
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- deep learning 논문 리뷰
- cvpr 2024
- Data-centric AI
- Computer Vision
- 논문리뷰
- Segment Anything 리뷰
- CVPR
- ai 최신 논문
- Segment Anything
- iclr spotlight
- ssl
- VLM
- deep learning
- Prompt란
- active learning
- Prompt Tuning
- Meta AI
- Data-centric
- Self-supervised learning
- contrastive learning
- Computer Vision 논문 리뷰
- Stable Diffusion
- iclr 2024
- 자기지도학습
- Multi-modal
- cvpr 논문 리뷰
- 논문 리뷰
- iclr 논문 리뷰
- Segment Anything 설명
- ICLR
Archives
- Today
- Total
Study With Inha
[Paper Review] ICLR 2024 Spotlight, Entropy is not Enough for Test-time Adaptation: From the Perspective of Disentangled Factors 논문 리뷰 본문
Paper Review
[Paper Review] ICLR 2024 Spotlight, Entropy is not Enough for Test-time Adaptation: From the Perspective of Disentangled Factors 논문 리뷰
강이나 2025. 1. 5. 20:00Entropy is not Enough for Test-time Adaptation:
From the Perspective of Disentangled Factors
ICLR 2024, Spotlight
- 논문 링크: https://arxiv.org/abs/2403.07366
- github 링크: https://github.com/Jhyun17/DeYO
- 프로젝트 페이지: https://whitesnowdrop.github.io/DeYO
SOCIAL MEDIA TITLE TAG
SOCIAL MEDIA DESCRIPTION TAG TAG
whitesnowdrop.github.io
Introduction
잘 학습된 모델이라 하더라도 distribution shift가 일어난 새로운 환경에서에서 robustness가 부족한 모습을 보였고, 이를 해결하기 위해 대표적으로 아래와 같은 연구 분야를 꼽을 수 있음.
- Domain Generalization: 모델을 arbitrary distribution shift에 robust하게 학습.
- Unsupervised Domain Adaptation (UDA): label 없는 target domain에서 domain-invariant 정보를 학습.
- Test-Time Adaptation (TTA): 테스트 시 발생하는 distribution shift에 대응, minimal overhead로 실시간 적응 가능.
그 중 TTA (Test-Time Adaptation)는 딥러닝 모델이 학습 후 테스트 환경에서 발생하는 distribution shift에 적응하도록 설계하는 방법임.
- 학습된 모델이 테스트 데이터에 대해 즉각적으로(online) 적응할 수 있도록, 테스트 데이터 자체를 사용해 모델 파라미터를 fine-tuning하는 과정.
- 학습 데이터와 테스트 데이터 간 분포가 달라질 경우, 기존 모델이 성능 저하를 겪는데, 이를 완화하기 위해 TTA를 사용.
- 장점
- No Labels: 테스트 데이터에는 정답 라벨이 제공되지 않음.
- 실시간성(Online): 테스트 데이터가 도착하자마자 바로 adaptation이 적용됨.
- 저비용: 학습 시와 비교해 추가 데이터나 리소스가 거의 필요하지 않음.
- 한계
- 테스트 데이터가 제한적으로 제공되기 때문에 전체 분포를 정확히 파악하기 어려움.
- 잘못된 샘플(예: spurious correlation)이 모델 업데이트에 포함되면 오류가 누적될 수 있음.
이에 대해 본 논문에서 지적한 기존 TTA 연구들의 문제점은 아래와 같다.
- Problem Thesis
- TTA는 test dataset 전체에 동시 접근 불가 → 전체 분포 추정 어려움.
- 잘못된 샘플 업데이트 시 error accumulation 발생.
- 기존 방법은 model output의 entropy를 confidence metric으로 사용해 신뢰할 수 있는 샘플을 식별하려 했으나, 다양한 distribution shift 상황에서 신뢰성 낮음.
- Motivation:
- Entropy-Based Sample Selection:
- 기존 TTA 방법은 low entropy를 신뢰할 수 있는 샘플로 간주.
- Low entropy는 모델 output이 training data distribution과 유사함을 나타냄.
- 하지만 spurious correlation shift가 있는 상황에서는 entropy 기반 접근이 신뢰할 수 없음.
- Spurious Correlation Shift:
- 모델이 spurious features(예: background, context)와 같은 불필요한 정보를 학습하면 distribution shift에서 성능 저하.
- e.g. butterfly 이미지에서 꽃과 함께 나타나는 경우, 꽃이 없는 butterfly 이미지를 오분류하는 문제 발생.
- 실험적 관찰:
- Waterbirds 데이터셋에서 entropy가 가장 낮은 구간 (1st quartile) 내 샘플들의 prediction accuracy가 낮음.
- Grad-CAM을 사용한 시각화에서, 잘못된 prediction의 경우 background(spurious feature)에 초점.

