
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 자기지도학습
- Meta AI
- iclr spotlight
- VLM
- Computer Vision 논문 리뷰
- iclr 2024
- 논문리뷰
- Segment Anything
- deep learning 논문 리뷰
- active learning
- ssl
- Self-supervised learning
- 논문 리뷰
- contrastive learning
- cvpr 논문 리뷰
- Multi-modal
- Data-centric AI
- cvpr 2024
- Data-centric
- Segment Anything 설명
- ai 최신 논문
- Stable Diffusion
- deep learning
- iclr 논문 리뷰
- Computer Vision
- Segment Anything 리뷰
- ICLR
- Prompt란
- CVPR
- Prompt Tuning
- Today
- Total
Study With Inha
[Paper Review] Segment Anything Model (SAM) 자세한 논문 리뷰, Meta의 Segment Anything 설명 본문
[Paper Review] Segment Anything Model (SAM) 자세한 논문 리뷰, Meta의 Segment Anything 설명
강이나 2023. 4. 11. 15:35Meta AI, Segment Anything, Alexander Kirillov et al.
논문 링크: https://ai.facebook.com/research/publications/segment-anything/
(SAM 후속 논문 리뷰 링크) Meta AI, SAM 2: Segment Anything in Images and Videos 논문 리뷰 및 SAM2 설명
[Paper Review] Meta AI, SAM 2: Segment Anything in Images and Videos 논문 리뷰 및 SAM2 설명
Meta FAIR SAM 2: Segment Anything in Images and Videos SAM2 설명 및 논문 리뷰Paper: SAM2 Paper LinkDemo: https://sam2.metademolab.comCode: https://github.com/facebookresearch/segment-anything-2 Website: https://ai.meta.com/sam2 Meta Segment Anythin
2na-97.tistory.com
1. Introduction
2023년 4월 5일에 Meta AI가 공개한 Segment Anything이라는 논문은 모든 분야에서 광범위하게 사용할 수 있는 image segmentation model 에 대해서 설명하고 있다.
앞으로 segmentation 관련 연구들의 foundation이 되는 모델이 될 수 있도록 하는 것이 목표라는 엄청난 포부로 시작된다...
이 때문에 광범위한 대용량 데이터셋 (SA-1B)을 새롭게 만들고, 이것으로 학습을 시켜 powerful generalization을 시켰다고 한다.
"prompt-engineering"을 통해서 새로운 데이터 분포에서 다양한 task를 수행할 수 있도록 했다고 한다.
prompt 라는 개념 및 이것을 computer vision에 도입한 초석이 되는 논문에 대한 내용은 아래 리뷰를 참고하면 좋을 것 같다.
(prompt라는 개념이 본 논문에서 중요한 역할을 하므로 꼭 공부하고 해당 논문을 읽어보길 권장한다)
2023.03.27 - [Paper Review] - [Paper Review] Visual Prompt Tuning, ECCV 2022 논문 리뷰
[Paper Review] Visual Prompt Tuning, ECCV 2022 논문 리뷰
ECCV 2022, Visual Prompt Tuning, M. Jia et al. 논문 링크: https://arxiv.org/pdf/2203.12119.pdf 1. Introduction 최근 GPT 계열 모델과 같이 대규모 데이터와 대규모 모델을 활용한 딥러닝 연구가 많아졌다. 그러한 데이터
2na-97.tistory.com
visual prompt tuning이라는 논문을 굉장히 재밌게 읽었는데, 이 논문을 읽은 직후에 Meta AI에서 관련 연구가 나와서 굉장히 신기했다.
본 논문에서 소개하는 Segment Anything Model (SAM)에서는 크게 세 가지 요소가 필요하다고 한다.
- Prompt: promptable segmentation. Training sample들에 대해서 prompt들을 simulation한 후 모델의 prediction과 GT를 비교하는 것.
- Model: prompt+image를 input으로 받아 실시간으로 mask를 prediction하는 모델.
- Data: diverse+large-scale 데이터로 학습시키는 것.
이렇게 학습된 모델의 성능을 평가하기 위해서 추가적인 훈련 없이 pre-trained 모델을 새로운 task에 적용할 수 있는 Zero-shot transfer 내용에 대해서도 실험을 진행하여 좋은 성능을 이끌어냈다.
Inference를 할 때 prompt가 주어진 경우에는 prompt encoder를 통해서 해당 prompt의 embedding과 image embedding을 합쳐서 최종 mask를 예측하고,
prompt가 주어지지 않은 경우에는 전체 이미지를 grid로 나누어 grid의 point들을 prompt로 제공하여 전체 이미지에 대해서 최종 mask를 예측하게 된다.
2. Segment Anything Task
NLP 분야에서 처음 도입된 prompt enginnering이라는 것에서 감명을 받았다고 한다.
prompt에 대한 간단한 설명은 아래와 같다. (자세한 것은 위에서 언급한 포스팅을 참고하면 좋을 것 같다)
- Prompt in NLP
'prompt'라는 개념은 NLP에서 처음 도입된 것이다.
