
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 논문리뷰
- Prompt란
- deep learning 논문 리뷰
- Stable Diffusion
- ssl
- Prompt Tuning
- Segment Anything
- iclr 2024
- active learning
- cvpr 논문 리뷰
- Data-centric AI
- 자기지도학습
- iclr spotlight
- Self-supervised learning
- Computer Vision
- iclr 논문 리뷰
- CVPR
- Segment Anything 설명
- deep learning
- 논문 리뷰
- Segment Anything 리뷰
- VLM
- ai 최신 논문
- ICLR
- Computer Vision 논문 리뷰
- Meta AI
- contrastive learning
- Data-centric
- Multi-modal
- cvpr 2024
- Today
- Total
Study With Inha
[Paper Review] ICLR 2025 under review, SSLA: A Generalized Attribution Method for Interpreting Self-Supervised Learning without Downstream Task Dependency 논문 리뷰 본문
[Paper Review] ICLR 2025 under review, SSLA: A Generalized Attribution Method for Interpreting Self-Supervised Learning without Downstream Task Dependency 논문 리뷰
강이나 2025. 1. 13. 23:25ICLR 2025 under review,
SSLA: A Generalized Attribution Method for
Interpreting Self-Supervised Learning without Downstream Task Dependency
open review: https://openreview.net/forum?id=2bEjhK2vYp
SSLA: A Generalized Attribution Method for Interpreting...
Self-Supervised Learning (SSL) is a crucial component of unsupervised tasks, enabling the learning of general feature representations without the need for labeled categories. However, our...
openreview.net
Introduction
SSL은 unlabeled 데이터로부터 의미 있는 표현을 추출해내는 방법으로 주목받으며, 영상, 자연어, 음성 등 다양한 도메인에서 탁월한 성능을 입증해왔다.
그러나 SSL을 통한 모델 학습 과정은 기존 supervised learning보다 훨씬 불투명한 측면이 있다.
라벨 정보 없이 학습되는 과정에서 모델이 어떤 특성을 학습하고, 어떤 근거로 결과를 도출하는지 명확히 파악하기 어렵기 때문이다. 이러한 해석력(interpretability) 부족은 모델 신뢰성, 투명성, 그리고 잠재적 편향성 확인 측면에서 문제가 될 수 있다.
- Downstream Task 의존성: 기존 SSL 해석 방법은 Downstream Task 정보를 활용하여 모델을 해석하며, 이는 SSL 모델 자체를 해석하지 않고 Downstream Task의 특성을 포함하게 만듦
- 추가 샘플 의존성: 일부 해석 방법은 현재 샘플 외의 추가 샘플을 필요로 하며, 이는 해석 과정에 불필요한 정보를 도입함
- 특정 아키텍처 종속성: 많은 방법이 Transformer 등의 특정 모델 구조에 의존하며, 다른 구조(CNN 등)에서는 동작하지 않음
이 논문에서는 SSL 과제의 해석가능성 확보를 위해 'attribution' 기반 접근을 제안한다. 이는 모델 출력과 입력 특징 사이의 대응 관계를 명확히 해석함으로써, 모델이 unlabeled 데이터에서 어떤 관찰 포인트나 특징에 의존해 의미를 추출하는지를 정교하게 밝히는 방식이다.
기존 해석 연구들이 주로 특정 downstream task나 특정 모델 구조에 종속적이었다면, 이 연구는 이러한 제한을 넘어서는 보다 일반화된 해석 방법론을 제안하고자 한다.
궁극적으로 SSL이 “어떤 불변적 특징”을 포착하는가를 기반으로 해석 방법을 설계함으로써, 다양한 모델 아키텍처나 downstream task 없이도 안정적으로 SSL의 내부 작동 원리를 파악할 수 있게 된다.
이 논문은 ***“label이 없는 방대한 데이터 속에서 모델이 무엇을, 어떻게 학습하고 있는가?”***라는 질문에 답하기 위한 새로운 해석 프레임워크를 제시한다.
이는 향후 SSL 연구가 더욱 투명하고 신뢰성 있는 모델 개발로 이어질 수 있는 토대를 제공한다.
Method
아래는 논문에서 제시한 Self-Supervised Learning Attribution(SSLA) 기법을 설계하기 전에 충족해야 하는 세 가지 Prerequisite에 대한 설명이다.
- Prerequisite 1: The interpretation of SSL should not introduce information from downstream tasks.
