
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
Tags
- Prompt란
- Self-supervised learning
- 자기지도학습
- ai 최신 논문
- active learning
- CVPR
- iclr 논문 리뷰
- deep learning 논문 리뷰
- deep learning
- Computer Vision 논문 리뷰
- contrastive learning
- ssl
- cvpr 논문 리뷰
- iclr spotlight
- Data-centric
- ICLR
- 논문 리뷰
- Computer Vision
- Multi-modal
- 논문리뷰
- cvpr 2024
- Prompt Tuning
- VLM
- Meta AI
- Segment Anything 설명
- Segment Anything
- iclr 2024
- Stable Diffusion
- Segment Anything 리뷰
- Data-centric AI
Archives
- Today
- Total
목록zero-shot (1)
Study With Inha
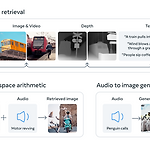 [Paper Review] Meta AI (FAIR)의 새로운 논문, ImageBind: One Embedding Space To Bind Them All 논문 리뷰
[Paper Review] Meta AI (FAIR)의 새로운 논문, ImageBind: One Embedding Space To Bind Them All 논문 리뷰
Meta AI (현 메타 에이아이, 구 페이스북), Facebook Research team (FAIR) IMAGEBIND: One Embedding Space To Bind Them All 논문 링크: https://arxiv.org/pdf/2305.05665.pdf 1. Introduction 최근 Segment Anything Model (SAM) 이라는 것을 발표한 Meta AI에서 또 다른 논문을 발표했다. 2023년 5월 9일 아카이브에 올라온 최신 논문인데, 신선한 아이디어를 제시하고 있어 리뷰할 논문으로 선정했다. 이 논문에서 제시하는 'ImageBind'는 여러가지 모달리티들의 embedding을 하나의 공통 space에 정렬함으로써 긴밀한 관계를 형성하고, 이를 통해 다양한 multi-..
Paper Review
2023. 5. 11. 18:36