- Theoretical Observation:
- Spurious feature에 의존하는 모델은 input distribution shift 상황에서 신뢰할 수 없는 결과를 초래.
- Entropy는 모델이 focus하는 feature가 spurious인지 아닌지 구별하지 못함.
- 즉, 중요한 CPR factor보다 TRAP factor에 치중된 경우가 많음.
- TRAin-time only Positively correlated with label (TRAP) factors: (e.g., background, weather)
- Commonly Positively-coRrelated with label (CPR) factors (e.g., structure, shape)
- 따라서 Spurious correlation shift 환경에서는 entropy만으로는 신뢰할 수 있는 샘플을 식별하기 어려우므로 더 robust한 confidence metric 필요함.
- Entropy-Based Sample Selection:
이에, 본 논문에서는 새로운 TTA 방법인 Destroy Your Object (DeYO) 제안한다.
- Pseudo-Label Probability Difference (PLPD)라는 새로운 confidence metric 사용.
- PLPD는 object-destructive transformation 전후의 prediction 차이를 측정해 모델이 shape 정보에 얼마나 의존하는지 평가.
Methodology
1. Sample Selection
- 기존 entropy-based 샘플 선택은 spurious correlation shift 상황에서 TRAP factors(배경 등)에 의존, 신뢰도 저하됨.
- Sample Selection
- Entropy와 PLPD를 결합해 spurious feature 의존 샘플 제외.
- CPR factors(특히 shape)에 기반한 신뢰도 높은 샘플만 업데이트에 사용.
- 추가 forward pass만 필요해 overhead 거의 없음.
- Robust한 adaptation을 위해 CPR factors(예: shape 정보)를 반영하는 새로운 샘플 선택 전략 필요.
- PLPD(Pseudo-Label Probability Difference) 정의:
- $PLPD_θ(x,x^{′})=(p_θ(x)−p_θ(x^{′}))⋅\hat{y}$
- Patch-shuffling 등 object-destructive transformation을 적용한 후, 예측 변화량 측정.
- PLPD 값이 클수록 CPR factors(특히 shape 정보)에 더 크게 의존.
- $x$: 원본 이미지, $x′$: 변환된 이미지 (patch-shuffling 등 사용).
- $\hat{y}$: pseudo-label.
- Sample Selection Criterion:
- Entropy와 PLPD를 모두 고려해 신뢰할 수 있는 샘플 선택.
- Object-Destructive Transformations:
- 다양한 변환 방식 사용:
- Pixel-shuffling: 이미지의 평균 색상 유지, object와 background 구별 불가.
- Patch-shuffling: object의 shape 파괴, 로컬 정보 보존.
- Center occlusion: 배경 유지, object의 일부 제거.
- 실험 결과, Patch-shuffling이 CPR factors(shape 정보)에만 초점을 맞춰 PLPD 계산에 가장 효과적임.
- 다양한 변환 방식 사용:
2. Sample Weighting
- Sample selection 이후, 선택된 샘플들 간 신뢰도 차이를 반영하여 각 샘플의 모델 업데이트 기여도를 조정
- Sample Weighting Function:
- Entropy-based Weighting: Entropy 값이 낮을수록 더 높은 신뢰도를 부여.
- PLPD-based Weighting: PLPD 값이 클수록 CPR factors에 의존하는 샘플로 간주, 더 높은 가중치 부여.
- 두 가중치 요소를 결합하여 신뢰도 높은 샘플에 더 큰 업데이트 기여도 부여.
- Sample Weighting 역할:
- 선택된 샘플 중에서도 entropy와 PLPD를 기반으로 가장 신뢰도 높은 샘플이 업데이트에 더 큰 영향을 미치도록 조정.
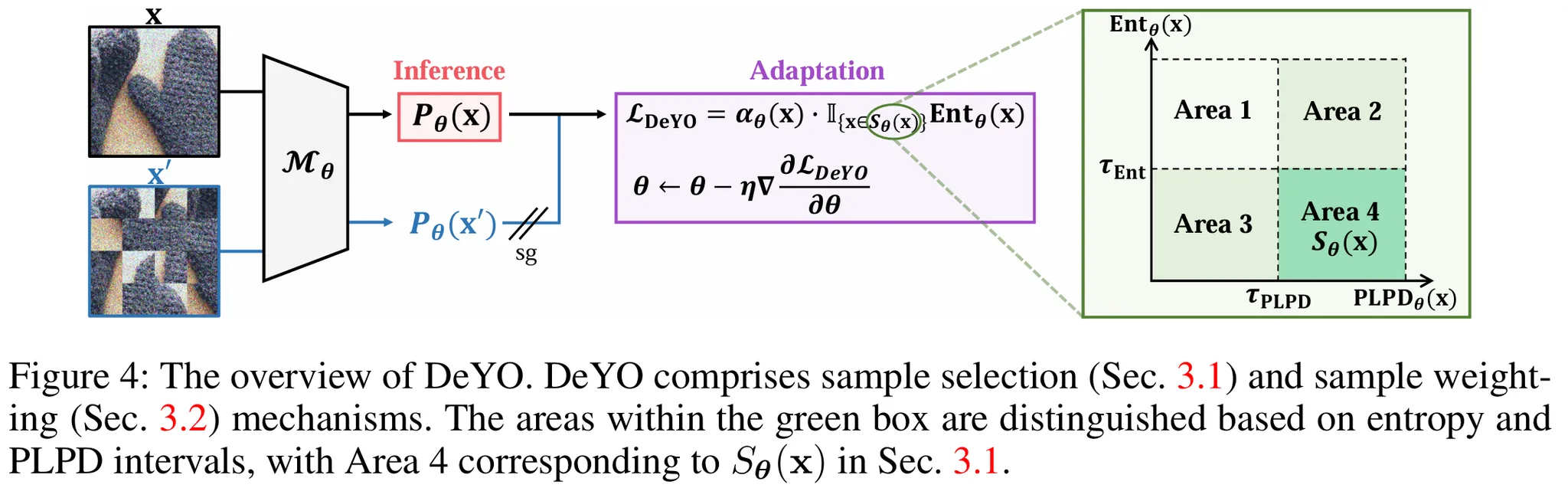
3. DeYO의 전체 구조
- Inference 단계: 입력 x와 patch shuffling으로 변환된 입력 x′로 PLPD 계산.
- Sample Selection: Entropy와 PLPD 기준을 충족하는 샘플 Sθ(x) 선택 (Area 4).
- Sample Weighting:
- Area 4의 샘플에 대해 $α_θ(x)$를 계산.
- PLPD와 Entropy 값을 기반으로 weighting 수행.
- Sample 분포:
- Area 1: High Entropy, Low PLPD
- Entropy 값이 높아 모델이 해당 샘플에 대해 불확실.
- PLPD 값이 낮아 CPR factors(예: shape 정보)에 의존하지 않음.
- 신뢰도 낮음 → 제외.
- Area 2: Low Entropy, Low PLPD
- Entropy 값은 낮아 불확실성은 적지만, PLPD 값이 낮아 모델이 TRAP factors(예: 배경)에 의존.
- CPR factors가 부족 → 업데이트 시 오류 누적 가능.
- 제외.
- Area 3: High Entropy, High PLPD
- PLPD 값이 높아 CPR factors 의존도는 높지만, Entropy 값이 높아 모델 불확실성 큼.
- 불확실한 샘플 포함 시 업데이트에 오류 가능성 증가.
- 제외.
- Area 4: Low Entropy, High PLPD → 모델이 확신을 가지고 예측하면서 CPR factors에 기반한 샘플.
- Entropy 값이 낮아 모델의 불확실성이 적음.
- PLPD 값이 높아 CPR factors에 의존, spurious feature(TRAP factors) 의존 가능성 낮음.
- 신뢰도 높음 → 업데이트에 사용.
- Area 1: High Entropy, Low PLPD
Experiments
Experimental Setting
- 다양한 benchmark와 현실적인 test scenario를 활용하여 TTA 방법 평가.
- ResNet과 Vision Transformer 모델을 사용해 normalization 방식 차이에 따른 성능 비교.
Benchmarks
- ImageNet-C:
- 15 corruption types, 각 5단계 severity level.
- TTA 성능 평가를 위한 표준 benchmark.
- ColoredMNIST:
- Extreme spurious correlation shift 포함.
- 숫자 색상과 클래스 간 강한 상관관계 → robust한 TTA 필요.
- WaterBirds:
- Background와 class label 간 spurious correlation.
- ImageNet-R:
- 다양한 스타일 도메인 (cartoon, sketch 등)으로 구성된 distribution shift.
- VisDA-2021:
- Domain 스타일 변화와 같은 challenging wild scenarios 포함.
Test Scenario
- Mild Scenario:
- 단일 corruption type을 포함한 단순 환경.
- Wild Scenarios (3가지 유형):
- Dynamic Label Shifts:Test 데이터의 label 분포가 동적으로 변화.
- Batch Size 1:Single sample로 TTA 수행.
- Mixed Shifts:여러 corruption types가 혼합된 상황.
- Biased Scenarios:
- ColoredMNIST 및 WaterBirds에서 spurious correlation shift가 극단적으로 존재.
Models
- ResNet Variants:
- ResNet-18-BN, ResNet-50-BN (Batch Normalization 기반).
- ResNet-50-GN (Group Normalization 기반).
- VitBase-LN:
- Vision Transformer 기반 모델.
- Layer Normalization 사용.
Main Results
1. Mild Scenario (ImageNet-C)