ChatGPT와 같은 Generative Model의 경우 사용자가 특정한 task를 요구하게 된다.
예를 들어서 "이 기사는 스포츠에 관련된 것이야 혹은 정치에 관련된 것이야?"라고 물어보면 해당 기사의 카테고리를 '분류'하는 문제가 된다.
"(주어)가 (분류1)일까 혹은 (분류2)일까?" 라는 prompt와 함께 학습된 경우, 위에 해당하는 질문이 분류에 해당하는 문제임을 알 수 있다.
혹은 질문에 대한 대답을 하기 위한 prompt도 있다.
보통 "한국의 현재 대통령은 누구야?"라고 물은 경우 "한국의 현재 대통령은 [정답]입니다" 라고 대답하게 된다.
이처럼 prompt는 어떤 질문을 했을 때 매끄러운 답변을 하는 guidance를 만들어주는 역할도 할 수 있게 된다.
이처럼 task에 대한 guide를 제공하는 역할을 하는 prompt와 함께 학습하게 되면,
적은 양의 labeled data로도 좋은 성능을 보일 수 있으며 generalization에 뛰어나기 때문에 다양한 downstream 테스크에 대해 쉽게 학습할 수 있도록 하는 데에 도움을 준다.
- Segment Anything Task with Prompt Enginnering
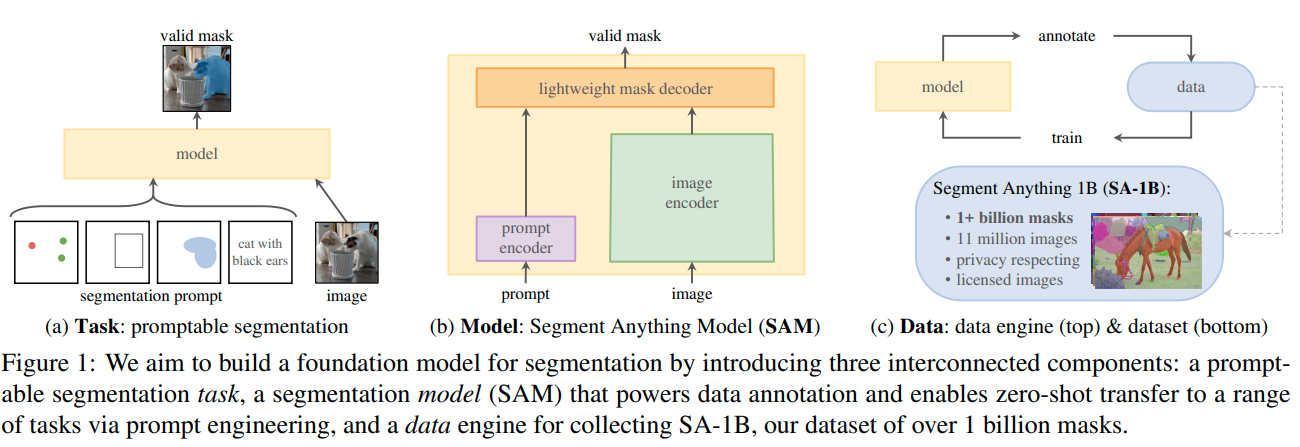
- Task: SAM 모델에서의 prompt는 다양한 것이 될 수 있다. 위 그림의 (a)에서 볼 수 있듯이 foreground와 background를 구분하는 점이 될 수도 있고, 러프한 bbox나 mask가 될 수도 있다. 그리고 타겟에 대해서 설명한 글이어도 상관없다. 이처럼 mask를 생성하고자 하는 대상에 대한 정보를 담은 어떤 것이든 prompt가 될 수 있다. 이를 통해서 다양한 downstream에 대해서 zero-shot transfer가 가능했다고 한다.
- Pre-training: prompt와 image를 함께 받아와서 대용량 데이터셋으로 valid한 mask를 생성해내는 pre-training을 한다. 이 때 'ambiguous'한 prompt에 대해서도 학습했다고 한다. 이렇게 ambiguous prompt와 함께 학습시켰을 때 어떠한 prompt가 오더라도 valid한 mask를 생성해 낼 수 있었다고 한다.
- 'ambiguous'한 prompt란?: 예를 들어서 셔츠를 입고 있는 사람에서 셔츠에 prompt point가 찍혔다고 생각해보자. 그러면 이것이 사람 전체를 뜻하는 것인지, 아니면 셔츠만 타겟하는 것인지 알 수가 없다. 이런 경우 'ambiguous'하다고 한다.

- zero-shot transfer: pre-training을 통해서 어떠한 prompt가 오더라도 valid한 마스크를 생성할 수 있는 모델이 있기 때문에, zero-shot transfer가 가능하다고 한다. 예를 들어 고양이에 bounding box가 쳐져 있다면, 이를 통해서 별다른 학습 없이 고양이를 segmentation하는 것이 가능하다.
- related tasks: segmentation에는 다양한 종류가 있다. 예를 들어, edge detection, super pixelization, interactive segmentation, object proposal generation, foreground segmentation, panoptic segmentation 등등이 있다. SAM은 prompt engineering을 통해 이렇게 다양한 task에 적용할 수 있다고 한다. 존재하는 다양한 object detector와 결합하여 사용할 수도 있다는 점에서 확장 가능성이 크다고 한다.
