| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Data-centric
- Computer Vision 논문 리뷰
- 자기지도학습
- VLM
- active learning
- Segment Anything 리뷰
- Stable Diffusion
- deep learning 논문 리뷰
- cvpr 2024
- ai 최신 논문
- iclr 논문 리뷰
- Self-supervised learning
- Segment Anything
- Multi-modal
- CVPR
- ssl
- deep learning
- contrastive learning
- iclr 2024
- cvpr 논문 리뷰
- Segment Anything 설명
- Prompt란
- 논문 리뷰
- 논문리뷰
- iclr spotlight
- Meta AI
- Computer Vision
- ICLR
- Data-centric AI
- Prompt Tuning
- Today
- Total
Study With Inha
[Paper Review] AAAI 2024, Entropic Open-set Active Learning 논문 리뷰 및 설명 본문
[Paper Review] AAAI 2024, Entropic Open-set Active Learning 논문 리뷰 및 설명
강이나 2024. 10. 1. 16:19AAAI 2024 accepted,
Entropic Open-set Active Learning
Paper Link: https://arxiv.org/abs/2312.14126
GitHub: https://github.com/bardisafa/EOAL
GitHub - bardisafa/EOAL: [AAAI 2024] An Implementation of Entropic Open-set Active Learning
[AAAI 2024] An Implementation of Entropic Open-set Active Learning - bardisafa/EOAL
github.com
Introduction
Active Learning (AL)은 레이블이 없는 dataset에서 가장 유익한 sample을 선별한 뒤, 해당 sample들만을 선택적으로 레이블링을 하여 효율적으로 딥러닝 모델의 성능을 향상시키는 접근법이다.
따라서 모든 데이터셋에 대해서 레이블링을 적용하는 것 보다, 데이터셋 내에서 유익한 sample을 먼저 선별하여 labeling 및 storage에 대한 cost를 줄이는 것을 목표로 한다. (자세한 내용은 아래 링크 참고)
[Paper Review] Core-set: Active Learning for Convolutional Neural Networks 리뷰
[Paper Review] Core-set: Active Learning for Convolutional Neural Networks 리뷰
Core-set: Active Learning for Convolutional Neural Networks 논문 링크: https://arxiv.org/abs/1708.00489 Active Learning for Convolutional Neural Networks: A Core-Set Approach Convolutional neural networks (CNNs) have been successfully applied to many r
2na-97.tistory.com
기존의 AL 방법들은 closed-set 환경(training 시에 포함된 class에 대해서만 inference하는 환경)에서 우수한 성능을 보여 왔는데, 이 경우 레이블이 없는 데이터는 오직 known class만 포함한다.
즉 모든 class에 대해서 최소한 하나 이상의 labeled sample이 필요하다는 것을 뜻한다.
하지만 실제 산업에서는 레이블이 없는 데이터에 unknown class가 포함될 가능성이 높아, closed-set AL 방법의 성능이 크게 저하될 수 있다.
이 논문은 학습 과정에서 known class와 unknown class sample을 효과적으로 선택하기 위해 고안된 새로운 framework인 Entropic Open-set Active Learning (EOAL)을 소개한다.
기존의 open-set AL 방법들은 unknown class에 대한 정보는 제대로 활용하지 못하고, known sample에 대한 정보에만 치중되어 학습되는 경향이 있었다.
하지만 EOAL의 경우 레이블이 있는 데이터에 대한 closed-set entropy(Sc)와 unkown sample에 대한 정보를 활용하는 distance-based entropy(Sd)를 함께 사용하여 알려진 샘플과 알 수 없는 샘플을 효과적으로 구분하게 되었다.

EOAL Query Strategy는 두 엔트로피 점수를 결합하여 (S(x)=Sc(x)−Sd(x)),
known과 unknown 카테고리 모두에 대한 sample의 불확실성을 추정할 수 있다.
