
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
Tags
- Computer Vision 논문 리뷰
- VLM
- contrastive learning
- Self-supervised learning
- Multi-modal
- Data-centric
- deep learning 논문 리뷰
- Segment Anything
- Segment Anything 설명
- Prompt Tuning
- 논문 리뷰
- Segment Anything 리뷰
- Prompt란
- iclr 2024
- Meta AI
- 자기지도학습
- active learning
- cvpr 논문 리뷰
- CVPR
- ICLR
- 논문리뷰
- cvpr 2024
- ai 최신 논문
- iclr 논문 리뷰
- deep learning
- Computer Vision
- iclr spotlight
- ssl
- Data-centric AI
- Stable Diffusion
Archives
- Today
- Total
목록VLP 논문 (1)
Study With Inha
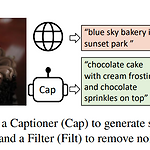 [Paper Review] (BLIP, BLIP-2) Bootstrapping Language-Image Pre-training 설명 및 논문 리뷰
[Paper Review] (BLIP, BLIP-2) Bootstrapping Language-Image Pre-training 설명 및 논문 리뷰
BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation 논문 링크: https://arxiv.org/abs/2201.12086 BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation Vision-Language Pre-training (VLP) has advanced the performance for many vision-language tasks. However, most existing pre-trained models only excel..
Paper Review
2023. 6. 15. 02:42