- DeYO가 기존 방법들(Tent, EATA 등) 대비 모든 corruption type에서 consistent하게 더 높은 accuracy를 보임.
- Severity Level 5에서 평균 48.6%로 기존 최고 성능(EATA 47.8%) 대비 0.8% 향상.
- Noise, Blur, Weather, Digital과 같은 다양한 corruption에서 DeYO가 최고의 성능 기록.
- DeYO의 PLPD와 entropy 조합이 mild scenario에서도 효과적임.
2. Biased Scenario (ColoredMNIST & WaterBirds)

- DeYO는 기존 방법 대비 Biased Scenario에서 worst-group accuracy를 크게 향상.
- ColoredMNIST: Worst-group accuracy에서 67.39% 기록 (Tent: 9.80%, SENTRY: 15.78%).
- WaterBirds: Worst-group accuracy 73.92%로 기존 최고 성능(SENTRY: 60.90%) 대비 큰 차이.
- Spurious correlation shift에 취약한 기존 TTA 방법과 달리, DeYO는 PLPD 기반 filtering으로 robust한 성능 발휘.
3. Wild Scenario (Mixed Shifts, Dynamic Label Shifts, Batch Size 1)

- DeYO는 unpredictable한 wild scenario에서도 높은 성능.
- Mixed Shifts:
- ResNet-50-GN: Level 5에서 38.6%, Level 3에서 59.2%로 기존 최고 성능(EATA: 38.2%, 56.1%) 대비 향상.
- VitBase-LN: Level 5에서 59.4%로 기존 최고(SAR: 57.1%) 대비 우수.
- Dynamic Label Shifts: ResNet-50-GN에서 평균 43.9%, VitBase-LN에서 평균 62.3%로 최고 성능.
- Batch Size 1: ResNet-50-GN에서 평균 44.4%, VitBase-LN에서 평균 64.4%로 모든 baseline을 능가.
- DeYO는 mild뿐 아니라 wild scenario에서도 consistent한 우월성 보임.