- SSL 모델을 해석할 때, 일반적으로 SSL 모델 fθ에 이어 붙이는 downstream task model gϕ나 그 파라미터 ϕ를 이용하지 않아야 한다는 점을 강조
- 이는 downstream task에서 얻은 추가적인 정보가 모델 해석 과정에 섞이는 것을 방지하기 위함
- 만약 downstream task 정보가 유입된다면, 결과적으로 해석 대상이 SSL 그 자체의 representation 능력이 아니라 downstream task로 인한 변형을 반영한 모델 상태가 됨
- 오직 SSL로 학습한 encoder fθ가 본래의 unlabeled data를 통해 어떤 특징을 추출하고 있는지 “순수하게” 해석하기 위해서는 downstream task 관련 요소를 배제해야 한다.
- SSL 모델을 해석할 때, 일반적으로 SSL 모델 fθ에 이어 붙이는 downstream task model gϕ나 그 파라미터 ϕ를 이용하지 않아야 한다는 점을 강조
- Prerequisite 2: The interpretation process should not introduce samples other than the current sample.
- 해석할 때, 현재 분석 대상인 sample x 이외에 추가적인 다른 sample을 도입하지 않아야 함
- 다른 데이터 포인트를 불러와 해석에 활용하면, 그 과정에서 sample 간의 상호작용 정보가 섞여 들어가게 되고, 이는 “모델이 현재 sample을 통해 어떤 특징을 학습했는가”라는 관점보다 “샘플 간 관계”를 반영하는 결과로 이어질 수 있기 때문
- 따라서 해석은 오직 주어진 single input에만 초점을 맞추고, 그 input이 모델 내에서 어떤 식으로 처리되는지를 밝혀내는 방식으로 진행되어야 함
- Prerequisite 3: The interpretation process should not be restricted to specific model architectures.
- SSL 알고리즘은 encoder 구조에 대한 구체적인 제약 없이 적용 가능하다는 점이 하나의 강점이다. 그러므로 해석 기법 또한 특정 모델 아키텍처(예: Transformers, CNN 등)에 종속적이지 않게 설계되어야 함
- 예를 들어, self-attention 기반 해석 방식만을 사용한다면, CNN 기반 encoder를 사용하는 SSL 모델에서는 해석 불가능하거나 의미가 달라질 수 있음
- 따라서 SSL을 해석하는 attribution 기법은 모델 구조에 대한 추상화를 유지하며, 다양한 아키텍처에 두루 적용 가능한 일반적인 방법을 제안하는 것이 중요함
→ 이는 SSL 모델이 unlabeled 데이터로부터 얻은 내재적 표현 능력을 왜곡 없이, 그리고 일반화 가능한 방식으로 해석하기 위한 토대임 - SSL 알고리즘은 encoder 구조에 대한 구체적인 제약 없이 적용 가능하다는 점이 하나의 강점이다. 그러므로 해석 기법 또한 특정 모델 아키텍처(예: Transformers, CNN 등)에 종속적이지 않게 설계되어야 함