(이 때 known class의 경우 Sc 값이 낮고 Sd값이 높은 경향이 있으며,
unknown class의 경우 Sd값이 낮고 Sc 값이 높은 경향을 띄게 되므로,
이러한 차이를 토대로 두 유형을 구분할 수 있게 되는 것임.)
또한 Diversity를 높일 수 있는 query strategy를 통해서 sample의 information은 높이면서 중복성은 줄이는 방법도 추가했다.
이 매커니즘은 known class로 판별된 것들 중 각 cluster에서 엔트로피 점수가 가장 낮은 샘플 몇 개를 선택하여 label을 지정하는 방법을 택한다.
이처럼 본 논문은 알려진 클래스와 미지의 클래스 분포를 활용한 새로운 오픈셋 Active Learning 접근 방식을 제시한다.
두 가지 엔트로피 점수, query strategy, 그리고 견고한 타겟 모델 학습 전략을 통합함으로써,
EOAL은 실제 산업과 같이 unknown class가 존재하는 환경에 대한 효과적인 방법을 제안한다.
논문이 가지고 있는 contribution은 아래와 같다.
1. EOAL은 known 클래스와 unknown 클래스 분포를 모두 활용해 정보성 높은 샘플을 선택하는 새로운 Open-set Active Learning(AL) 프레임워크를 제안함.
2. 이 과정에서 두 가지 엔트로피 점수를 도입하여 정확도를 높임.
* Closed-set entropy (Sc): binary classifier를 사용해 알려진 클래스에 대한 불확실성을 측정.
* Distance-based entropy (Sd): unknown cluster의 중심과의 거리를 기반으로 unknown class의 불확실성 측정.