- Data Engine: prompting은 powerful한 방법이기하나 이미지의 prompt에 대해서 mask GT를 만드는 것도 human cost가 드는 일이다. 따라서 fully human annotated dataset을 사용하기 보다는 "data engine"을 통해서 GT를 생성했다고 한다. 처음에는 사람이 생성한 GT로 학습을 하고 (assisted-manual), 그 후에는 사람이 생성한 것과 generate된 마스크를 함께 학습하고 (semi-automatic), 마지막에는 foreground에 대해서 point가 주어진 prompt로 생성된 mask를 통해서만 학습했다고 한다. 이를 통해서 SA-1B라는 거대한 데이터셋을 만들 수 있었다고...

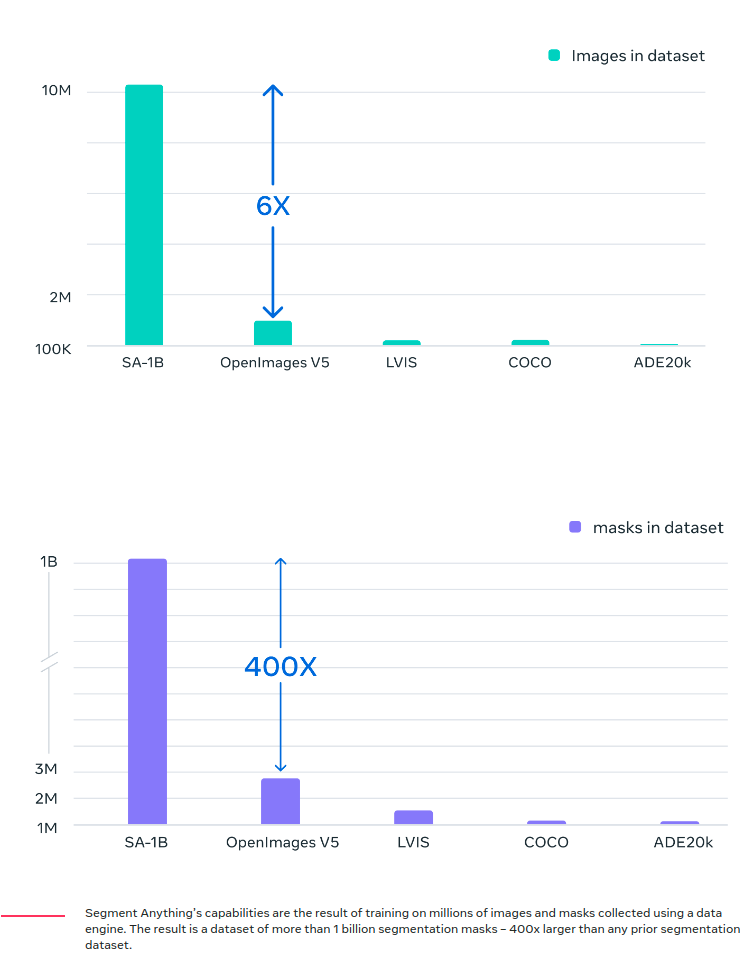
그 결과 현존하는 다른 데이터셋보다 더 많은 이미지, 그리고 이미지 당 마스크의 개수가 평균 100개 정도 되므로 더 많은 마스크 GT가 있다고 한다.
3. Segment Anything Model
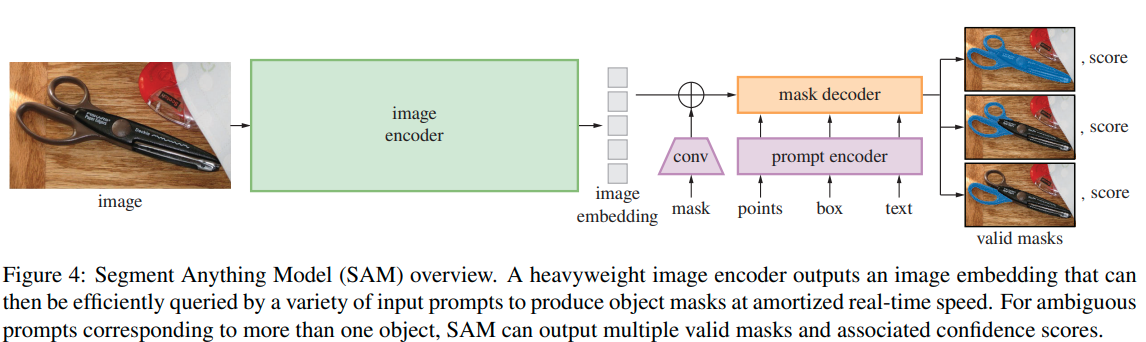
모델 구성
- Image Encoder: scalability하고 powerful한 툴인 MAE pretrained ViT 모델을 사용했다고 한다...
- Prompt Encoder: 두 가지 종류의 prompt가 있다.
