| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- Prompt란
- Segment Anything 설명
- cvpr 2024
- Multi-modal
- Self-supervised learning
- contrastive learning
- 논문리뷰
- iclr 2024
- cvpr 논문 리뷰
- Data-centric AI
- 논문 리뷰
- deep learning 논문 리뷰
- CVPR
- ICLR
- 자기지도학습
- Computer Vision
- Prompt Tuning
- active learning
- ssl
- iclr 논문 리뷰
- ai 최신 논문
- Segment Anything 리뷰
- Segment Anything
- Meta AI
- Computer Vision 논문 리뷰
- Data-centric
- iclr spotlight
- VLM
- deep learning
- Stable Diffusion
- Today
- Total
Study With Inha
[Paper Review] Meta AI Segment Anything 2, SAM 2: Segment Anything in Images and Videos 논문 리뷰 및 SAM2 설명 본문
[Paper Review] Meta AI Segment Anything 2, SAM 2: Segment Anything in Images and Videos 논문 리뷰 및 SAM2 설명
강이나 2024. 8. 22. 14:24Meta FAIR
SAM 2: Segment Anything in Images and Videos
Segment Anything Model 2 설명 및 논문 리뷰
Paper: SAM2 Paper Link
Demo: https://sam2.metademolab.com
Code: https://github.com/facebookresearch/segment-anything-2
Website: https://ai.meta.com/sam2
Meta Segment Anything Model 2
Access our research Open innovation To enable the research community to build upon this work, we’re publicly releasing a pretrained Segment Anything 2 model, along with the SA-V dataset, a demo, and code. Download the model Highlights We are providing tr
ai.meta.com
1. Introduction
작년(2023)에 Meta AI에서 Segment Anything Model (SAM) 이라는 논문을 내면서 엄청난 혁신을 불렀다.
자체 Data Engine을 통해 구축한 대용량 데이터셋인 SA(Segment Anything)으로 학습된 SAM은 입력받은 prompt에 대한 높은 성능의 segmentation 결과를 얻을 수 있도록 했다.
기존 SAM에서 업그레이드 된 ver2라고 볼 수 있는 SAM2는 이미지뿐만 아니라 비디오에서도 잘 작동할 수 있는 segmentation model을 구축하는 것을 목표로 했다. ("segment anything in videos")
SAM2 (Segment Anything Model 2)가 가지고 있는 Contribution 및 Novelty는 아래와 같다.
- 대용량 segmentation 비디오 데이터셋인 Segment Anything Video (SA-V)를 구축하기 위해 기존에 비해 8.4배 더 빠른 속도를 가지고 있는 Data Engine을 만듦. 이는 35.5M개의 mask와 50.9K개의 video로 이루어져 있으며, 이는 기존 비디오 데이터셋보다 53배 더 많은 수치임. 이를 통해 object의 segmentation 뿐만 아니라 parts나 subparts에 대한 segmentation 성능도 향상시킴.
- SAM2는 기존 SAM 모델에 Meomory Attention을 도입하여 높은 성능을 보였고, 이와 같은 결과는 video segmentation 분야의 step-changer 역할을 함. 기존 모델들에 비해 3배 더 적은 interaction을 함에도 불구하고 더 높은 segmentation accuracy를 보임.
- 기존 SAM에 비해서 image segmentation 성능도 향상시켰을 뿐만 아니라, 속도는 기존보다 6배 더 빨라졌음.
- 최종적으로 SAM2의 경우에는 다양한 zero-shot benchmark들에서 video 및 image에 대한 평가를 진행했을 때, 모두 우수한 성능을 보임

2. Related Work
Image Segmentation
SAM의 Image Segmentation 관련 Related Works들은 이전 포스팅 글을 참고하면 좋을 것 같다.
[Paper Review] Segment Anything Model (SAM) 자세한 논문 리뷰, Meta의 Segment Anything 설명
[Paper Review] Segment Anything Model (SAM) 자세한 논문 리뷰, Meta의 Segment Anything 설명
Meta AI, Segment Anything, Alexander Kirillov et al.논문 링크: https://ai.facebook.com/research/publications/segment-anything/ 1. Introduction2023년 4월 5일에 Meta AI가 공개한 Segment Anything이라는 논문은 모든 분야에서 광범위하
2na-97.tistory.com
[Paper Review] 고해상도 결과를 얻을 수 있는 Segment Anything 후속 연구, HQ-SAM 논문 리뷰
[Paper Review] 고해상도 결과를 얻을 수 있는 Segment Anything 후속 연구, HQ-SAM 논문 리뷰
Segment Anything in High Quality, ETH Zurich 논문링크: https://arxiv.org/abs/2306.01567 Segment Anything in High QualityThe recent Segment Anything Model (SAM) represents a big leap in scaling up segmentation models, allowing for powerful zero-shot cap
2na-97.tistory.com
Interactive Video Object Segmentation (iVOS)
Interactive Video Object Segmentation은 scribbles, clicks, 혹은 bounding box와 같은 user guidance를 토대로 비디오에서 object segmentation을 수행하는 태스크를 말한다.
처음에는 graph-based optimization을 통해서 segmenation annotation process를 진행하는 연구들이 많았고,
이후에는 user input을 single frame의 mask representation으로 변환시킨 뒤 이후 프레임에 대해 이를 propagation하는 접근들이 많이 있었다.
DAVIS의 interactive benchmark의 경우 아래와 같은 scribble input을 통해 object를 segmentation하는 것을 목표로 한다.
DAVIS의 interactive benchmark에서 영감을 얻어, SAM2에서도 promptable video segmentaiton 평가를 위해 interactive evaluation setting을 차용했다고 한다.