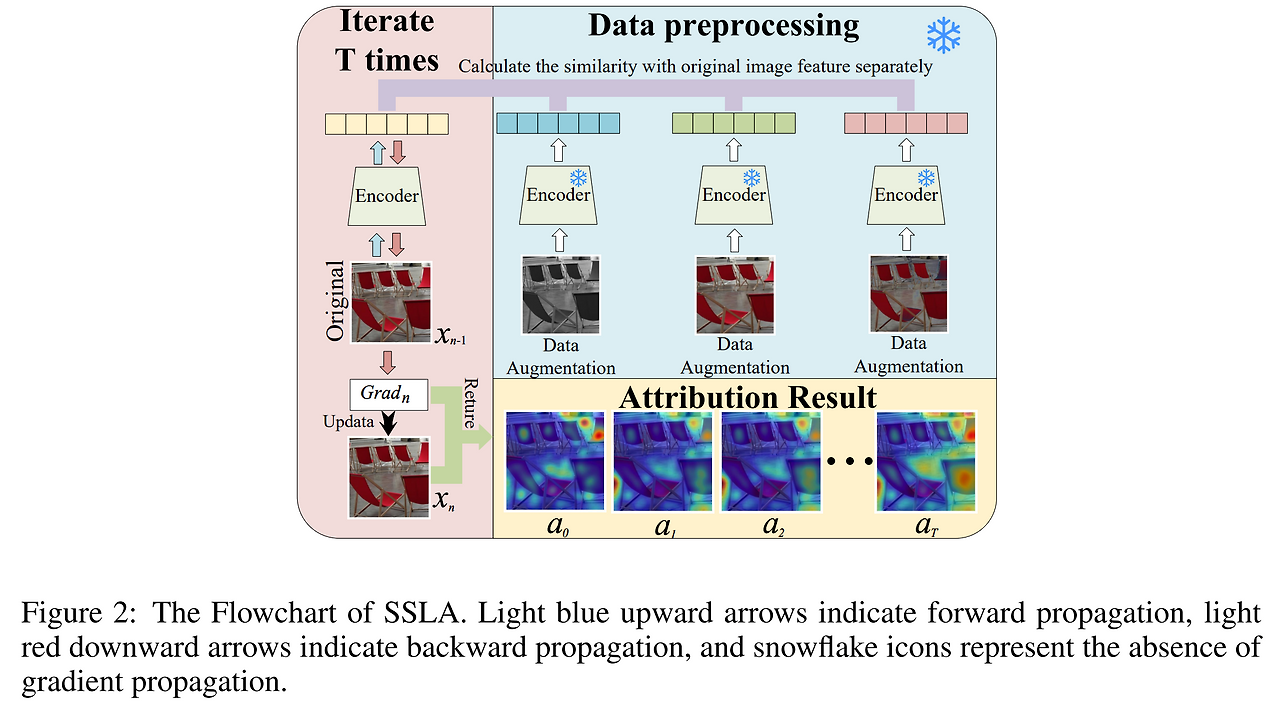
Self-supervised Learning Attribution (SSLA)

SSLA는 SSL 모델이 "불변적인 특징(invariant features)"을 어떻게 포착하는지를 해석하기 위한 Attribution 방법론이다. 기본 전제는 SSL 모델은 주어진 입력 샘플에 다양한 augmentation을 적용하더라도 의미가 유지되는 특징을 추출하려고 한다는 점이다. SSLA는 이 원리에 기반하여, 입력 샘플의 각 feature가 모델이 불변적 표현을 형성하는 데 얼마나 기여하는지를 정량화한다.
- 불변성(Invariance) 추출:즉, 변환 전후로 추출된 feature vector가 높은 cosine similarity를 가지면, 해당 모델이 해당 샘플로부터 의미 있는 invariant features을 잘 뽑아냈다고 볼 수 있다.
SSL은 레이블 없는 데이터로부터 의미 있는 표현을 학습하기 위해, 동일한 입력에 대해 다양한 변환(*e.g. color jitter, random resized crop, gaussian blur)*을 적용하고, 변환 후의 feature representation끼리 서로 유사하게 만들도록 학습한다. - Cosine similarity를 활용한 평가 함수 $S(x, fθ, Z)$:
- augmented set Z는 x에 대해 랜덤하게 선택된 augmentations의 결과 모음.
- S(x, fθ, Z) = E_z∈Z[cos(fθ(x), z)]로 정의되며, 이 값이 클수록 모델이 x에 대해 불변적인 특징을 잘 학습했다고 볼 수 있다.
- SSLA는 입력 샘플 x와 augmented set Z를 가지고, 모델 fθ가 추출한 original sample의 feature fθ(x)와 augmented sample들의 feature fθ(τ(x)) 간의 average cosine similarity를 측정하는 함수를 정의한다.
- Downstream task나 추가 샘플을 사용하지 않는 새로운 지표:SSLA는 코사인 유사도를 통해 오직 원샘플(single sample) 기준으로, 그리고 모델의 구조와 무관하게 불변적 특징 학습 정도를 측정하는 새로운 지표를 고안했다.
- 이렇게 함으로써 Downstream task나 외부 샘플 정보 없이도 모델 해석이 가능해진다.
- 기존 해석 방법들은 downstream task의 loss나 추가 샘플을 해석에 활용했으나, 이는 Prerequisites에서 언급한 제한 사항을 위반할 수 있다.
Attribution 방법의 수학적 형식화:
- SSLA는 Sensitivity와 Implementation Invariance라는 Attribution 기법의 두 축을 만족하도록 설계되었다.
- 핵심 아이디어는 입력 샘플 x의 각 특징을 미세하게 변화시키며, 이러한 변화를 통해 S(x, fθ, Z)가 얼마나 민감하게 변하는지를 관찰하는 것이다.