> sparse: points, boxes, text가 있음. point 혹은 box의 경우 positional encoding을 합쳐서 임베딩을 만들었고, text의 경우 CLIP의 text encoder를 활용했다고 한다.
> dense: masks가 있다. 이 경우는 일반적인 convolution 연산을 통해서 임베딩을 생성한 뒤, 이미지와 element-wise로 합쳤다고 한다. - Mask Decoder: image embedding과 prompt embedding을 받아서 mask를 생성해낸다. Transformer Decoder 구조를 따랐으며 head에 dynamic mask prediction이 가능하도록 수정만 조금 했다고 한다. 전체 임베딩을 업데이트하기 위해 prompt-to-image와 image-to-prompt로 양방향으로 self-attention과 cross-attension을 수행했다고 한다.
모델 설정
- Resolving Ambiguity: ambiguous한 prompt가 주어졌을 때의 성능을 향상하기 위해서 한 prompt에 대해서 3개의 prediction mask를 생성했다고 한다 (whole, part, and subpart). backprop시에는 마스크들 중에서 minimum loss를 가지고 있는 것에 대해서만 시행했다.
- Efficiency: 미리 계산된 image embedding에 대해서 prompt encoder와 mask decoder가 돌아가는 것은 50ms 이내에 가능하다고 한다. 이것은 real-time interactive prompting이 가능한 수준이라고 한다.
- Losses and Training: Focal loss와 Dice loss를 linear하게 합쳐서 사용했다고 한다.
4. Segment Anything Data Engine
위에서 설명한 Data Engine을 단계별로 조금 더 자세히 설명하는 섹션이다.
논문에서는 SA-1B의 데이터 엔진을 "model-in-the-loop" 라는 표현으로 설명하기도 했다.
총 세 가지 단계로 진행되는데, 단계를 거칠수록 automatic해진다고 보면 된다.
- Assisted-manual stage: segmentation tool을 사용하여 몇 번의 클릭으로 breif한 segmentation mask를 얻은 다음 사람이 세부 수정을 하는 식으로 진행되었다고 한다.
- Semi-auomatic stage: 사람이 직접 라벨링한 mask GT와 모델이 예측한 mask를 함께 섞어서 쓰는 단계이다. 정확도를 유지시키면서도 human cost를 줄여가는 단계다.
- Fully automatic stage: 모든 것을 모델이 예측한 mask로 학습하는 단계이다. 이를 통해서 1B이라는 거대한 이미지 데이터셋에 대해 높은 정확도를 가진 segmentation mask를 사람의 노동력 없이 만들어낼 수 있었다고 한다. 이 때 prompt의 경우 32x32의 grid point들을 주었기 때문에, 모델이 예측한 mask를 쓰는 것이 ambiguity-aware한 model을 만드는 데에도 도움이 되었다고 한다. (grid point가 subpart에 있으면 subpart에 대한 mask를 내놓을 것이고, whole part의 경우 전체를 내놓기 때문에) Post-processing 단계를 거쳐서 조금 더 mask를 정교화시켰는데, confidence score가 높고 probability map을 고려하여 stable한 mask를 선택했으며 NMS까지 거쳐서 최종 mask를 얻었다고 한다.
5. SA-1B Dataset
SA-1B와 다른 데이터셋들을 비교하는 섹션이다.
이 데이터셋은 아래와 같이 홈페이지에서 현재 다운받을 수 있는 것 같다.
데이터셋 링크 : [https://segment-anything.com/dataset/index.html]
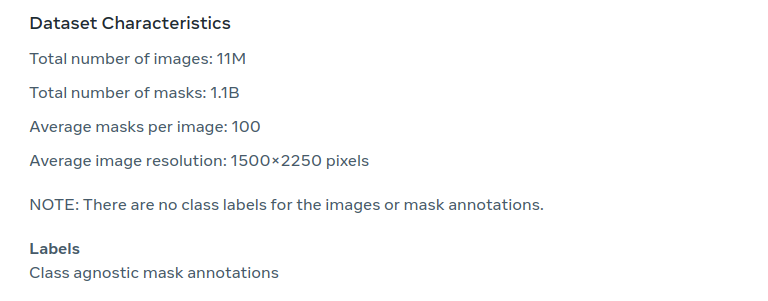
데이터셋에 대한 요약을 하자면 아래와 같다.
segmentation mask는 instance별로 존재하지만, 각 instance가 무엇인지는 명시되어 있지 않다.