Click-based input을 받는 비디오 데이터셋은 조금 더 모으기가 쉬웠는데, 다수의 SAM 후속 연구들도 이에 포함되어 있다.
하지만 이와 같은 approach들은 모든 object에 대해서 tracker가 잘 작동하는 것이 아니며, SAM이 video를 frame 단위로 자른 image에서 잘 작동하지 않는다는 문제가 있었다.
또한 model이 잘못 tracking을 할 경우 이를 바로 잡는 매커니즘이 제대로 있지 않아 생기는 문제들이 있었다.
Semi-supervised Video Object Segmentation (VOS)
Video Object Segmentation에서 "Semi-supervised Setting"은 첫 번째 frame에 대해서만 object의 mask가 input으로 함께 주어지는 것을 말한다.
이러한 대스크는 video editing, robotics, 그리고 automatic background removal 등에서 활용될 수 있어 높은 각광을 받았다.
초기 NN-based 방법론들은 비디오의 첫 프레임이나 전체 프레임에 대해서 online fine-tuning을 진행하여 모델이 target object에 대해서 학습할 수 있도록 했다.
이후 offline-trained model을 통해서 더 빠른 inference가 가능해졌는데, 여기에는 첫 번째 프레임만 사용하거나 이전 프레임들을 통합한 condition을 활용하는 방법이 있다.
(If a model is "conditioned" on the first frame of a video, it means that the model is provided with the first frame where the object of interest is clearly identified (e.g., with a mask or bounding box). The model then uses this information as a reference to identify and segment the object in the subsequent frames.)
이러한 multi-conditioning은 RNN과 cross-attention을 활용하여 전체 프레임으로 확장될 수 있었다.
(If a model uses "multi-conditioning," it might use information from both the first frame and the previous frame (or multiple previous frames) to predict the object’s segmentation in the current frame. This approach can capture temporal dynamics, such as how the object moves or changes over time, leading to more accurate and robust segmentation.)
최근 연구들은 현재 프레임을 예측하기 위해서 이전 모든 프레임에 대한 예측들을 통합하여 사용할 수 있도록 vision transformer를 사용하고 있으며, 이를 통해 간단한 구조의 모델을 활용할 수 있었지만 inference cost가 비싸다는 단점이 존재한다.
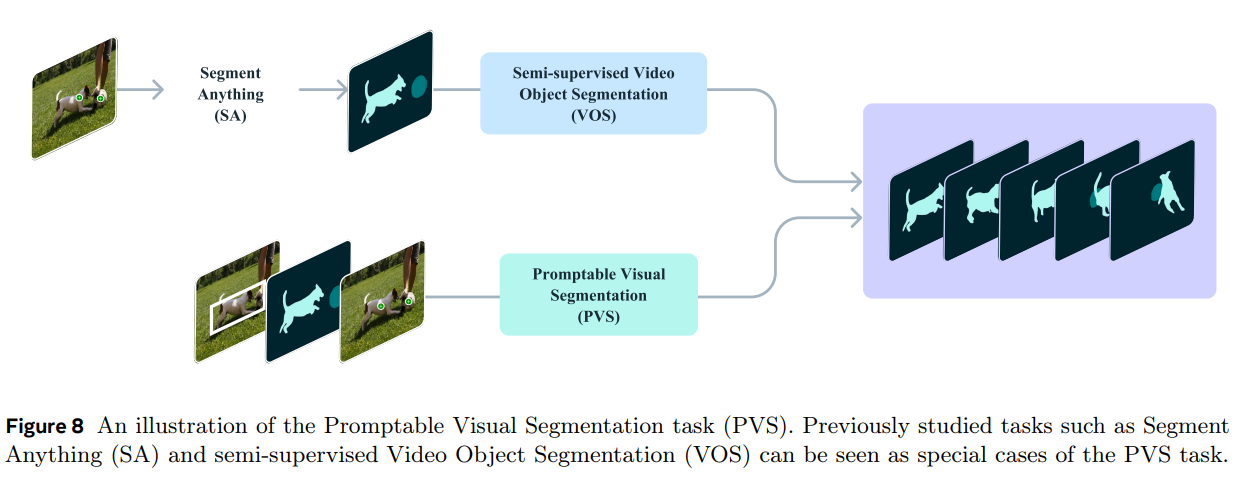
Semi-supervised VOS는 SAM2 또한 첫 프레임에 대한 mask prompt만을 제공한다는 점에서 본 논문에서 target하는 Promptable Visual Segmentation (PVS) 태스크의 special case라고 볼 수 있다.
하지만 높은 성능을 위해 첫 프레임에서 high-quality의 object mask를 직접 annotating할 경우 높은 노동력과 많은 시간을 요구한다.
Video Segmentation Datasets
DAVIS와 같은 초기 VOS 데이터셋들은 high-qaulity의 annotation을 포함하고 있지만, 그 수가 deep-learning 모델들을 학습할만큼 충분하지는 않았다.
처음으로 large-scale VOS 데이터셋을 제안한 것은 YouTube-VOS로 94개의 object category들과 4000개가 넘는 비디오를 포함하고 있다.
모델들이 어느정도의 성능을 보이기 시작하자 occlusion, long video, extreme transformation, object diversity, 그리고 scene diversity와 같은 hard case에 집중한 논문들이 나왔다.
본 논문에서 현존하는 데이터셋에서는 "segment anything in videos"를 할 만큼의 충분한 정보가 존재하는 데이터셋이 없었다고 한다.
