
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- Multi-modal
- Self-supervised learning
- 논문리뷰
- 논문 리뷰
- iclr spotlight
- Data-centric AI
- Prompt란
- Data-centric
- CVPR
- contrastive learning
- Segment Anything 설명
- ai 최신 논문
- cvpr 논문 리뷰
- ICLR
- Segment Anything 리뷰
- VLM
- active learning
- Computer Vision
- deep learning 논문 리뷰
- Computer Vision 논문 리뷰
- iclr 2024
- Prompt Tuning
- iclr 논문 리뷰
- deep learning
- Meta AI
- ssl
- 자기지도학습
- Segment Anything
- Stable Diffusion
- cvpr 2024
Archives
- Today
- Total
목록nlp (1)
Study With Inha
 [Paper Review] Visual Prompt Tuning, ECCV 2022 논문 리뷰
[Paper Review] Visual Prompt Tuning, ECCV 2022 논문 리뷰
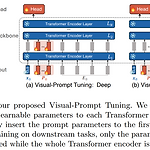
ECCV 2022, Visual Prompt Tuning, M. Jia et al. 논문 링크: https://arxiv.org/pdf/2203.12119.pdf 1. Introduction 최근 GPT 계열 모델과 같이 대규모 데이터와 대규모 모델을 활용한 딥러닝 연구가 많아졌다. 그러한 데이터의 경우 엔비디아나 구글과 같이 엄청난 컴퓨팅 파워를 가지고 있는 대기업이 아닌 일반인들은 Pretrain된 모델을 Fine-tuning하는 것도 어려운 상황에 이르렀다 :( 따라서 본 논문에서는 비전 분야에서 대규모 Transformer 모델을 효율적으로 활용하기 위한 새로운 fine-tuning 방법인 Visual Prompt Tuning (VPT)을 제안한다. 이는 기존의 fine-tuning 방법보다 더 ..
Paper Review
2023. 3. 27. 19:02