3. Diversity-prompting Mechanism: Sc와 Sd를 결합한 점수로 known과 unknown sample을 구분한 후, 레이블이 없는 데이터를 클러스터링해 각 클러스터에서 다양한 샘플을 선택하여 중복을 최소화 함.
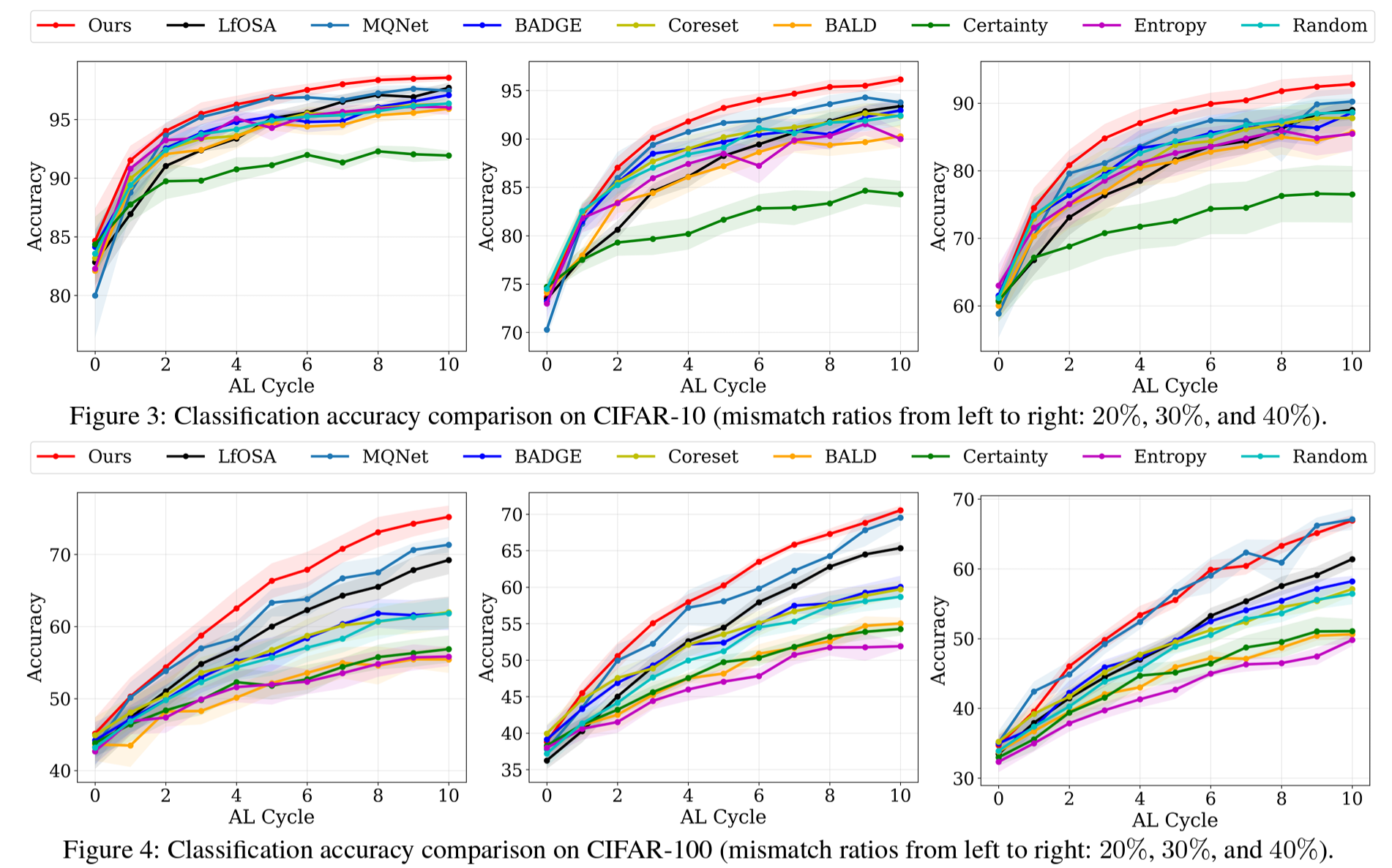
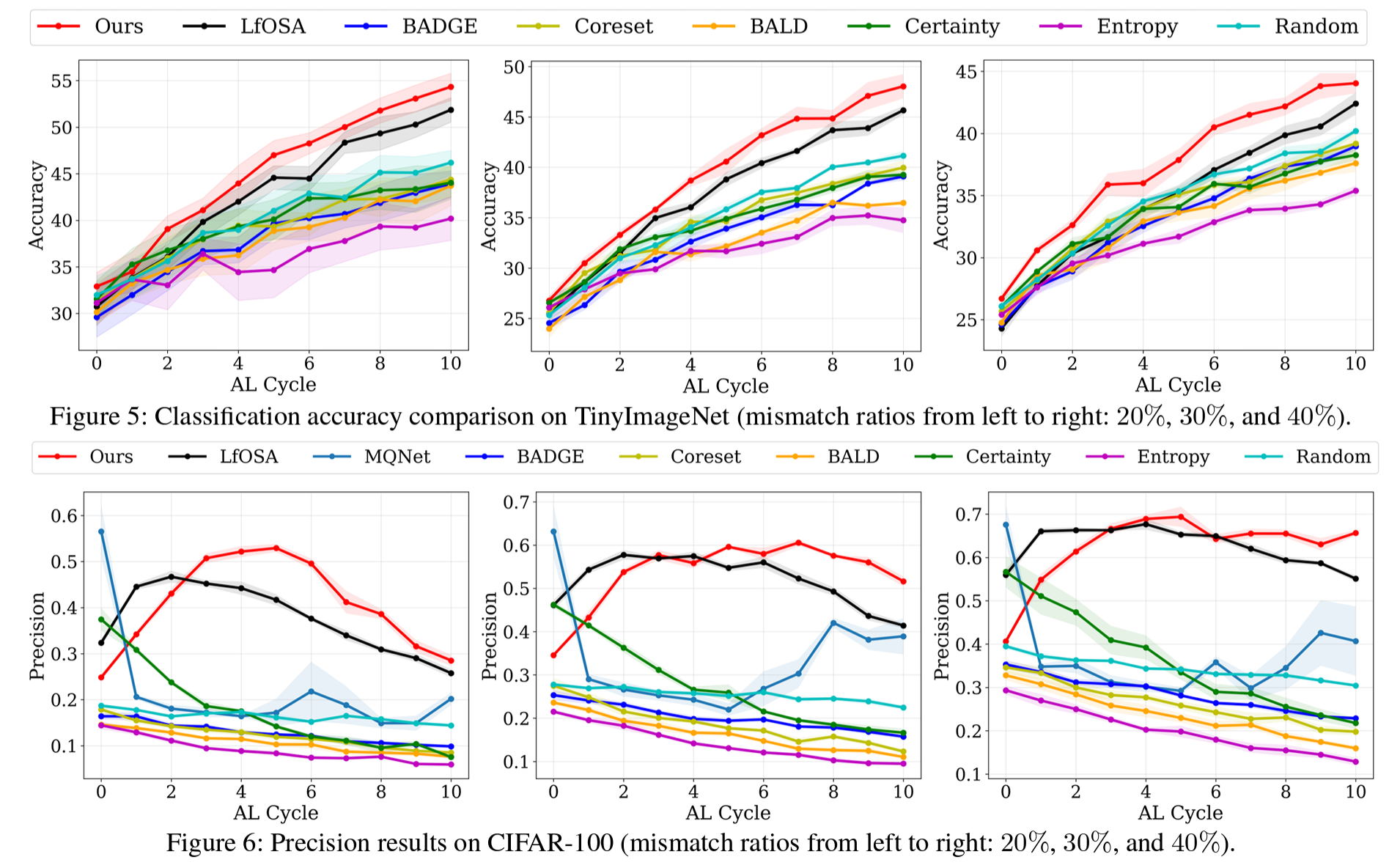
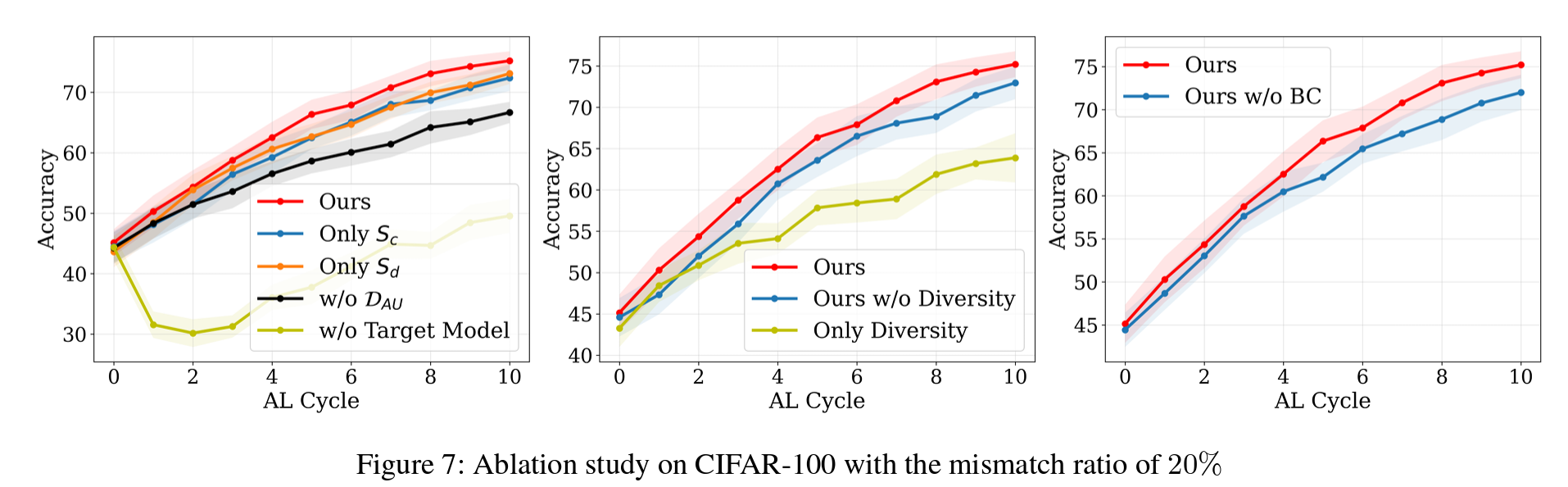
4. CIFAR-10, CIFAR-100, TinyImageNet 데이터셋에서 EOAL이 기존 AL 및 오픈셋 AL 방법들보다 높은 분류 정확도를 기록. 특히 unknown class 비율이 높은 시나리오에서 정보성 높은 샘플을 효과적으로 선택하며 뛰어난 성능을 입증.