현존하는 데이터셋은 보통 object 전체를 하나로 annotate하여 part에 대한 정보가 부족할 뿐만 아니라,
사람, 자동차, 그리고 동물들과 같은 특정 클래스에만 집중되어 있기 때문이다.
이에 SA-V의 경우 whole object 뿐만 아니라 object의 part까지 포함하고 있기 때문에 기존보다 10배 이상의 mask annotation을 포함할 수 있게 되었다.
3. Task: promptable visual segmentation
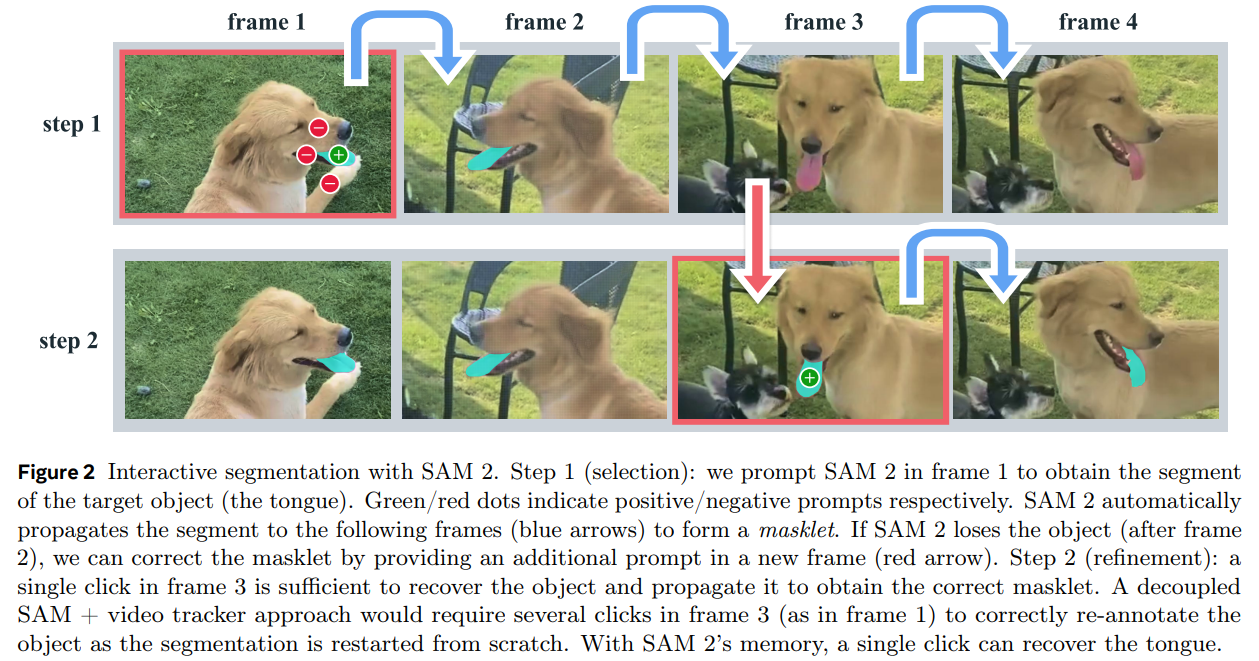
Promptable Visual Segmentation (PVS) 태스크는 비디오에서 어느 프레임에 대한 prompt를 제공하더라도 좋은 segmentation 결과를 보여주는 것을 목표로 한다.
여기서 prompt는 positive 및 negative clicks (points), bounding boxes, masks (either to define an object to segment or to refine a model-predicted one)들이 될 수 있다.
우선 PVS에서 특정 frame에 대한 prompt를 입력 받았을 때 즉시 해당 frame에서 object를 제대로 segmentation할 수 있어야 한다.
처음 한 개 혹은 그 이상의 initial prompt를 같은 frame 혹은 다른 frame에 대해서 입력 받았을때, 모델은 prompt들을 propagate하여 전체 비디오에서 해당 object에 대한 masklet을 출력해야 한다.
이 때 추가적인 prompt는 비디오의 어느 임의의 frame에 주어질 수 있으며, 이를 통해 segmentation 결과를 refine하는 것도 가능하다. (Figure 2, Figure 8 참고)
SAM2에서는 data collection tool를 활용하여 PVS task를 위한 SA-V dataset을 구축했다.
또한 모델은 online과 offline setting 모두에서 semi-supervised VOS setting과 같이 첫 번째 frame에서만 annotation이 주어졌다는 가정 하에 video segmentation 평가를 진행했으며, image segmentation 또한 SA benchmark를 통해서 평가가 이루어졌다고 한다.
4. Method
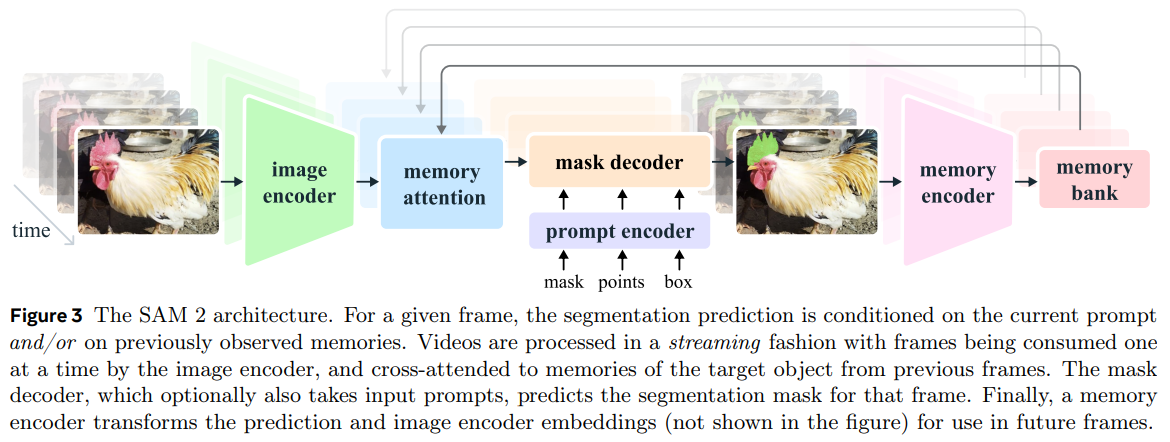
SAM2는 video 및 image에 모두 적용될 수 있는 SAM의 generalized version이라 할 수 있다.