- 특정 feature를 약간 변경했을 때 S(x, fθ, Z)에 큰 변화가 일어나면, 그 feature는 invariant features 형성에 있어 중요한 역할을 하는 것으로 해석한다.
- S(x, fθ, Z) 함수에 대해, x를 미세하게 변화시킬 때( xᵐ → xᵐ+1 ), 1차 테일러 전개(Taylor expansion)를 통해 변화량을 근사할 수 있다. 여기서 $O(∥x_j−x_{j−1}∥^2)$는 고차항으로, 아주 작은 변화에 대해 무시 가능하다고 본다.
- 위 식에서, S를 가장 빠르게 감소시키기 위해서는 (x_j - x_{j-1}) 방향이 − ∂S(x_{j-1}, f_θ, Z)/∂x_{j-1} 와 동일해야 한다. 즉, gradient에 반대 방향으로 아주 작은 이동을 할 때 S가 가장 빠르게 줄어든다. 이는 gradient descent과 동일한 직관이다.이 과정을 gradient 기반으로 표현하면, S(x, fθ, Z)에 대한 x의 gradient를 활용할 수 있다. 기울기가 큰 feature일수록 해당 feature가 S에 큰 기여를 하는 것으로 해석할 수 있다.샘플 x의 각 feature를 변화시킬 때, S(x, fθ, Z)를 가장 빠르게 감소시키는 변화 방향이 무엇인지 증명한다. 여기서 S(x, fθ, Z)는 본문에서 정의한 SSL 모델에 대한 평가 함수(cosine similarity를 이용해 모델이 invariant feature들을 잘 학습했는지 측정)이다.
- 즉 어떤 feature를 변경할 때, S값을 가장 민감하고 빠르게 줄이는 변화 방향은 S의 기울기에 반대되는 방향임을 보여준다.
- SSLA의 Attribution 결과 합은 실제 모델의 S 변화량과 대응하므로, 입력 특징 변화가 모델 반응에 어떻게 기여하는지를 정량적으로 보여준다.
- 이는 SSLA가 단순한 heuristic이 아니라 Sensitivity Axiom에 부합한다는 점을 강조한다.
SSLA 알고리즘 개요:
- 원본 샘플 x와 다양한 변환을 적용한 결과 집합 Z에 대해, fθ를 이용해 특징을 추출한다.
- 원본 특징과 변환된 특징 간 cosine similarity S(x, fθ, Z)를 계산한다.
- x의 각 feature들을 조금씩 변화시키면서, S(x, fθ, Z)가 어떻게 변화하는지를 관찰한다. 이때 gradient 정보를 사용한다.
- 기울기 누적을 통해, 최종적으로 각 input feature dimension별로 기여도를 나타내는 Attribution 결과 A(x)를 산출한다.
- A(x)의 i번째 성분 A_i(x)은 x_i가 invariant representation 형성에 기여하는 정도를 나타낸다.
- 이 과정에서 Downstream task 모델이나 다른 샘플 없이, 그리고 특정 모델 구조에 의존하지 않는 일반적인 해석 결과를 얻게 된다.

SSLA는 입력 샘플의 각 특징이 자기지도학습 모델이 형성한 불변적 표현에 얼마나 중요한지를 보여주는 해석 기법이다. 이는 Prerequisites를 충족시킨 채, 오직 invariant를 기반으로 모델의 내부 작동 원리를 투명하게 들여다볼 수 있는 새로운 Attribution 접근법이다.
의문점
- SSLA가 중요한 feature를 식별하기 위해 similarity 결과를 사용하는 것이 실제로 모델이 "진짜 의미론적으로 중요한" feature를 정확히 이해했는지를 보장하지 않는 것 아닌가?
- 이미 train된 SSL 모델이 추출한 feature를 기반으로 invariant를 판단한 뒤, 이를 masking하고 attack한 것을 다시 SSL 모델의 결과로 cosine similarity를 계산한 것이 유효한 것일지?
- SSLA가 단순히 모델의 output 변화에 기여하는 feature를 식별할 뿐, 이러한 feature가 인간의 직관이나 의미론적으로 중요한지 여부와는 반드시 일치하지 않을 수 있음
- (minor) Iteration을 여러 번 하면서 gradient를 계산하면 computational cost가 클 것 같긴 함