Methodology
- K: the number of classes of interest (known classes). We consider active learning for a K-way classification problem in an open-set setting.
- DL: a small labeled dataset of known samples that belong to the label space K
- KU: a large pool of unlabeled data which contains a mixture of known and unknown samples, where unknown samples belong to the label space U, and K∩U=∅
AL cycle이 돌 때마다 query strategy는 unlabeled data에서 label이 있으면 좋을 batch sample들(Xactive)을 선별하게 된다. ($X^{k} \cup X^{u} = X^{active}$, $X^k$ is known queried samples and Xu is unknown queried samples.
그렇게 선별된 Xactive들은 oracle에 의해서 레이블링이 된다.
unknown queried sample에 해당하는 Xu는 open-set class로 분류되어 class '0'으로 레이블링 되며, 'active unknowns'라고 불리게 된다.
(즉, active unknown set인 DAU에는 query strategy에 의해 labeling할 sample로 선정이 되었지만, unknown class에 해당하여 open-set class '0'로 레이블된 sample들이 포함되어 있음)
최종적으로 labeled datset인 DL은 round가 돌기 전에 레이블이 존재하던 셋과 이번 round에서 레이블링된 known queried sample들인 DL∪Xk으로 업데이트 된다.
업데이트가 거듭 될 수록, DL은 target model의 성능을 향상시킬 수 있도록 하는 데에 목적성을 두고 있다.
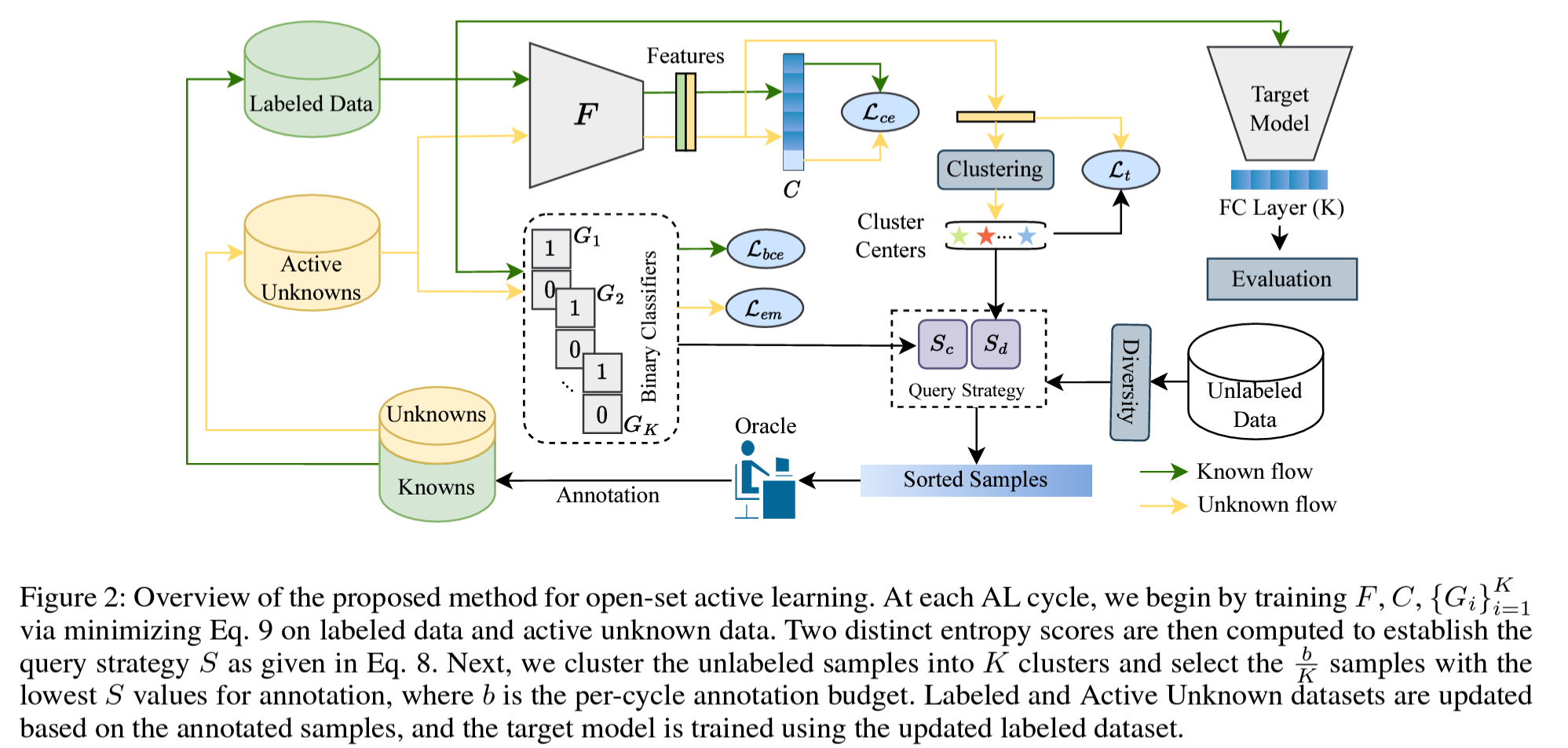
Overview