Figure 3에서 볼 수 있듯 SAM2는 individual frame들에 대한 point, box, 그리고 mask 형태의 prompt를 입력으로 받게 된다.
이미지 입력에 대해서는 SAM과 비슷한 형태로 작동하게 된다.
light-weight mask decoder는 현재 frame에 대한 embedding과 prompt를 입력으로 받고, 해당 frame에 대한 segmentation 결과를 출력하게 된다.
Prompt는 mask를 정제(refine)하기 위해서 반복적으로(iteratively) 추가될 수 있다.
SAM의 디코더가 frame embedding을 직접적으로 사용한 것과 다르게,
SAM2의 디코더는 과거 예측값들의 memory들과 prompted frames에 condition된 후 사용된다.
현재 frame보다 미래에 있는 prompted frame들의 정보를 사용하는 것 또한 가능하다.
프레임의 메모리(Memories of Frames)는 현재 예측 결과에 기반한 Memory Encoder를 통해 생성되며,
이는 이후 연속된 프레임들을 예측하는 데에 사용하기 위해 Memory Bank에 저장된다.
Memory Attention 연산은 Image Encoder로부터 얻은 per-frame embedding과 memory bank로부터 얻은 conditions을 입력으로 받아 새로운 embedding을 출력하게 되고, 이것이 Mask Decoder로 입력된다.
- Memory Encoder: 각 Frame들을 입력으로 받아 Image Embedding 생성 (SAM에서는 이것이 바로 Mask Decoder의 Input으로 활용됐었음).
- Real-time long video에 대한 예측을 한다고 가정했을 때, 이미지 인코더는 전체 interaction 동안 한 번만 돌게 되고, 각 프레임에 대한 unconditioned tokens (feature embeddings)를 제공하게 됨
- Hiera로 pretrain된 MAE의 이미지 인코더를 사용하였고, 이는 hierarchical한 구조이기 때문에 디코더에서 multiscale feature를 활용할 수 있게 했다.
- Memory Encoder: 현재 frame에 대한 예측 결과를 입력으로 받아 Memories of Frames에 대한 Embedding 출력
- convolutional module을 통해 output mask를 downsampling 시킨 후 image encoder로부터 얻은 unconditioned frame embedding과 element-wise 합산을 하여 memory를 생성함.
- Memory Bank: Memory Encoder로부터 얻은 Embedding들을 저장하는 공간. 추후 Frame들에 대해 예측할 때 활용됨.
- Memory Bank는 비디오에서 target object에 대한 과거 prediction들에 대한 정보를 담고 있음
- 이는 $N$개의 최근 frame들에 대한 memory들과 $M$개의 prompted frame들에 대한 정보가 FIFO queue에 저장되어 관리됨. 예를 들어 VOS에서 initial mask만 prompt로 주어진 경우, memory bank를 첫 번째 frame의 memory와 $N$개의 unprompted recent frame들에 대한 정보가 spatial feature map 형태로 저장됨.
- 이와 더불어 list of object pointer들도 함께 저장되는데, 이는 각 프레임에 대한 mask decoder의 output token을 기반으로 segment되어야 할 object에 대한 high-level semantic information을 담고 있는 lightweight vector를 뜻한다.
- $N$ recent frame들에 대한 memory들에 temporal position information을 embed함. 이는 short-term object motion에 대해서 모델이 이해할 수 있도록 만들어줌. 하지만 prompted frame에 대해서는 진행하지 않았는데, 이는 prompted frame들은 sparse하며 training setting과 실제 inference setting간의 temporal range 차이가 클 수 있어 generalizatio이 어렵기 때문임.
- Memory Attention: Image Encoder의 Image Embedding + Memory Bank로부터 얻은 Conditions (과거 예측값들에 대한 정보)를 기반으로 연산 수행 후 Mask Decoder에 입력하게 됨.
- $L$개의 transformer block들을 쌓았으며, 첫 번째 블록은 current frame의 image encoding 결과를 입력으로 받게 됨
- 각 블록은 self-attention + cross-attention (memories of prompted/unprompted frames and object pointers stored in a memory bank) + MLP 연산을 수행함
- self-attention과 cross-attention 연산 시에는 efficient attention kernel을 위해서 vanilla attention을 활용함
- Prompt Encoder and Mask Decoder
- Prompt Encoder의 경우 SAM과 동일하게 positive/negative click, bounding box, 혹은 mask를 prompt로 받을 수 있음
- Sparse Prompt들은 positional encoding을 통해 learned embedding과 합산되고, mask와 같은 Dense Prompt는 convolution 연산을 통해 embedding을 추출한 뒤 frame embedding과 합산됨
- Decoder 또한 기본적으로 SAM의 구조를 따름. 'two-way' transformer block을 쌓았으며 이는 prompt와 frame embedding을 입력받아 업데이트 됨.