Role and Effect of PLPD
- 기존 entropy 기반 신뢰도 metric이 spurious correlation shift 상황에서 한계를 보임.
- PLPD는 CPR factors(특히 shape 정보)에 기반한 신뢰도 평가 가능.
- PLPD를 활용하면 spurious feature 의존 샘플을 효과적으로 제거 가능.
1. WaterBirds Benchmark: Risk-Coverage Curve

- Risk: prediction error rate, Coverage: 선택된 샘플 비율.
- Entropy 기반 filtering은 Risk가 높고 AURC 값도 큼 → 신뢰도 낮음.
- PLPD 기반 filtering은 Risk가 낮고 AURC도 감소 → 신뢰도 높음.
- Patch-shuffling을 활용한 PLPD가 가장 우수한 성능.
2. ImageNet-C Benchmark: Area별 Accuracy 분석

- Area 1, 2, 3: Entropy 또는 PLPD 값 중 하나만 기준 충족.
- Area 4: Low Entropy + High PLPD → 신뢰할 수 있는 샘플.
- Area 4 (Low Entropy + High PLPD) 샘플의 accuracy가 가장 높음(49.1%).
- 같은 entropy 레벨에서도 PLPD가 높은 샘플이 더 높은 accuracy를 기록 → PLPD의 유효성 입증.
결론
- PLPD는 CPR factors에 의존하는 샘플을 효과적으로 식별해 spurious feature 의존성을 줄임.
- Entropy 기반 filtering만으로는 부족하며, PLPD를 결합했을 때 모델의 robustness가 향상.
- Figure 5와 6은 PLPD가 entropy의 한계를 보완하고 더 높은 신뢰도를 제공함을 시각적으로 입증.
Hyperparameter and Ablation Studies on DeYO
1. Hyperparameter Sensitivity

(1) Transformation Methods 비교
- Patch-shuffling, Pixel-shuffling, Center Occlusion 비교.
- Patch-shuffling이 가장 높은 성능 (48.7%) → object shape 정보만 제거, 다른 요소에 영향을 최소화.
- Pixel-shuffling과 Center Occlusion은 성능 낮음 → shape 이외의 정보도 영향을 받기 때문.
(2) Number of Patches
- 224×224 이미지를 N×N patch로 나눔 (e.g., 2×2, 3×3 등).
- 4×4 patch에서 최고 성능 (48.7%).
- 3×3 이상부터 성능이 꾸준히 상승, 너무 작은 patch는 성능 감소.
(3) PLPD Threshold
- $\tau_{PLPD}$ 값을 조정하며 성능 평가.
- $\tau_{PLPD} \in [0.2, 0.3]$에서 가장 높은 성능 (48.7%).
- Threshold가 너무 높으면 신뢰할 샘플이 줄어들어 성능 감소.
2. Ablation Studies

- 샘플 선택 $(S_θ(x))$과 가중치 계산 $(α_θ(x))$에서 각각 Entropy와 PLPD 사용 여부 평가.
- PLPD만 사용해도 Entropy만 사용할 때보다 성능 우수.
- Entropy와 PLPD를 결합했을 때 최고의 성능 (48.6%).
- 특히 Biased Scenario (WaterBirds)에서는 PLPD만 사용한 경우도 우수 → Entropy 신뢰도 낮은 환경에서 PLPD의 중요성 강조.
반응형
'Paper Review' 카테고리의 다른 글
'Paper Review' Related Articles
more




Comments