본 논문에서 제안하는 framework에서는 두 개의 entropy score를 활용하게 되며,
이는 known과 unknown sample들을 효율적으로 분류한 뒤 annotation되면 좋을 최적의 sample들을 선택하는 것을 목표로 하고 있다.
- Closed-set Entropy(Sc): labeled datset인 DL에 대해 학습된 K class-aware binary classifiers (BC)를 통해 계산된다. known class 분포에 대해 주어진 sample의 uncertainty를 계산하는 것임. (known sample일 경우 낮은 값, unknown sample일 경우 높은 값)
- Distance-based Entropy(Sd): CNN 모델로 active unknown set인 DAU에 대해 cluster center들을 결정하고, 이와 주어진 sample간의 거리를 계산하여 unknown class distribution에 대한 uncertainty를 계산함.
Training for Closed-set Entropy Scoring
closed-set entropy 계산을 위해서 총 세 가지가 활용된다.
1) K class-aware binary classifiers Gi
2) CNN-based feature extractor F on DL∪DAU
3) Fully-connected layer C; (K+1)-way classification on DL∪DAU
Training Binary Classifiers (Gi)
i−th known class에 대해서는 positive로, 나머지는 negative로 분류하도록 학습된다.
CNN-based feature extractor인 F로 주어진 이미지에 대해서 feature를 추출한 뒤,
해당 feature를 Gi의 input으로 입력하여 positive인지 negative인지 분류하는 binary cross entropy loss를 통해 학습을 진행하게 된다.
이 때, negative sample들이 학습에 과도한 영향을 끼치는 것을 방지하기 위해서
positive와 decision boundary에 근접한 negative sample들만 활용하여 계산하게 된다.