- SAM에서와 같이 single click과 같이 ambiguous한 prompt의 경우 multiple mask들을 예측하게 됨. 이는 모델이 valid한 mask를 출력했는지를 확인하는 데에 중요한 역할을 함. Video에서는 ambiguity가 비디오 전체 프레임들에 걸처 존재할 수 있으므로, 모델은 각 프레임마다 multiple mask들을 예측하게 됨.
- follow-up prompt들에서 ambiguity를 해소시켜 주지 못할 경우, 현재 프레임에서 가장 높은 IoU를 가진 마스크가 최종적으로 선택되어 propagate됨
- SAM에서는 positive prompt에 대한 valid object가 무조건 존재했던 것에 비해, PVS task에서는 occlusion 등으로 인해서 몇몇 프레임에서는 valid object가 존재하지 않을 수도 있음. 이러한 경우를 대비해 현재 프레임에서 target object의 존재 여부를 판단할 수 있는 additional head가 추가됨.
- SAM과의 또 다른 점은, mask decoding 시에 high-resolution에 대한 정보를 활용하기 위해서 hierarchical image encoder에 skip connection을 추가하여 decoder에 활용함.

학습은 image와 video 데이터에 대해서 jointly training됨.
이전과 비슷하게, interactive prompting에 대해서 simulate하는 과정을 거치게 됨.
- sequences of 8 frames를 sampling 함
- 그 중 랜덤으로 prompt를 적용시킬 2 frames를 고름
- 해당 프레임들에 대해서 확률적으로 corrective clicks를 부여함. (GT masklet과 학습 시에 얻은 model prediction들을 활용함)
- 이 때 training task는 sequentially (and "interactively") GT masklet을 예측하는 것임.
- Initial prompt의 경우 mask의 경우 GT mask with probability 0.5가 되고, positive click의 경우 GT mask with probability 0.25로 샘플링한 점들이 되며, bounding box의 경우 0.25의 확률로 얻은 box input이 됨.
5. Data
Video에서도 잘 작동하는 모델을 위해서 크고 다양한 video segmentaiton dataset을 수집하는 Data Engine을 구축했다.
Human Annotator들과의 loop setup을 통해서 whole object 뿐만 아니라 object의 part에 대한 정보도 담고 있는 interactive model을 개발했다.
Data Engine은 총 3개의 phase들로 이루어져 있으며, 각 phase는 model이 annotator들에게 얼마나 보조(assistance)를 제공하느냐에 따라 나누어진다.
5.1. Data Engine
Phase 1: SAM per Frame
- Human Annotator들에게 image-based interactive SAM의 결과가 보조로 주어지는 initial phase.
- Annotator들은 6 FPS 비디오에서 target object에 대한 SAM의 output mask에 대해 brush나 eraser 툴과 같은 pixel-precise editing을 수행하게 된다.
- 이 단계에서는 모든 프레임마다 완전 처음부터 mask annotation을 만드는 것이므로 프레임당 평균 37.8초라는 오랜 시간이 걸리는 과정이었음.
- 하지만 이를 통해서 매 프레임마다 high-quality spatial annotation을 얻을 수 있었고, 그 결과 1.4K개의 비디오에 대해서 16K개의 masklet을 얻게 됨.
- SA-V의 val과 test 데이터들은 모델의 biase들이 반영되는 것을 방지하기 위해서 Phase 1의 방법으로 제작된 GT들임
Phase 2: SAM + SAM 2 Mask
- SAM과 더불어 SAM 2가 함께 활용되는 loop임. 이 때 SAM2는 mask prompt만 입력받게 됨. (이 것을 SAM2 Mask라 지칭하며, SAM2 Mask의 initial weight는 Phase 1의 데이터와 Public 데이터셋으로 학습된 것임)
- Phase 1에서와 같이 SAM 및 다른 tool들을 사용하여 첫 번째 frame에 대한 spatial mask를 생성함 -> 이후 다른 frame들에 대한 full spatio-temporal mask를 얻기 위해 SAM2 Mask에 annotated mask를 다른 frame으로 temporal propagate 함.
- 이 때 연속된 어느 frame이라도 생성된 masklet이 정확하지 않을 경우 eraser/brush/SAM/re-propagate SAM2 Mask again 등을 masklet이 정확해질 때까지 반복함.
- re-annotating을 하는 과정에서 SAM2는 retrain되고 update됨
- Phase 2에서는 63.5K개의 masklet을 수집함. 라벨링을 하는 데에 프레임당 7.4초가 걸렸고, 이는 Phase 1에 비해 5.1배 정도 속도가 상승한 수치임
- Phase 2에서 annotation 시간을 개선했지만, 각 중간 프레임에서 마스크를 처음부터 다시 annotation해야 하며 이전 프레임에서의 메모리를 사용하지 않는다는 문제가 존재함.
- 이러한 문제를 해결하기 위해 fully-featured SAM 2를 개발했는데, 이는 "interactive image segmentation"과 "mask propagation"를 하나의 통합된 모델에서 수행함. 즉 SAM 2는 중간 프레임에서도 이전 프레임의 정보를 활용하여 마스크를 자동으로 전파할 수 있어, annotation 과정을 더욱 효율적으로 만듦.
Phase 3: SAM 2
- 마지막 Phase에서는 fully-featured SAM 2를 활용하게 되며, 이는 points나 masks와 같은 다양한 prompt를 입력받을 수 있게 됨.
- SAM 2는 시간 흐름에 따른 object의 정보를 활용하여 마스크를 예측할 수 있다는 장점을 가지고 있음 (SAM 2 benefits from memories of objects across the temporal dimension to generate mask predictions.)