(ex. 나무, 도로, 등등 따로 영역이 segment되어 있지만, annotation에서 그 영역이 나무인지 도로인지는 알 수 없음)
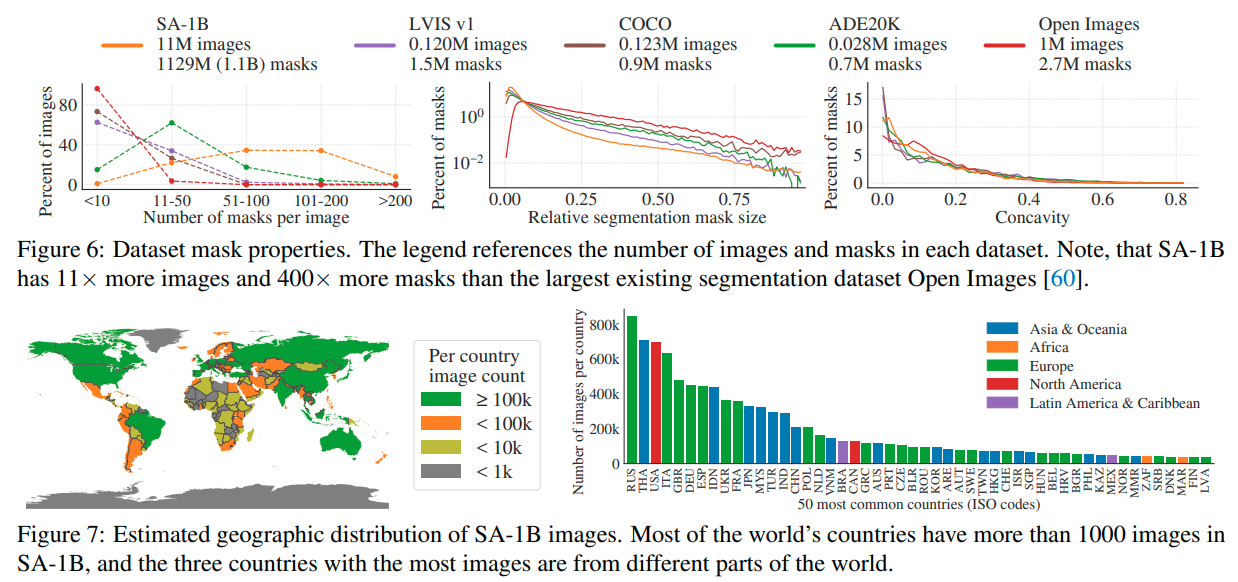
현존하는 다른 데이터셋에 비해서 월등하게 많은 이미지와 마스크를 가지고 있다고 한다.
각 이미지들은 전 세계 다양한 나라에서 골고루 얻었다고 말한다.
그 중 유럽, 아시아, 그리고 오세아니아 국가의 이미지들이 가장 높은 비율을 차지하고 있다고 한다.
6. Segment Anything RAI Analysis
RAI란 Responsible AI로 SA-1B와 SAM이 얼마나 fair하느냐를 분석한 결과를 보이고 있다.
(어떤 것에 치중되어 학습되지는 않았는지 알아보기 위함)
그 중 성별, 연령, 그리고 인종에 따른 성능 차이를 비교하고 있다.

위 표는 SAM이 여자, 남자 모두에 대해서 유사한 성능을 발휘한다는 것을 보여주며,
인식된 성별에 따른 유의미한 성능 차이가 없음을 시사한다.
Table 2의 다른 부분들도 연령대와 피부 톤에 따라 비슷한 결과를 보여준다.
각각의 경우, 이러한 속성에 따라 다른 그룹 간에 SAM의 성능이 비교되며,
결과적으로 이러한 속성에 따른 유의미한 성능 차이가 없음을 나타낸다.
전반적으로 Table 2는 인식된 성별, 연령 그룹 및 인종에 따라 다른 그룹 간의 SAM의 분할 성능이 일관되다는 것을 보여준다.
이는 SAM이 다양한 특성을 가진 사람들의 이미지를 분할하는 데 공정하고 편향이 없는 모델임을 시사한다.
7. Experimental Results: Zero-shot Transfer
5개의 하위 task (edge detection, segment everything, object proposal generation, segment detected objects, segment objects from free-form text 포함) 로 zero-shot transfer를 하여 SAM의 성능을 보여주는 실험 결과 섹션이다.
모든 결과는 아래와 같이 SA-1B와 다른 distribution을 가진 새로운 데이터셋에 대해서 평가했다고 한다.