Closed-set Entropy (Sc)
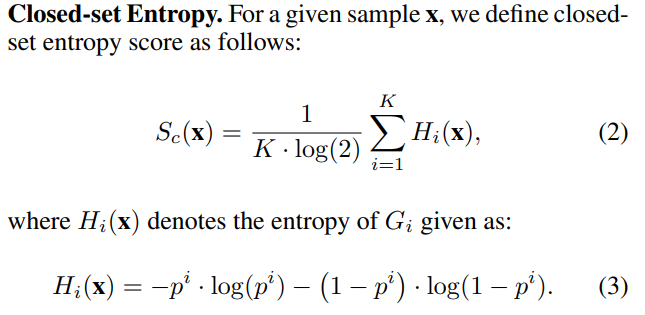
High Sc on Unknown Samples
Sc는 known sample들에 대해서는 낮은 값을, 그리고 unknown sample들에 대해서는 높은 값을 출력해내야 한다.
unknown sample들에 대해서 높은 값을 출력할 수 있도록 DAU에 대해서 Lem을 도입했다.

Training for Distance-based Entropy Scoring
open-set active sampling 환경에서 Sc만 단독으로 사용할 경우 unkwon sample들을 known sample들로 오인할 수 있다.
따라서 knwon sample들을 확실하게 선별해 내기 위해서 distance-based entropy인 Sd를 도입했다.
Distance-based Entropy (Sd)
이를 계산하기 위해서 DAU를 활용하게 된다.
정확한 category label들에 접근할 수 없는 상태에서, FINCH clustering 알고리즘을 통해서 주어진 샘플들의 feature를 clustering하게 된다.
그 후 이를 활용하여 Sd를 계산하게 되는데, 이는 cluster center와 주어진 sample 간의 거리를 계산한 값이다.
DAU으로 cluster center를 계산하였으므로 known class는 high distance 값을, unknown class는 low distance 값을 나타내게 된다.

Low Sd on Unknown Samples
CE loss가 open-set 환경에서 모든 active unknowns들에 대해서 다루고 있는 것이 아니므로, unknwon sample들에 대한 낮은 Sd 값이 보장되는 것은 아닐 수 있다.
따라서 다른 cluster와는 큰 margin을 두면서도 같은 cluster 내에서는 compact하게 clustering될 수 있도록 regularization을 적용했다.

Query Strategy
Query Strategy는 두 엔트로피 값의 차이가 되며, 이를 기반으로 unknwon과 known을 쉽게 구별할 수 있게 된다.
- Known sample: Sc↓, Sd↑ -> 즉 known category와는 가깝고, unknown category 분포와는 멀어짐
- Unknown sample: Sc↑, Sd↓ -> 즉 known category와는 멀고, unknown category 분포와는 가까워짐

또한 annotation할 informative한 sample들을 중복 없이 효율적으로 선별하기 위해 아래와 같은 query strategy를 도입했다.
- unlabeled sample들 중에서 Fully-connected layer C에 의해서 knwon category라고 판별된 것들을 FINCH 알고리즘을 통해 K개로 clustering을 시행함
- 각 cluster에 대해서 S(x) 값이 낮은 하위 b/K개를 선정하여 annotation할 샘플들을 선정하게 됨. (여기서 b는 per-cycle annotation budget임)
이러한 query strategy를 통해서 informative 하면서도 (based on uncertainty score), diverse한 (coming from different cluster)를 선별할 수 있게 되었다.
이는 $S(x) = S_c(x) - S_d(x)$임을 고려해 볼 때, known category의 center에 위치한 sample들을 우선적으로 선택하여 annotation하는 것이 더 효율적이라고 판단한 것 같음.
이는 아마도 본 task에서 해결하고자 하는 것이 open-set 환경에서 known class에 대한 classification 성능을 높이는 것이기 때문에,
known class의 center들을 중심으로 labeling을 진행하는 것이 정확성을 높이는 데에 도움이 될 것이라 생각한 것으로 보임.

Query Strategy
전체 loss는 Active Unknown의 유무에 따라 아래와 같이 구성된다. (첫 cycle에서는 DAU가 존재하지 않기 때문에)

Experiments