- 이는 Annotator들이 중간 프레임에 대한 mask 결과를 수정하기 위해서는 occasional refinement click만 수행하면 된다는 것을 뜻하며, spatial SAM이 처음부터 mask annotating을 수행해야 했던 것과는 대비되는 과정임.
- Phase 3에서도 collected annotations를 통해서 SAM2를 5번 re-train하고 update하는 과정을 거침
- Phase 3에서는 197.0K개의 masklet을 수집했고, 프레임당 annotation에 걸리는 시간은 4.5초로 줄었으며 이는 Phase 1에 비해서 8.4배 정도 빠른 수치임.
Quality Verification
Annotator들이 annotated masklet들에 대한 만족도 교차 검증을 진행했다.
A separate set of annotators are tasked with verifying the quality of each annotated masklet as “satisfactory” (correctly and consistently tracking the target object across all frames) or “unsatisfactory” (target object is well defined with a clear boundary but the masklet is not correct or consistent).
만족도 점수가 낮을 경우에는 다시 annotation pipeline을 통과하여 refinement될 수 있도록 했다.
만약 잘 정의되지 않은 objects(not well defined objects)에 대해서는 전체가 reject되었다.
Auto Masklet Generation
다양한 annoation은 'anything capability'를 달성하기 위해서 중요한 요소이다.
Human annotator들은 보통 눈에 띄는 물체(salent object)에 집중하게 되므로, automatically generate된 masklet annotation에 augmentation을 적용했다.
이는 annotation의 coverage를 높이고, 모델의 failure case들을 구분하는 데에 도움이 되었다.
auto masklet을 생성하기 위해서, SAM2의 input으로 first frame에 대해 regular grid point로 prompt를 준 후 candidate masklets를 생성했다.
이 candidate masklet들은 masklet verification step을 거쳐 filtering 된다.
Automatic Masklet들 중 "satisfactory" 판정을 받은 것들은 SA-V dataset에 포함된다.
반면 이들 중 "unsatisfactory" 판정을 받은 경우(i.e. model failure cases)에는 annotator들에게 SAM2로 refine이 될 수 있도록 Phase 3에 보내지게 된다.
이러한 automatic masklet들은 large salient central object들뿐만 아니라 다양한 사이즈와 위치에 있는 object들에 대해서도 masklet을 생성할 수 있게 만들었다.
Analysis
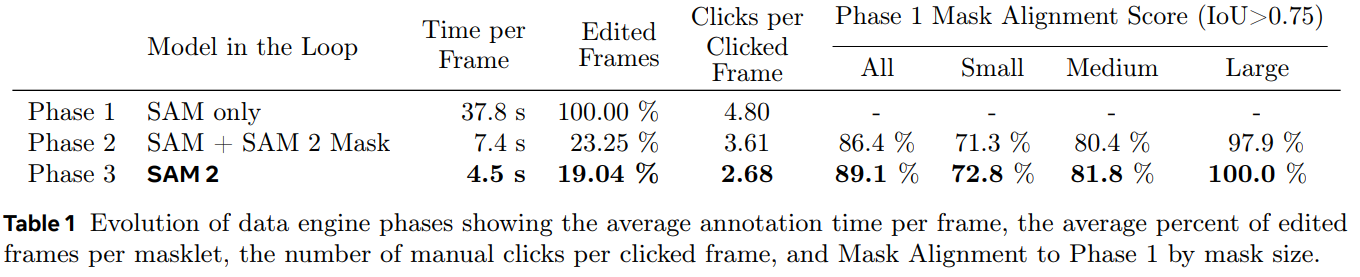
위 Table 1에서 볼 수 있듯 Quality Evaluation을 위해서 Phase 1 Mask Alignment를 정의했는데, 이는 Phase 1의 마스크 중 IoU가 0.75가 넘는 것들의 비율을 나타낸 것이다.
Phase 1은 pixel-precise한 high-quality manual annotation을 얻을 수 있는 단계이므로, 해당 단계에서 나온 결과와 비교하면 얼마나 정교한 결과인지 확인할 수 있기 때문이다.
그 결과 Phase 3에서 SAM2만 사용했을 때, Phase 1에 비해 8.4배 빠른 속도로 annotate할 수 있을 뿐만 아니라, lowest edited frame percentage and clicks per frame을 가지면서도 높은 정확도를 나타내고 있음을 확인할 수 있다.
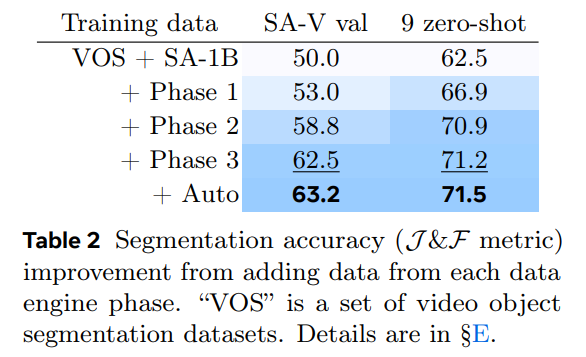
위 Table 2에서 볼 수 있듯 각 phase가 끝난 후 가능한 dataset들로 학습시킨 SAM2 모델의 결과를 비교해 보면 additional data의 중요성을 파악할 수 있다.
첫 프레임에 3-clicks만 prompt로 주어진 결과를 보면, phase가 거듭될수록 in-domain인 SA-V val set이나 zero-shot benchmark에서 모두 성능이 오르고 있음을 볼 수 있다.