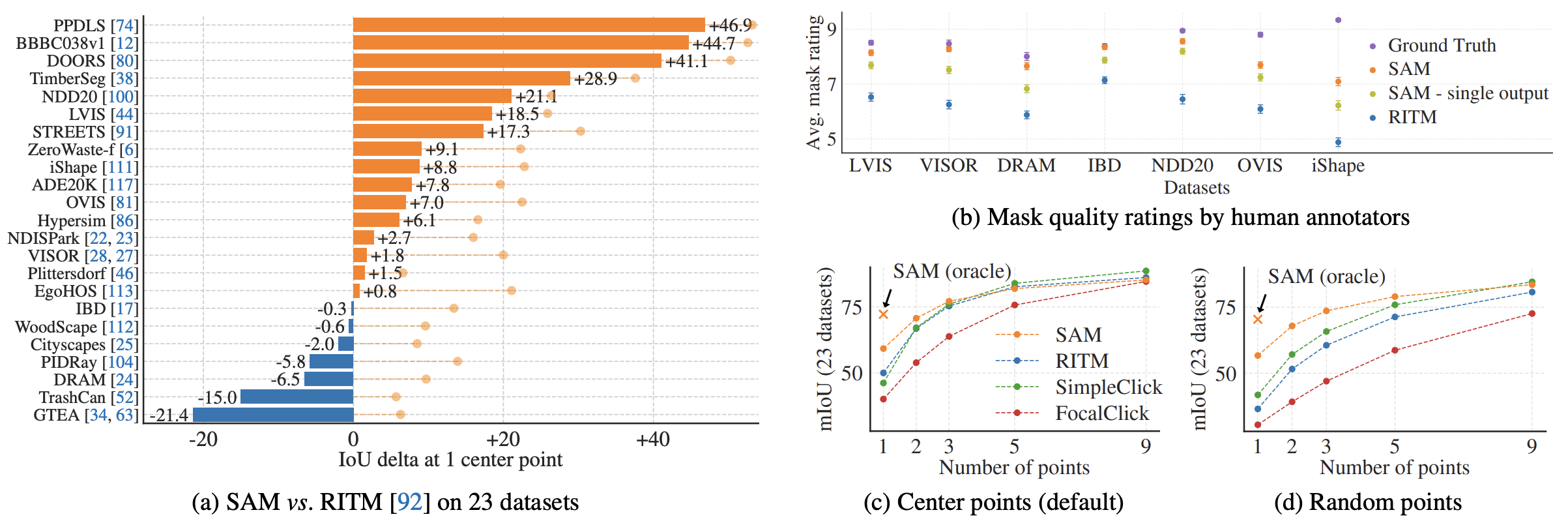
(1) Single Point Valid Mask Evaluation
- Task: foreground에 해당하는 곳의 중점만 prompt로 주어졌을 때 foreground segmentation mask를 추출해 내는 것.
- Result (Compare with RITM model)
- 23개의 데이터셋중 16개에서 RITM보다 높은 성능을 보임
- (b)에서는 사람이 정성적 평가한 결과를 보여주고 있다. 몇몇 데이터셋에서는 정량적 평가에서는 RITM보다 낮았지만, 정성적 평가에서는 더 높은 결과를 보이기도 한다.
- (c), (d)에서는 prompt로 주는 점의 개수를 달리할 때의 결과. 개수가 많아질수록 그 차이가 적어지지만 저므이 개수가 적을 때는 SAM이 월등한 성적을 보임.
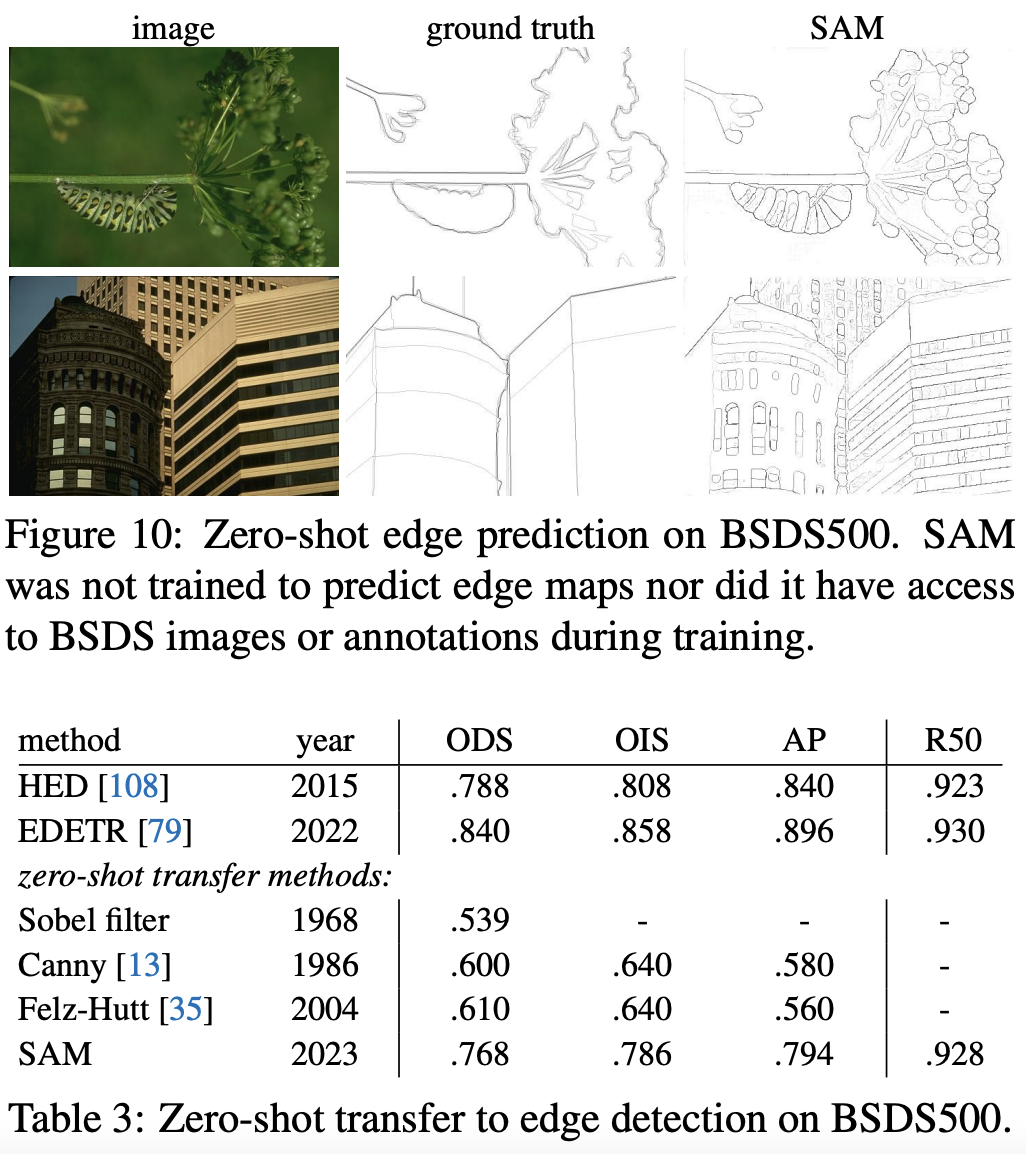
(2) Zero-Shot Edge Detection
- Approach: 전체 이미지에 대해서 segmentation을 진행한 결과에서 Sobel Filter를 써서 edge만 뽑아낼 수 있었음
- Result: Edge Detection에 대해서는 전혀 학습시키지 않았음에도 불구하고 준수한 성능을 보임. SAM보다 좋은 성능을 낸 모델들은 테스트 데이터셋인 BSDS500의 트레이닝 데이터셋으로 학습된 것임을 감안하면, 아주 좋은 성능이라고 말함.
