between k-Center-Greedy and the Core-set active learning method is the approach to selecting representative samples. k-Center-Greedy selects the farthest samples, while Core-set active learning selects a subset of representative samples that are informative for the model's decision boundary.
- 기존 k-Center-Greedy 알고리즘은 center에서 가장 먼 것이 가장 우선순위가 높음
- 대신 Core-set algorithm은 다른 ball과 겹치는 영역 (=decision boundary) 에 있으면 가장 우선순위가 높음.
- 따라서 결과는 거의 비슷하나 미약하게 Core-set algorithm이 더 우위에 있다
Conclusion
- Active Learning은 Self-supervised 혹은 Weakly-supervised learning 이전에 생각해볼만한 문제에 대해서 연구하는 분야라고 생각이 됨
- 아직 많이 탐구되지 않은 영역으로 앞으로 무궁무진하게 할 수 있는 것이 많을 것 같음
- 함께 보면 좋을 사이트 (Lightly AI)
- 함께 보면 좋을 논문 발표 자료 (추후 업데이트 예정)
반응형
'Paper Review' 카테고리의 다른 글
'Paper Review' Related Articles
more




Comments