5.2. SA-V Dataset

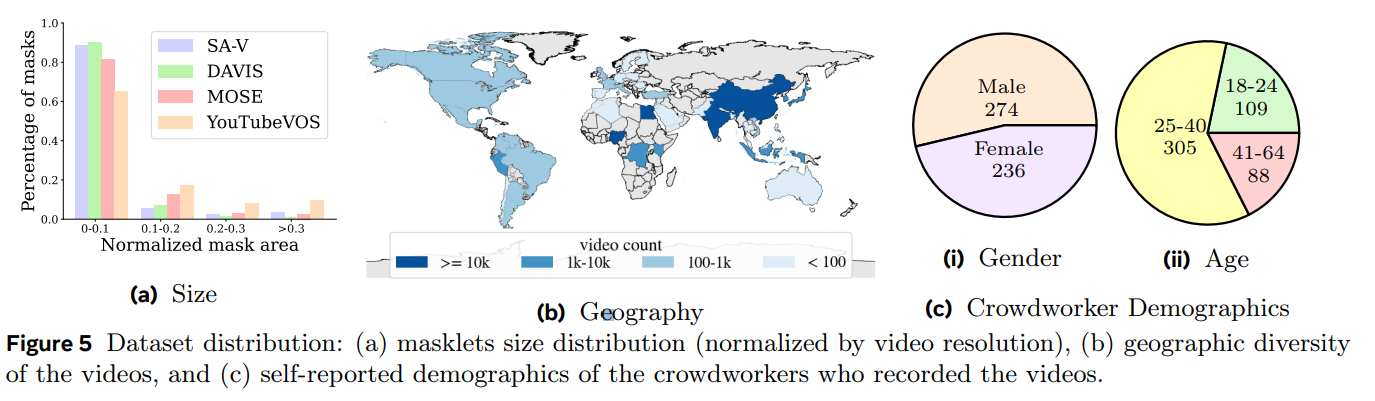
- crowdworkers로부터 얻은 50.9K개의 비디오에서 얻은 642.6K개의 masklets (manual: 190.9K + automatic: 451.7K)으로 이루어져 있음
- Videos comprise 54% indoor and 46% outdoor scenes with an average duration of 14 seconds
- Videos feature “in-the-wild” diverse environments, and cover various everyday scenarios. Videos span 47 countries and were captured by diverse participants (self-reported demographics).
- 이는 현존하는 VOS 데이터셋 대비 53배 더 많은 수치임.
- SA-V 데이터셋은 비디오 저자와 그들의 지리적 위치를 기반으로 나누어, 비슷한 객체의 겹침을 최소화하여 training, validation, 그리고 test dataset으로 나눔