(3) Zero-Shot Object Proposals
- Approach: Object Detection에서 중요한 object proposal을 뽑아내는 성능을 평가하기 위해 output을 mask로 뽑아내는 pipeline대신 box를 뽑아내도록 zero-shot transfer 했다고 한다.
- Result
- ViTDet-H와 비교해 보면, 전반적으로 ViTDet이 더 좋은 성능을 보이긴 함
- 하지만 SAM이 rare한 케이스에서는 더 좋은 성능을 보이기도 하는 등 준수한 성능을 보인다

(4) Zero-Shot Instance Segmentation
- Approach: 간단하게 위에서 얻은 proposal을 box prompt로 가지고 segmenation을 진행한 결과
- Result
- ViTDet-H보다 좋지 않은 box로 segmentation을 했음에도 불구하고 segmentation 결과는 비슷하다.
- 사람이 직접 정성적 평가를 했을 때는 더 좋은 경우도 많았다고 한다.
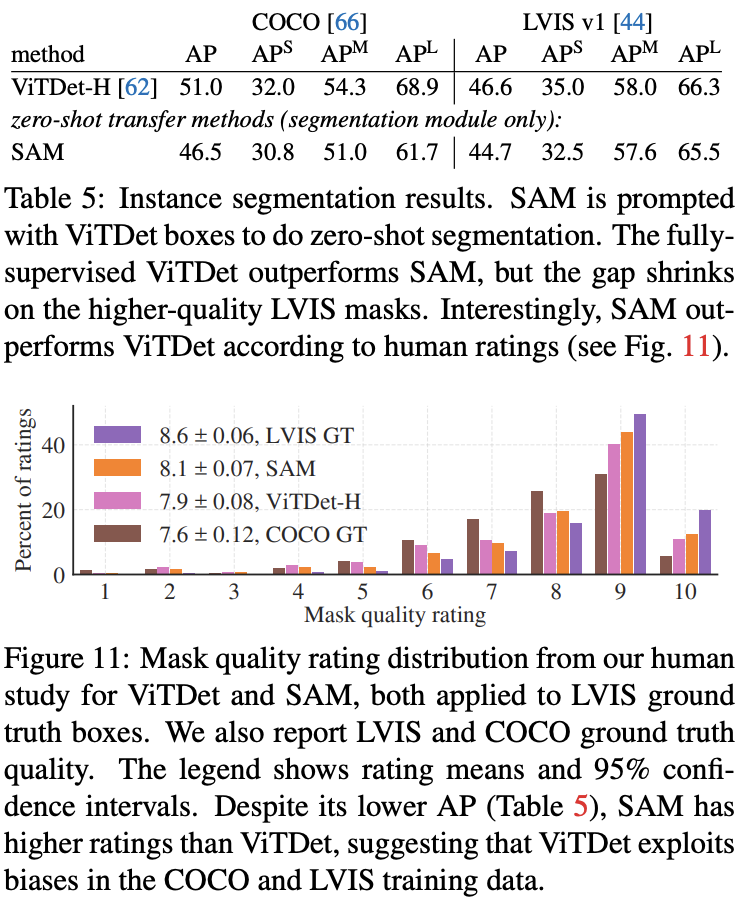
(5) Zero-Shot Text-to-Mask
- Approach: Text prompt를 주기 위해선 새로운 annotation이 필요하므로, 이를 피하기 위해서 CLIP의 이미지 인코더를 사용했다. 학습 시에 이미지 전체에 대해서 뽑아낸 마스크 중 100^2이 넘는 영역에 대해서 CLIP의 이미지 인코더로 뽑아낸 임베딩을 prompt로 주었다고 한다.