- 빠르게 움직이는 객체, 복잡한 occlusion, 그리고 사라졌다 다시 나타나는 패턴과 같은 도전적인 시나리오에 중점을 두어 Validation 및 Test Set 비디오를 선택함.
- 이는 데이터셋의 다양성과 난이도를 보장하여 모델 성능을 강력하게 평가할 수 있도록 하기 위함.
- There are 293 masklets and 155 videos in the SA-V val split, and 278 masklets and 150 videos in the SA-V test split.
- 내부 라이선스 비디오 데이터를 활용하여, Phase 2와 Phase 3를 거친 62.9K 비디오와 69.6K masklets으로 구성된 내부 데이터셋을 training datset으로, Phase 1을 거친 96K개의 비디오와 189K개의 masklets을 test dataset으로 사용함

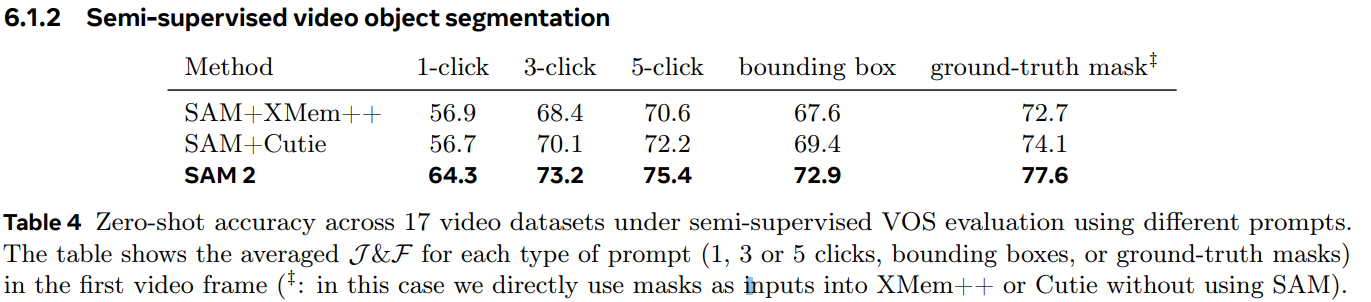
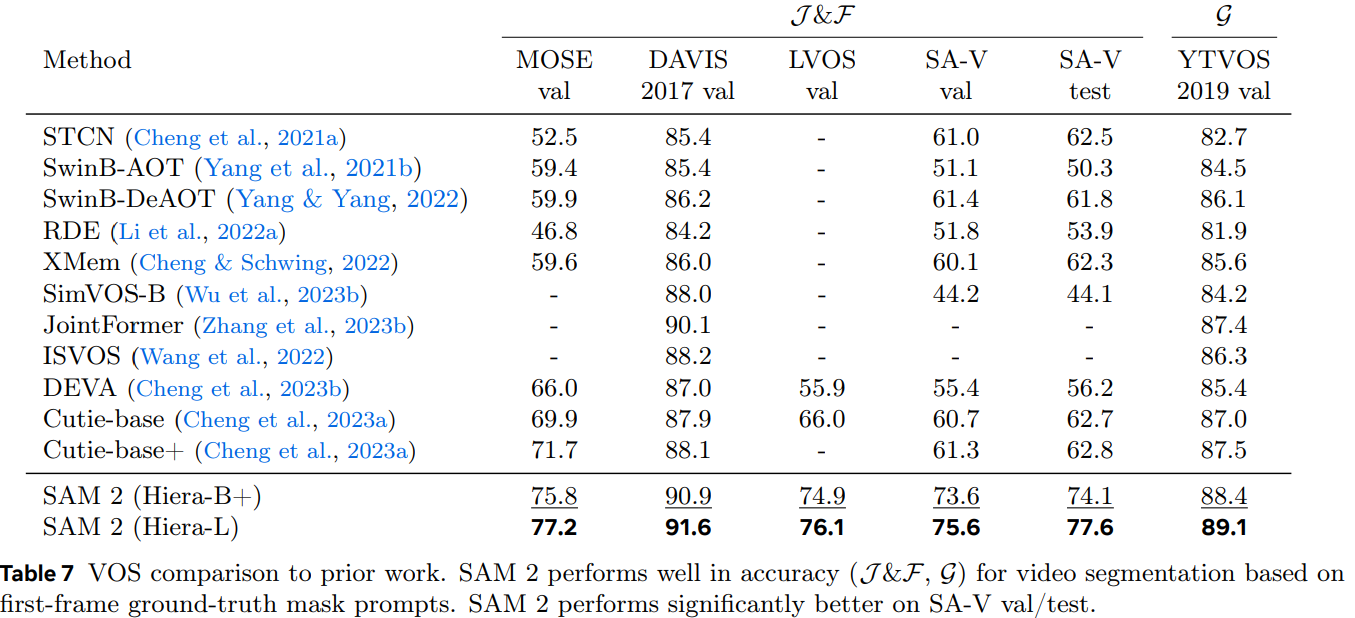
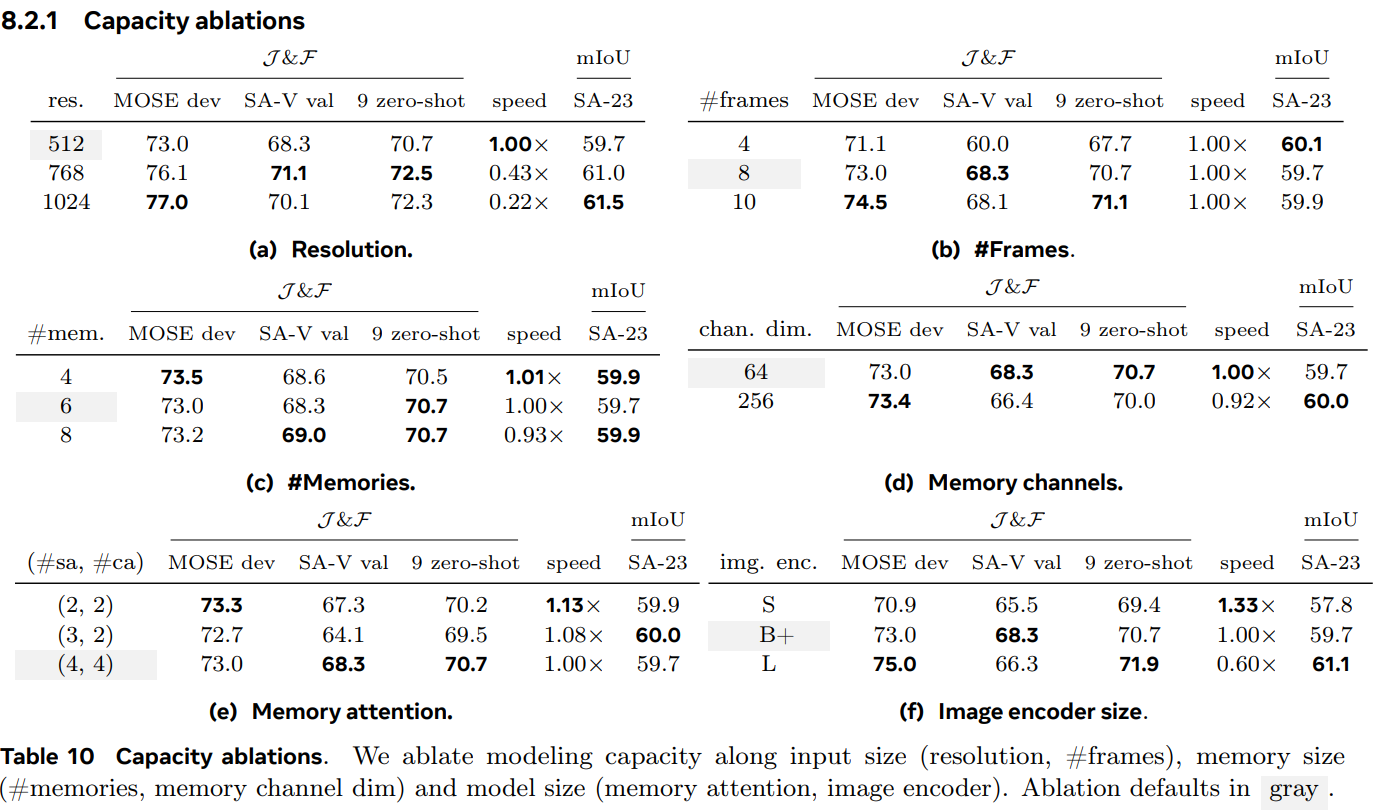
6. Zero-shot Experiments