- Result
- Inference 시에는 text prompt를 사용하는데, 간단한 'a wheel'같은 것에 대해서는 좋은 성능을 보인다.
- text만 줬을 땐 틀렸던 것들도 point를 같이 주면 잘 해낸다.

SAM 코드 및 데모 간단 리뷰
홈페이지에서 간단하게 돌려볼 수 있지만, 직접 실행해 보고 싶어서 Meta AI가 공개한 코드를 받아서 돌려보았다. (아래 링크 참조)
논문에서는 prompt를 text, mask, bbox, point 이렇게 4가지 종류를 받을 수 있다고 했는데,
데모 및 공개 코드에는 아직 bbox나 point로만 가능하게 나와있다.
prompt를 주는 방법, 주지 않고 전체를 segment 하는 방법 둘 다 시도할 수 있다
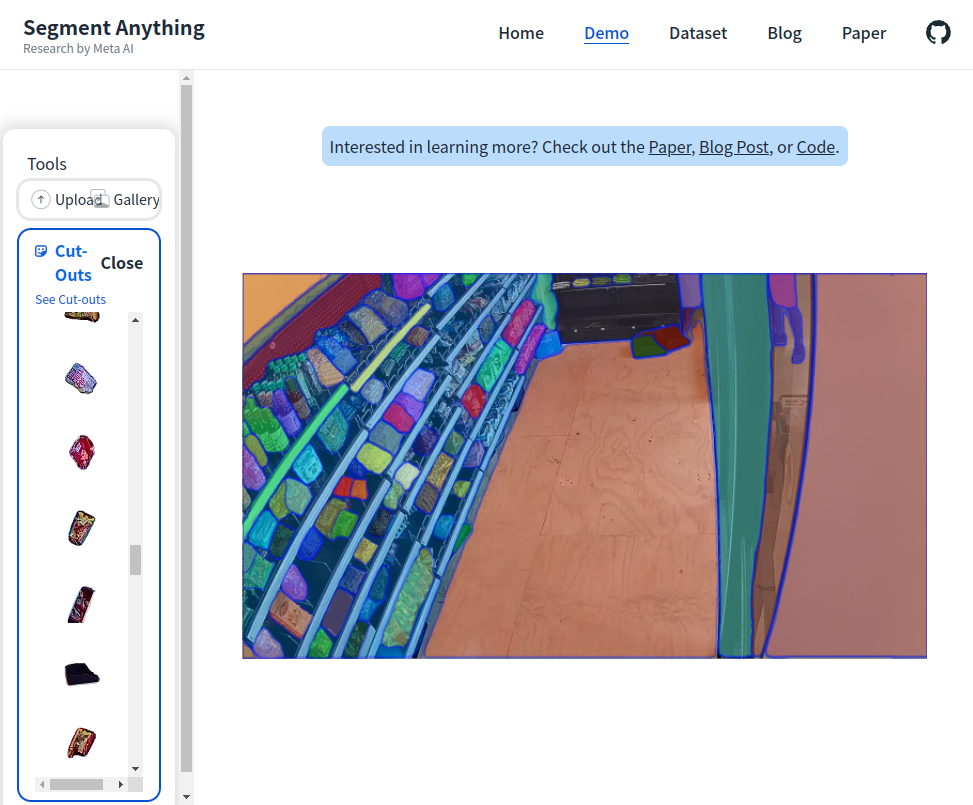
model의 checkpoint weight도 깃헙에 같이 올라와있어 코드로도 실행해볼 수 있다.
아마 text와 mask는 point 혹은 bbox와 다른 prompt encoder 형태를 쓰기 때문에 아직 업데이트가 되지 않은 것이 아닐까 싶다.
(코드 정리 중 혹은 mask와 text의 prompt encoder에 대한 pretrained weight 학습 중일듯?)
개인적으로 text prompt로 실행해보고 싶었으나, pretrained weight 없이 fine-tuning할 엄두가 나지 않아서
공식 깃헙이 업데이트 되기를 기다리는 것이 더 빠르지 않을까 싶다......
SAM 관련 링크들
- 데모 링크: https://segment-anything.com/
- 블로그 링크: https://ai.facebook.com/blog/segment-anything-foundation-model-image-segmentation/
- GitHub 링크: https://github.com/facebookresearch/segment-anything
Segment Anything
Meta AI Computer Vision Research
segment-anything.com
Introducing Segment Anything: Working toward the first foundation model for image segmentation
Working with Inria researchers, we’ve developed a self-supervised image representation method, DINO, which produces remarkable results when trained with Vision Transformers. We are also detailing PAWS, a new method for 10x more efficient training.
ai.facebook.com
GitHub - facebookresearch/segment-anything: The repository provides code for running inference with the SegmentAnything Model (S
The repository provides code for running inference with the SegmentAnything Model (SAM), links for downloading the trained model checkpoints, and example notebooks that show how to use the model. -...
github.com



